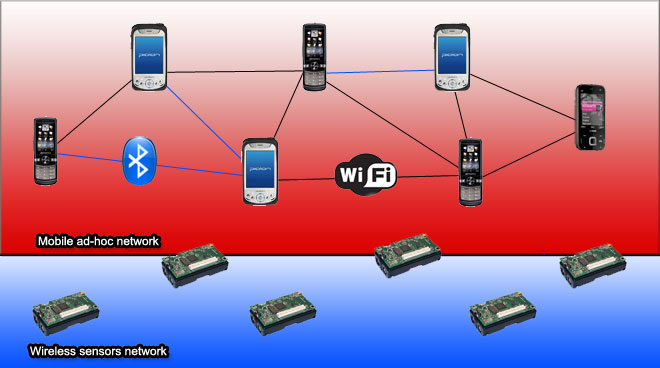
RECOWER Distributed ArchitectureAs stated in the scenario section, RECOWER mainly adopts a mobile infrastructure based on ad-hoc communications between mobile nodes. From a distributed architecture point-of-view, the mobile nodes carried by rescue team members are grouped in a peer-to-peer heterogeneous MANET that integrates both WiFi and BT technologies for local ad-hoc communications. To impose locality principle and to reduce management overhead, RECOWER does not assume any MANET multi-hop routing protocol, and manages data routing on a hop-by-hop basis between neighbors.
|
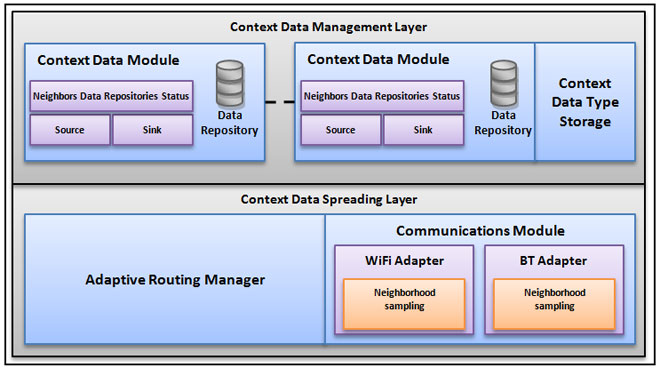
RECOWER Software ArchitectureRECOWER software architecture is divided in two principal layers:
|
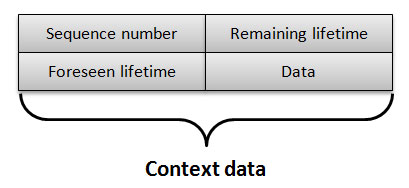
RECOWER General Data DistributionIn RECOWER, each context type is associated with a definition that contains both the structure of associated data and memorization policy. Once defined a particular data type, each mobile node can create and inject new data instances, while routing is addressed as explained in the following. RECOWER data routing is based on two principal entities, i.e., context data instances and queries. While context data represents the real context aspect, context queries are used to build lightweight dissemination paths into RECOWER MANET that trigger data distribution from remote repositories towards query creator node. In other words, context queries represent the basic routing information used to address context data routing. The sink associated with each context data module is in charge of translating application requests to proper context queries. At default, a context query is distributed to all the current one-hop neighbors by using a broadcast-based approach. When a query is received for the first time, the receiving node tries to match it with locally memorized data and, if possible, forwards matching data towards the creator node. Context data distribution is always performed on hop-by-bop basis in which each node sends matching data to the node that had relayed the query. If a query is not satisfied by locally memorized data, it is stored into the local routing manager to enable future context data routing, and further query distributions can be scheduled depending on query parameters. Both context data instances and queries have management information useful to control their associated distributions. In particular, each data instance has:
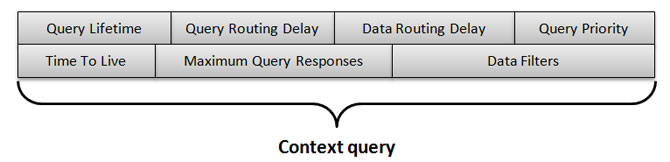
while each context query comes with:
Considering above parameters, each mobile node memorizes received queries according to the QLT and to MQR: when one of them is zero, the query is expired and removed. In addititon, the TTL limits the propagation of the query: each node decreases this parameter before distributing a query, and further distributions cannot be performed when TTL is zero. While all these parameters define the lifetime and the distribution scope of the query, the QRD and the DRD avoid context query/data immediate flooding, so to reduce wireless network congestion and to perform resource management. To adapt query/data distribution depending on current network load, RECOWER monitors wireless channel status and imposes limitations on sending operations. By monitoring both pending messages and bandwidth, RECOWER adapts QRD and DRD to increase both data distribution efficiency and reliability. |