Architecture
The high level architecture of RE.VE.N.GE. is divided into three blocks: the news sources, the news users (sinks) and the dispatching system, which is composed by several peers. Every communication takes place by sending messages on message spaces called "topics". Refer to the image below for a scheme of RE.VE.N.GE. architecture. Every node has a 128 bit unique ID, created hashing with MD5 some random node dependent data.
When a new source wants to register on the dispatching system, it sends a message to it, specifying the QoS it wants to use (maximum and minimum news rate, reliable or unreliable connection, minimum and maximum delay for a send and so on). One of the properties of a source is its priority, which is inherited by every news it sends: the dispatching system will dispatch first the news with an higher priority and, if the network layer supports it, will set higher QoS flags.
Symmetrically when a sink wants to receive news, it register itself on the dispatching system, specifying the desired QoS.
When the dispatching system receives a news, classified under one or more topics, saves it and sends it to sinks that are registered for those topics. In order to balance communication costs between routing (copies) and sinks, our system use DDS partitions by assigning each sink to one partition only; for each partition, one copy is responsible of it and sends messages to all sinks associated with it.

In depth
News sources and sinks
Most of the complexity of RE.VE.N.GE. is hidden in the dispatch system, so news sources and sinks are fairly simple.
The first thing that a news source has to do is register to the dispatching system by using the standard DDS discovery negotiation protocol. In this phase, each source may specify:
- priority
- Declares the self-proclaimed priority of this source. At the current state RE.VE.N.GE. doesn't enforce any kind of check on this field, and assumes that the node tells the truth. However adding a form of check would be quite trivial.
- unit
- Declares the time unit the following two fields refer to.
- minNewsPTU
- Declares the minimum number of news per time unit that the news source will send. The dispatching system checks whether this service level is met or not, and in such a case emits an appropriate signal.
- maxNewsPTU
- Declares the maximum number per time unit that the source will send. Unlike the previous value, the dispatching system enforces this rate and does not forward news on excess until the current time unit expires.
- reliability
- Declares that the source wants to send news reliably. This is implemented using DDS acknowledgment protocol.
After registering to the dispatching system a source can send news by using multicast whenever possible, or point-to-point connections otherwise.
Contrariwise, a sink that wants to receive news has to send a specific JOIN registration message to request the partition on which to receive news and, optionally to request old messages.
Most of the QoS policy that a sink can request have the same meaning of the ones used by sources. The different are:
- maxDeliTime
- This sink accepts only news that have been queued in the dispatch system for at most maxDeliTime seconds.
- minDeliTime
- Minimum time that the news must spend in the dispatch system.
- exclusive
- Each element of this array is associated to the corresponding topic in the topic array. If there are one or more sinks that flagged a topic as exclusive, all the news of that topic will be dispatched only to them.
A sink can then listen on the news dispatching topic, by selecting the given partition sent by the system.
Dispatching system
RE.VE.N.GE. dispatch system is fault tolerant: its functions are provided by a set of nodes - called "peers" - realizing a virtual synchrony model with active replication.
When a news source registers to the dispatching system all the peers create the necessary data readers to receive the news. The approach is different for sinks. Each domain is divided among peers by using DDS partitions: when a sink registers to the system the peer whose partition is choosen based on a statistical load sharing function will be in charge of sending news to it. This approach allows for dinamic load sharing by adding/removing partition at runtime.
Each peer serves a certain number of sinks, and manages their queues of pending news guaranteeing the agreed QoS using an intelligent queue. Each other peer of the dispatch system has a copy of its internal state, managed with lightweight data structures called "partition map". To keep the copies updated each time that a node delivers a news to a sink it sends also a lazy update message to all the peers:
struct QueueUpdate{
string<32> newsguid;
string<32> peerguid;
string<32> sourceguid;
string<32> sinkguid;
};
Using this "coordinates" each peer can remove from its simple queues the news just dispatched by the sending peer. Therefore each peer is an active copy of every other peer.
Peers confirm periodically their presence by sending an heartbeat, therefore peers can sense if a peer crashes. In this case the remaining peers reorganize and divide again the space of partitions: In case of failure of one of the copies, it is sufficient that another copy take temporarily charge of the partition of the entity that is not responding.
The replicated architecture is totally dynamic, so it's possible to add and remove peers without stopping the system and without losing any news memorized in the dispatch system. When a peer wants to join the dispatch system it asks to the already present system the necessary informations about sources (like their partitions and desired QoS), sinks and a copy of the internal state of each of them. When the new peers has received all this data, it announces that it is ready to go online: the new peer updates the copy of other peers' state and starts to accept sinks to serve. A peer can also announce that it wants to disconnect from the dispatching system, terminating gracefully its operations and allowing the other peers to manage the redistribution of sinks smoothly.
DDS allows reliable connections if and only if its buffers aren't full. So it's possible to lose some packets even with reliable connections. This means that the peers of the dispatching system can get into a desynchronized state. To avoid this problem RE.VE.N.GE. system uses a recovery protocol: if a peer of the system receives an update relative to a peer, sink or source that it doesn't know it can recover the missing informations: it just sends a "request for data message" specifying the ID of the node it is interested to, and a randomly chosen peer will reply with a description of the node.
Relays
To support multi-domain architecture, REVENGE exploits the principle of locality. Each domain groups sources/sinks in the same locality and different domains exchange information through a network of peer nodes called "relays". This architecture reduces the data dissemination load towards sinks, now confined in a local domain scope, and allows increased efficiency assuming that most sources/sinks communications occur within the domain. The relays use a private DDS domain, called relay domain and shared by relays only, by typically communicating over public Internet.
Benchmark
We have thoroughly tested and evaluated the performance of REVENGE by deploying it in the heterogeneous wireless network at our campus. Our testbed consists of several Windows and Linux laptops equipped with Orinoco Gold WiFi cards on which we deployed REVENGE sources and sinks. The routing substrate peers run on 20 Linux boxes with 1.8 GHz CPUs and 2048MB RAM, connected through a 100Mbps LAN.
A simple first test shows the (local) routing layer scalability threshold at the increasing of the number of incoming sinks. In this scenario, the number of news that every copy must process is constant around 65 news/sec. The sinks are associated with each copy with a frequency of 1 macro-sink (interested in all news) every 15 seconds. To simulate the most critical case, each sink considered in the experiment requires point-to-point connections.
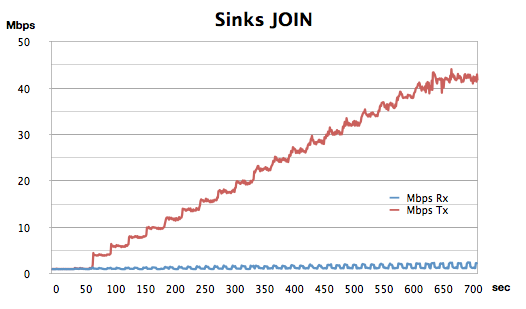
Figure shows that each copy can send news correctly up to about 40Mbps on a 100Mbps network; Beyond that threshold the sinks start dropping packets.
A second test stresses the system in the presence of multiple domains in a multi-relay scenario. Each relay is equipped with two network interfaces: a public interface to communicate with other relays (with public network bandwidth limit of 100Mbps), and a private interface to locally communicate with other domain entities. To stress our system in the worst case scenario, we again assume that relays use only point-to-point connections to communicate with each other.
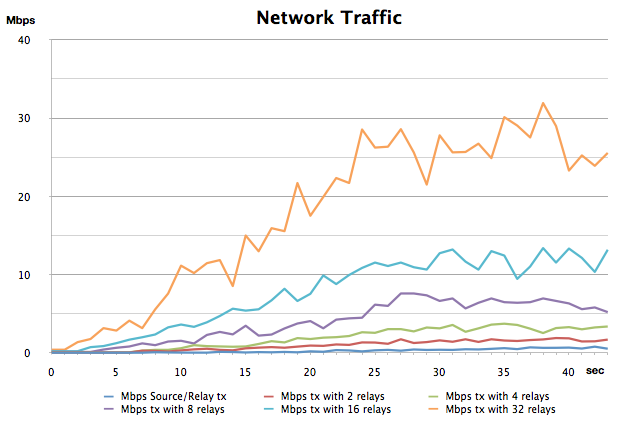
Figure summarizes the total network traffic when increasing the news delivery frequency and when increasing the number of relay (from the bottom to the uppermost graph). The figure clearly shows the scalability threshold in terms of maximum number of supported relays (interconnected domains) at message rate increasing: with 32 relays REVENGE starts to loose some messages, at a publishing rate of 75 news/sec data rate (about 900Kbps). Similarly to our previous experiment, while network capacity has proved to be the bottleneck, processor and memory load of relay nodes is fairly low.
The encouraging results are stimulating our current research work on REVENGE extension and refinement. For example, performance could be improved by making each peer replicate a limited set of other peers and by batching the send of update informations (thus trading the hot copies for warm copies).
Benchmarks and possible optimization, for example to support a very high scalability leveraging DDS' concepts of domains and partitions, are discussed in the documentation.