Summary Diffusion
Any regular node periodically advertises a new packet with generated summaries to its current neighbors in order to increase the opportunities for agents to harvest summaries.Clearly, excessive advertising will introduce too much overhead, while no advertising at all will require considerable more time, as agents will need to contact each individual car to complete the harvesting process. Thus, MobEyes tries to identify the optimal tradeoff. As depicted in the Figure below, a packet header includes a packet type, generator ID, locally unique sequence number, packet generation timestamp, and generator's current position. Each packet is uniquely identified by the generator ID and its sequence number pair, and contains a set of summaries locally generated during a fixed time interval.
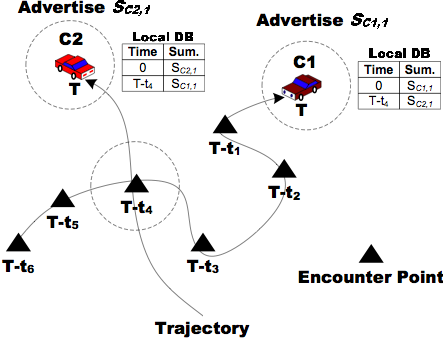
Let us also briefly note that summaries always include, of course, the time and location where the sample was taken. Upon receiving an advertisement, neighbor nodes keeps the encounter information (the advertiser's current position and current timestamp). This allows MobEyes nodes to exploit spatial-temporal routing techniques and a geo-reference service when accessing actual raw data. That is obtained as a simple byproduct of summary dissemination, without additional costs.
Summary Harvesting
In parallel with diffusion, MobEyes summary harvesting takes place. There are two possible modes of harvesting the "diffused" information, namely on demand and proactive. In the on demand mode, the police agents react to an emergency call, for example, the earlier mentioned poisonous gas incident. Police agents will converge to the outskirts of the area (keeping a safe distance of course) and will query vehicles for summaries that correspond to a given time interval and area (i.e., time-space window). Suppose 1000 such summaries exist. The police agents as a team will collect as many summaries as they can, up to 1000. They will collectively examine the summaries and decide to inspect in more detail the video files collected by 100 vehicles, say. The vehicles can be contacted based on the vehicle ID number stored in each summary. A message is sent to each vehicle requesting it to upload the file at the nearest police access point. The request message is generally routed using georouting, either exploiting the Geo Location Service that maps vehicle ID to the current vehicle location, or using the "Last Encounter Routing" technique. The latter technique is particularly convenient here because at the time the summary exchange takes place, nodes memorize the time and place of the encounter.Naturally, the on demand harvesting incurs the problem of latency in dispatching the vehicles to the location and in collecting the summaries. To overcome this latency, we are proposing also a "proactive" version of the index construction. Namely, in each area there are agent vehicles that collect all the summaries as a background process and create a distributed index. In this case, there is no time-space window concern during collection. The only requirement is to collect all the summaries in a particular area. Now, if the poisonous gas emergency occurs, the query is directed to the proactively created distributed index. The time-space window concept is applied to the index to find the vehicles in a particular place and time and then pursue the hot leads.
It is apparent that the two processes become identical after the desired summaries have been identified on board of the agent vehicles. The proactive approach is much more powerful in that it can speed up the search considerably. For instance, if the inspection of the information collected in the crime area indicates a possible escape direction of the terrorists, one can immediately search again the proactively created index for a new time-space window, without having to do another time consuming collection of summaries from vehicles. On the negative side, maintaining that index is costly, as agent resources must be dedicated to the task.
In the sequel we will assume proactive index construction. Thus, the agents collect all summaries indiscriminately. There is no loss of generality, however, since the procedure will also allow on demand index construction for a specific time-space request. In fact, the only difference between the two harvesting schemes is the size of the set being harvested. In the on demand scheme, the target set is a specific space-time window set. In the proactive scheme, the target set is the entire geographic area within agent responsibility; there is no limit on harvesting time, though old records are timed out.
By considering the proactive harvesting model, the MobEyes police agent collects summaries from regular nodes by periodically querying its neighbors. The goal is to collect all the summaries generated in the specified area. Obviously, a police node is interested in harvesting only summary packets it has not collected so far: to focus only on missing packets, a MobEyes authority node compares its list of summary packets with that of each neighbor (set difference problem), by exploiting a space-efficient data structure for membership checking, i.e., a Bloom filter. A Bloom filter for representing a set of \omega elements, S={s1,s2,...,sΩ}, consists of m bits, which are initially set to 0. The filter uses l independent random hash functions h1, ..., hl within m bits. By applying these hash functions, the filter records the presence of each element into the m bits by setting l corresponding bits; to check the membership of the element x, it is sufficient to verify whether all hi(x) are set to 1.
A MobEyes police agent uses a Bloom filter to represent its set of already harvested and still valid summary packets. Since each summary has a unique node ID and sequence number pair, we use this as input for the hash functions. The MobEyes harvesting procedure consists of the following steps:
- The agent broadcasts a "harvest" request message with its Bloom filter.
- Each neighbor prepares a list of "missing" packets from the received Bloom filter.\inv
- One of the neighbors returns missing packets to the agent.\inv
- The agent sends back an acknowledgment with a piggybacked list of returned packets and, upon listening to or overhearing this, neighbors update their lists of missing packets.\inv
- Steps 3 and 4 are repeated until there is no remaining packet.
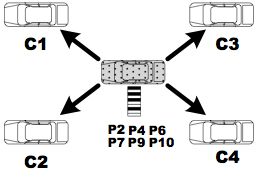
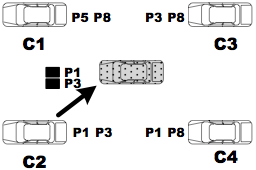
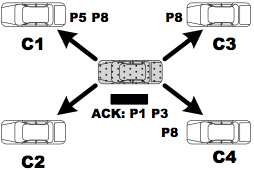
For the sake of simplicity, thus far we assumed that there is a single agent working to harvest summaries. Actually, MobEyes can handle concurrent harvesting by multiple agents that can cooperate by exchanging their Bloom filters among multi-hop routing paths; thus, this creates a distributed and partially replicated index of the sensed data storage. In particular, whenever an agent harvests a set of j new summary packets, it broadcasts its Bloom filter to other agents, with the benefits in terms of latency and accuracy shown in the following section. Note that strategically controlling the trajectory of police agents, properly scheduling Bloom filter updates, and efficiently accessing the partitioned and partially replicated index are part of our future work. In the following section, instead, we focus on the primary goal of identifying the tradeoffs between dissemination and harvesting in a single geographic area, and the dependence of MobEyes performance on various parameters. We also analyze the traffic overhead created by diffusion/harvesting and show that it can scale well to very large node numbers.