The Virtual Museum Infrastructure (2) |
 |
The Virtual Museum Infrastructure (2) |
|
|
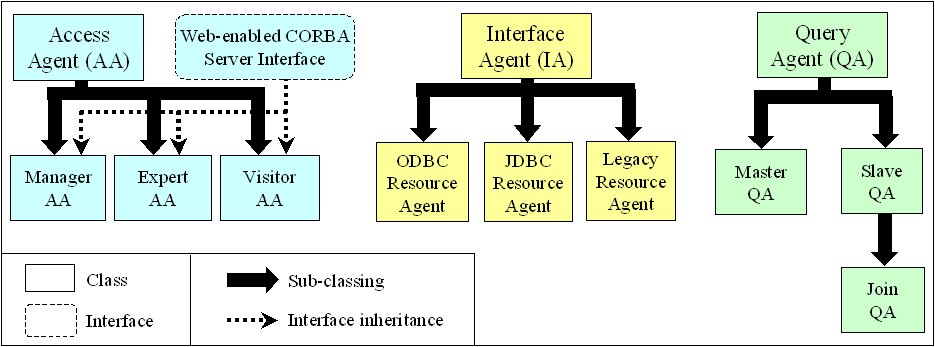
The Interface Agent (IA) is the stationary entity that encapsulates information resources by abstracting from their peculiar implementation details. It represents the key component to overcome heterogeneity in data resources, and provides a uniform interface to the other components of the VM infrastructure. Its implementation is different depending on the peculiar characteristics of the encapsulated data resource: we have already implemented two specialized IAs for data resources that own JDBC and ODBC access interfaces; we are currently working on the encapsulation of legacy data components via CORBA interfaces (see Figure 2). In addition to overcoming data heterogeneity, the IA enforces the security policies for data resource access: it receives user authentication information from the AA, and registers resource consumption for accountability. The IA is always placed locally to the data resource it encapsulates. As a consequence, apart from its initial dynamic code distribution, the IA is mainly a stationary agent; however, it can move to follow the possible migration of the encapsulated data resource, e.g. the transfer of a database on a new server (see also the mobility support pages). The Repository Agent (RA) is the stationary agent in charge of organizing the data resource name service for the whole system. Typically, we have one RA in each SOMA domain. After receiving a query, any AA interrogates its RA to discover the physical locations of the data resources involved. The RA resolves the logical names of the resources into the corresponding physical locations of the IAs. The information maintained by a single RA does not cover all the data resource names in the system. RAs are hierarchically organized: one RA that is not able to respond to a name resolution request simply forwards it to its higher-level RA in the hierarchy, and waits for an answer in a way that is completely analogous to the resolution of logical IP names in the DNS. In addition, in case of replicated data resources, the RA chooses the IA among a group of equivalent ones according to locality and load-balancing evaluations. The Query Agent (QA) is the mobile entity that really performs user-specified queries on data resources. After one user inputs a query, the AA parses it and interrogates the RA in its domain to discover which data resources are interested by the interrogation. At that point, on the basis of the query structure and of data localization, the AA decides the number of QAs to generate. Any query is always performed by a group of coordinated QAs that exploit the communication facility provided by the SOMA platform. We have already implemented several QA refinements (see Figure 2). A master QA is the query-responsible agent that coordinates the other agents (slave QAs), puts together the overall result and yield it back to the interested user. Slave QAs, instead, calculate the results of independent partitions of the original query, and generally are instantiated and distributed one for any SOMA domain to be explored. Finally, in the case of join operations, slave join QAs have the opportunity to delegate sub-queries to new slave QAs, generated on-the-fly, and to wait for merging the corresponding sub-results. (Other MA-based components follow...) |
|
|
|
|
|
|
|
Page
updated on
|
In
case of problems, or if you find any bug, please contact us.
|
||