
Un file-server distribuito
Progetto di Luca Armani e Davide Boari
per il Corso di Reti di Calcolatori, A.A. 1998/99
Le specifiche
Si vuole realizzare un'applicazione client-server
per il recupero di file di media dimensione (ad esempio immagini
gif-jpeg). Si vuole che il server sia distribuito, in modo che
sia possibile avere un gran numero di file sparsi su più
macchine, anche eterogenee. La topologia della rete è lasciata
volontariamente libera in modo da poter paragonare le prestazioni
con topologie diverse; ovviamente i server devono sapersi
configurare in modo appropriato e devono anche mantenere connessa
la rete in caso di caduta di uno dei nodi. La stessa rete può
cambiare dinamicamente senza che il servizio si debba
interrompere.
I processi client devono potersi connettere a uno qualsiasi dei
nodi server, richiedere un file e poi attendere che questo venga
consegnato; è chiaro che tutto il meccanismo di sincronizzazione
tra i server deve essere trasparente al client.
E' richiesto che il server sia concorrente e che sia il più
possibile veloce per quanto riguarda il tempo di risposta verso i
client. Per questo si è deciso di sviluppare due versioni del
progetto. La prima prevede che, una volta trovato il file, esso
venga trasmesso di server in server facendo a ritroso il percorso
delle richieste, finchè l'ultimo server non lo trasmette al
client. In aggiunta si possono dotare i server di un meccanismo
di caching. La seconda versione invece prevede che sia il server
proprietario a inviare il file al client. E' possibile che per
una stessa richiesta il client si veda recapitare più volte il
file, in tal caso basterà scartare i dati indesiderati.
Per contro il progetto non richiede che i file siano su memoria
stabile, cioè non è richiesta alcuna replicazione dei dati su
più copie, nè tantomeno sono richieste specifiche di sicurezza
o di autenticazione.
1.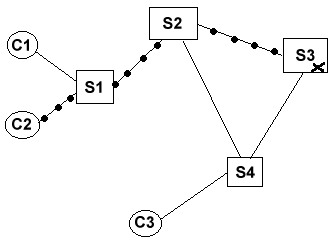 2.
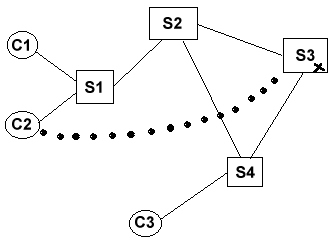
2.
La comunicazione
Gran parte del progetto si basa sulla comunicazione via rete. La richiesta del client non ha bisogno di affidabilità, quindi si è scelto di inviare un datagramma UDP contenente il nome del file senza creare una connessione. Invece per i server si è pensato di creare una connessione TCP permanente; ogni coppia di server ha così un canale dedicato su cui viaggiano i messaggi di controllo (richiesta di un file al vicino, messaggi di acknowledge, passaggio di tabelle, ...). Infine per trasmettere i file veri e propri si è deciso di creare delle connessioni TCP by-need. Lo spazio dei nomi è quello degli indirizzi IP; ogni nodo server è univocamente riconosciuto dal suo indirizzo IP e da un numero di porta di default.
Architettura del server
Innanzitutto la scelta del linguaggio. Java2 è stato scelto
perchè:
- è portabile e dunque consente di installare i nodi server su
piattaforme diverse;
- dispone di una buona gestione dei thread e pertanto risulta
facile sviluppare un'applicazione con un alto grado di
concorrenza;
- ha una notevole libreria di primitive per la comunicazione via
rete (java.net);
- è ad oggetti ed è facile da usare.
Dalle specifiche emerge come ogni nodo server debba essere
autonomo: non ci deve essere nessuna idea di centralizzazione del
servizio, nè nessun organo coordinatore privilegiato. Dunque
ogni nodo server dispone di:
- un thread in ascolto di connessioni di altri server;
- un thread per ogni vicino conosciuto a cui cerca di connettersi;
- un thread per ogni vicino già connesso per la ricezione di
messaggi di controllo;
- un thread in ascolto dei client;
- un thread per ogni richiesta di file (thread di servizio).
Dovendo rispettare un'ampia e quanto più flessibile topologia di
interconnessione, inizialmente ogni nodo server ha conoscenza
solo dei suoi diretti vicini, e ignora completamente quale mondo
vi sia al di là di essi. Un semplice file di configurazione
permette quindi di realizzare anelli, bus, mesh o qualunque altro
tipo di rete.
Negoziazione
Lo stato del server è descritto da una tabella dei file
cercati. Vediamo con un esempio come avviene la propagazione
delle richieste: supponiamo che il client C3 richieda il file
file1.jpg a S4. Il client comunica cioè il nome del file e in più
un timestamp (un long in formato UTC) che ha la funzione di
contrassegnare in modo unico la richiesta.
Si presentano i due casi:
Versione1. S4 mette nella tabella dei file cercati il timestamp;
cerca il file, non lo trova, allora manda un messaggio di
richiesta a S2 e S3 contenente il timestamp di prima, il nome del
file, il suo indirizzo IP e il numero di una porta sulla quale
aspetterà il file. S3 non trova il file, lo richiede a S2 che
risponde no perchè ha già in tabella lo stesso timestamp,
quindi anche S3 risponde no a S4. Intanto S2, non trovando il
file, lo chiede a S3 (che risponde no) e a S1. S1 trova il file e
lo manda alla porta specificata da S2, che a sua volta lo
rimbalza a S4 e questi al client.
Versione2. come versione 1 solo che nei messaggi di richiesta l'indirizzo
e la porta su cui spedire il file sono sempre quelli del client.
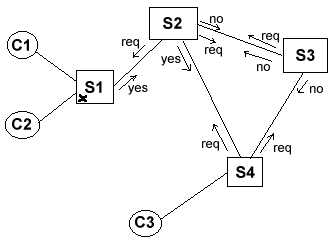
NOTA: si è scelto di non cancellare le entry della tabella dei
file cercati al primo "si" o all'ultimo "no"
dei vicini interpellati in quanto in particolari topologie alcune
parti di rete "più veloci" potevano esaurire la
richiesta e resettare il loro stato, e quando poi arrivava la
richiesta da una parte "più lenta" tale richiesta
veniva esaudita una seconda volta e potevano insorgere dei loop
autosostenuti. Pertanto i timestamp vengono tenuti per quanto più
tempo possibile e eliminati in modo FIFO.
Tolleranza ai guasti
Le socket TCP garantiscono che il vicino sia
sempre connesso. Non appena un nodo cade tutti i suoi vicini sono
in grado di rilevare il guasto e di intervenire. Durante il
normale funzionamento, infatti, i nodi comunicano ai vicini gli
indirizzi degli altri vicini, cosicchè ogni nodo viene ad avere
una conoscenza della rete fino al secondo ordine. Il meccanismo
è dinamico e le tabelle vengono aggiornate ad ogni cambiamento
della rete. Quando un nodo cade i suoi vicini reagiscono
togliendolo dalla loro tabella, inoltre ripristinano la rete
affinchè non resti partizionata, aggiornano il nuovo stato e
controllano periodicamente che il nodo scomparso non torni in
vita.
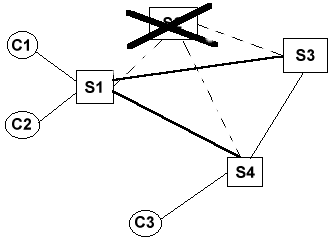
Il meccanismo di riconnessione non è ottimale, in quanto cerca
di connettere tutti con tutti anche dove alcuni collegamenti
sarebbero ridondanti. Tuttavia un algoritmo più accurato non era
lo scopo di questo progetto.
27/9/1999, Luca Armani ![]()