ODT Implementation Detail and Experimental Results
|
ODT Implementation Detail and Experimental Results |
|
Implementation Detail To realize the data transformation from CSV to Linked Data (RDF format), we used Apache Any23. As for the triplestore, after tests detailed in the next subsection, we decided to opt for Virtuoso Open-Source Edition. The application used as query endpoint interface for our triplestore has been developed using Java and the Jena Framework ARQ to submit the query and retrieve the results. This library provide class for output formatting that was used for presenting results on screen as table, and saved on file in CSV and RDF formats. Finally, as GIS tool to generate maps, we used QGIS, a professional tool written in C++ that we extended realizing a new Python plugin.
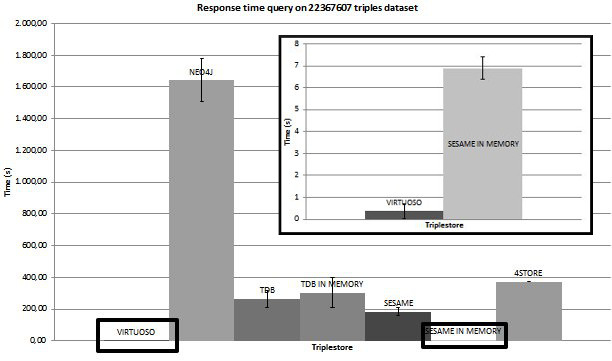
Triplestores Benchmark The first set of tests focuses on comparing and assessing the performances of different triplestores with the objective to help an informed choice of the most suitable solution. We tested triplestores both in query response, and in load time, namely, needed time to start a service with a defined dataset extent and to reply a specific query. With the help of three different datasets, respectively, with size of 1440324, 6034887, and 22367607 triples published by Eurostat (available here) already in RDF, we started a test campaign on selected triplesores. Analyzed triplestores include Virtuoso Open-Source Edition (version 7.0.0), Jena TDB (on-disk and in-memory, version 0.10.1), Sesame (on-disk and in-memory, version 2.7.3), 4Store (version 1.1.5) and Neo4J (version 1.9.2). The last one is a NoSQL graph database adapted to store and query linked data. All these triplestores are released under open license: this characteristic is a design constraint due to a request of municipality of Bologna, according to a recent national law.
| ||
|
||
A. Mean load time of different tripleset size with variance |
||
 |
||
B. Response time for same query on 22367607 triples dataset
|
||
|
||
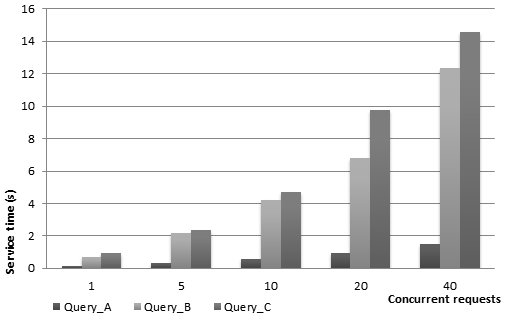
Scalability Test The second set of tests focuses on verifying the response time required by the endpoint to answer a query in a realistic scenario where multiple concurrent queries from external sources, and realizing the some use cases shown introduced in Bologna Open Data section, reach the triplestore. These tests have been conducted on a machine with Windows 7, 64 bit running on Intel Core i5 3210M (2.50GHz) and RAM 4 GB of DDR3 using Virtuoso Open-Source Edition version 6.1.6. Virtuoso uses a thread pool process with fixed number of thread defined on a configuration file and not modifiable during execution. The tests were conducted using the default value of 25 threads. For our tests, we use Virtuoso that shows the best response time from previous tests. To gain this information we selected three different SPARQL queries distilled from our from use cases: Query_A is a simple query relative to election use case that aggregate data of every polling place by neighborhood; Query_B is, also, relative to election use case and extracts comparisons between a party and wage using as aggregation level the neighborhood; Query_C is relative to the pharmacy use case and more complex by calculating pharmacy positions using the street numbers of the city. An increasing number of different processes (from 1 to 40) start the requests as a specified SPARQL query and wait for a response. The execution time is calculated as the time necessary to complete the query, from its creation to response reception; the variance is not showed because too small and considered not significant. Fig.C shows that Virtuoso can always handle incoming queries in a feasible time, even for complex ones with high 20 and 40 query rate bursts that represent our worst case stress scenarios. |
||
|
||
C. Service time for concurrent requests using Virtuoso |
||
| 20-mar-14 |