I test effettuati sul prototipo sono stati mirati alla valutazione delle prestazioni dell’algoritmo in una serie di casi significativi. Per l’esecuzione delle misure sono stati utilizzati 20 computer equipaggiati con microprocessore Intel Pentium 100 MHz, 16 Mb di memoria RAM e connessi tra loro mediante una rete Ethernet a 10 Mbit/s.
La piattaforma su cui è stato valutato il prototipo è costituita dal sistema operativo Windows NT 4 di Microsoft e dalla Java Virtual Machine del JRE 1.2.2 di Sun.
Le macchine utilizzate sono in effetti sottodimensionate, soprattutto per ciò che riguarda la quantità di memoria RAM, rispetto alla piattaforma software scelta, con l’effetto che le inevitabili saturazioni sono purtroppo comparse molto presto, falsando i risultati del test per elevati volumi di carico.
Il servizio replicato è implementato da un certo numero di Replica Manager a cui le macchine Client inviano un numero fisso di richieste.
La valutazione delle prestazioni deriva dalla misura dei tempi di risposta ad un determinato mix di richieste effettuate dai Client.
I tempi di risposta dipendono dalla dimensione e dal numero dei messaggi, oltre che dal carico su ogni singolo Replica Manager. La dimensione dei messaggi non è in generale un problema: essi sono di norma piccoli per una applicazione di scambio di news e in ogni caso la lunghezza massima dei singoli campi è limitata.
Diverso è il discorso per quanto riguarda il numero dei messaggi mantenuti dal sistema: il tempo impiegato per il completamento della richiesta di invio della lista ha infatti una componente che cresce linearmente con esso (almeno fino alla saturazione) .
Poiché non interessa misurare questo aspetto, che è di tipo puramente applicativo, una prima modifica all’implementazione ha avuto come scopo quello di limitare il numero dei messaggi che vengono effettivamente introdotti nell’insieme delle news. La classe che implementa queste modifiche è la BoundedNewsSet. Nella nostra prova il numero massimo di messaggi che sono effettivamente inseriti nell’insieme è pari a 5.
Ogni Replica Manager, oltre a ricevere le richieste dei Client, ed eseguire le query, deve inviare e ricevere dei gossip message. Una prima interessante valutazione sul prototipo, così come è descritto nel seguito, è quella di confrontare le prestazioni del servizio replicato con un servizio equivalente realizzato senza replicazione; il miglior metro di valutazione è in effetti lo stesso servizio, epurato di tutte le parti relative al coordinamento tra le varie copie attive.
Questa modifica all’implementazione risulta banale: è sufficiente creare una copia della classe ReplicaManager (chiamata MonoReplicaManager) in cui semplicemente non viene attivato il thread GossipManager.
Sono poi stati eliminati da ogni classe quasi tutti gli output, sia grafici che testuali, allo scopo di ottenere un seppur lieve incremento di prestazioni e ritardare il più possibile la saturazione. Per lo stesso motivo si sono ricompilate le classi con l’opzione di ottimizzazione del compilatore Java.
Gli utenti del servizio sono simulati su ogni macchina da un Robot derivato dalla classe Client. Esso invia una richiesta al Front End locale e ne attende il completamento, misurando il tempo intercorso tra i due eventi. Dopo un certo numero di azioni il Robot termina, restituendo una media dei tempi misurati. I parametri da fissare sono: il numero totale di richieste, la distribuzione di probabilità dei comandi, l’intervallo di tempo in cui sono uniformemente distribuiti i ritardi tra una richiesta e la successiva.
Per tutti i test i parametri utilizzati sono stati i seguenti:
Numero di richieste: 100
Probabilità dei comandi:
Intervallo di tempo: [300,1300] millisecondi.
Un altro parametro che è stato mantenuto fisso nelle misurazioni è il gossip-rate. L’intervallo di tempo che intercorre tra due richieste di gossip successive fatte da un Replica Manager è di 2000 millisecondi. In effetti le prestazioni del sistema sono molto sensibili alla variazione del gossip-rate, ma di questo diremo nel seguito.
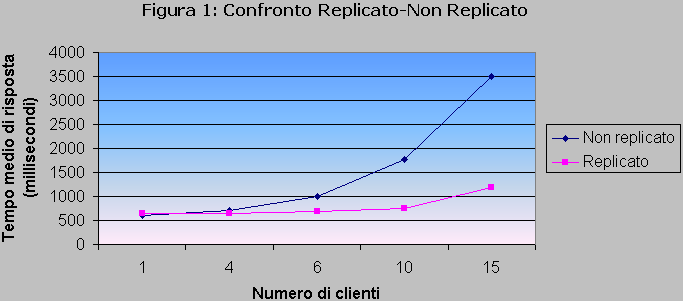
In questa prova si sono messi a confronto i tempi medi di attesa fatti registrare da un servizio realizzato rispettivamente con uno e con quattro Replica Manager completamente interconnessi.
I dati ricavati dalle misure, effettuate con un numero di clienti variabile, sono riportati in figura 1.
Il servizio replicato mantiene dei tempi di risposta pressoché costanti in un intervallo decisamente più ampio rispetto a quello del servizio non replicato. Le richieste da parte dei clienti vengono distribuite uniformemente sui quattro Replica Manager che implementano il servizio, mentre i thread che hanno il compito di effettuare il gossip aggiornano periodicamente tutte le copie.
Data la particolare natura dell’applicazione, che prevede l’invio di messaggi molto brevi e una elaborazione locale modesta, il fattore che più incide sulla performance è il costo della connessione Front End-Replica Manager. Mentre nel servizio realizzato con un solo Replica Manager tale costo è sostenuto in toto da un’unica macchina, la replicazione consente di distribuire l’overhead su varie copie, la cui consistenza è garantita dal protocollo gossip che accorpa in un unico messaggio (la cui dimensione è variabile secondo un elevato numero di fattori ma è comunque contenuta) tutte le informazioni significative ricevute da un Replica Manager in un determinato lasso temporale.
Una oculata scelta del gossip-rate permette di ottimizzare le prestazioni: valori alti implicano una coordinazione meno frequente (con conseguente riduzione dell’overhead) ma portano allo scambio di messaggi decisamente più lunghi poiché si riduce anche l’intervento della garbage-collection sugli insiemi che vengono passati.
Tutti questi parametri sono comunque molto sensibili all’implementazione e devono essere valutati caso per caso.
Come si è detto, in una applicazione in cui i messaggi sono così piccoli il fattore più critico dal punto di vista delle prestazioni è sicuramente il costo di connessione. Nella misura precedente ogni Replica Manager aveva la conoscenza statica di tutti gli altri e allo scadere di intervalli di tempo prefissati inviava un gossip a uno di essi. Si può pensare allora di ridurre la conoscenza locale in modo da ottenere uno spanning-tree sui vari nodi: siccome il protocollo di gossip è bidirezionale, è sufficiente far si che ogni Replica Manager abbia visibilità solo di un’altra copia.
I dati rilevati dal confronto tra questa soluzione e la topologia completamente connessa sono riportati in figura 2.
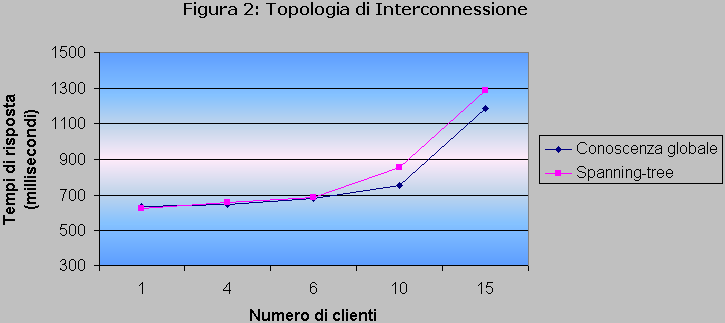
Come si può notare la differenza di prestazioni rilevata nel caso in esame è minima. Ciò non toglie che la scelta della topologia di interconnessione dei Replica Manager sia un fattore rilevante nella progettazione di un servizio reale: con questo mezzo è immediato realizzare un’idea di località, indispensabile nell’ipotesi di un ulteriore sviluppo del progetto verso lo studio della scalabilità.
I parametri su cui si può intervenire per modificare il comportamento del sistema e quindi ricercarne la migliore performance sono molteplici.
Ci si accorge quindi che non si può dare una valutazione quantitativa dell’effetto dei singoli parametri senza focalizzarsi su una precisa implementazione del servizio e anche così facendo essi rimangono legati tra loro in modo molto complesso.
E’ comunque possibile fornire alcuni criteri generali di scelta da cui partire per raffinare per tentativi il comportamento del sistema.
Consideriamo ad esempio la frequenza con cui i messaggi gossip sono scambiati: la scelta di questo parametro è fortemente dipendente dai vincoli dell’applicazione. Intuitivamente, un basso gossip-rate dovrebbe migliorare l’efficienza poiché il costo per il coordinamento viene sostenuto molto di rado. In realtà per tutti i servizi è necessario definire dei vincoli di tempo massimo per il coordinamento, che possono essere nell’ordine delle ore per un servizio di scambio di messaggi tra utenti, ma anche inferiori al secondo per servizi più critici.
C’è da osservare inoltre che se il sistema risulta molto carico a causa della comunicazione con i clienti, il costo per il coordinamento può risultare talmente basso da essere trascurabile.
Per ciò che riguarda la topologia di interconnessione il discorso è più complesso. Ridurre il numero di pari visibili a ogni Replica Manager significa ridurre il numero di connessioni che esso riceve mediamente in un intervallo di tempo e quindi l’overhead sostenuto per queste comunicazioni.
D’altra parte è necessario attendere mediamente di più per venire a conoscenza di un update fatto su un’altra macchina.
Inoltre è necessario passare a ogni comunicazione la ts_table di ogni Replica Manager che contiene l’ultimo stato conosciuto di tutti i pari. Questo per far si che ogni Replica venga a conoscenza anche dei timestamp di tutti pari con cui non comunica direttamente.
Nel test sulla nostra applicazione, effettuato con 4 Replica Manager, è risultato che la soluzione completamente connessa si comporta leggermente meglio.
Per la struttura dell’applicazione (che non necessita di un coordinamento stretto) è però lecito supporre che aumentando il numero di copie attive i risultati possano ribaltarsi, in seguito all’incremento del flusso di comunicazione.
Dal punto di vista della scalabilità, il sistema presenta delle limitazioni evidenti dovute alla crescita lineare delle dimensioni delle strutture dati mantenute e scambiate nel protocollo di coordinamento. Qualora si rendesse necessario utilizzare un numero molto elevato di Replica Manager, si possono migliorare le prestazioni introducendo delle copie read-only che fungano da cache locali nei confronti di gruppi di Front End. Una copia read-only non necessita di una entry nelle strutture di coordinamento e non scatena gossip ma è utile per bilanciare il carico di query, mentre gli update devono comunque essere rivolti ai Replica Manager. Le copie read-only devono poi essere aggiornate come le altre.