|
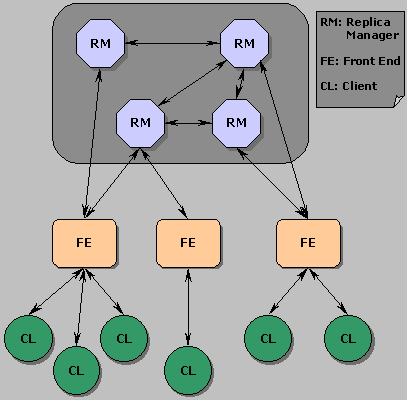
Il sistema è basato su un'architettura client-server in cui, per garantire alta availability e tolleranza ai guasti, si è ricorsi alla replicazione dei server che implementano il servizio di bulletin board. La figura seguente mostra l'architettura generale del sistema.
Ogni server, denominato Replica Manager, costituisce una copia attiva del servizio memorizzando i messaggi che gli vengono postati e rispondendo alle query. Ogni Replica Manager verifica sulla base delle sole informazioni che possiede che le operazioni di lettura e posting di messaggi richieste dai Front End non violino nessun vincolo di causalità. In tal caso le operazioni sono eseguite sulla sua copia locale del bulletin board (per ottenere fault tolerance i Front End effettuano il posting su più server prima di considerare un'operazione conclusa con successo). In caso contrario è necessario che il Replica Manager si coordini con le altre copie per garantire agli utenti una visione consistente dello stato del bulletin board. Gli utenti accedono al servizio tramite applicazioni denominate Client che non hanno visione della replicazione dei server poiché interagiscono unicamente con uno strato intermedio costituito da entità dette Front End. I Front End si occupano di rendere trasparente alla replicazione il servizio per i Client e di realizzare le politiche opportune per ottenere availability e fault tolerance comunicando direttamente con uno o più Replica Manager scelti staticamente o dinamicamente.
Attraverso l'applicazione Client un utente può richiedere due tipi di operazioni al servizio di bulletin board:
L'operazione di posting di un messaggio è l'unica delle tre a modificare lo stato del bulletin board. I due tipi di query si limitano ad un'osservazione dello stato e non vi apportano nessuna modifica.
Il numero di Replica Manager presenti nel sistema e la loro collocazione fisica sono fissati a priori. Da questo punto di vista il sistema è statico, tuttavia non è necessario che ogni entità abbia una conoscenza globale del sistema, è sufficiente che ogni Replica Manager conosca il numero di suoi pari presenti. Anche i Front End devono avere questa conoscenza ma possono acquisirla dinamicamente al primo contatto con un servitore replicato. Inoltre ogni Replica Manager è identificato da un indice intero che va da 1 a n se n è il numero di copie presenti. La ragione di ciò risiede nell'uso dei multipart timestamp usati per il coordinamento come si vedrà in seguito (sarà discussa anche un'estensione per superare la staticità).
Si ipotizza che sia i nodi sia le connessioni di rete possano manifestare malfunzionamenti che non siano di tipo "bizantino". Per i nodi si assume un modello di guasto fail-stop.
I Replica Manager devono risiedere su nodi diversi e failure-independent per consentire agli utenti di accedere a server alternativi in caso di caduta di un nodo o di una connessione di rete. Si assume inoltre che ci sia sempre attivo almeno un server.
Un Replica Manager caduto può essere ripristinato senza particolari accorgimenti: l'algoritmo di coordinamento è tale che esso riacquisirà uno stato consistente dalle comunicazioni con le altre entità presenti nel sistema. Affinché questo sia possibile, è necessario che i messaggi postati sulla copia locale siano stati memorizzati stabilmente, altrimenti è richiesta un'azione di recovery esplicita che attualmente non è implementata.