Un cliente che vuole usufruire
di questo sistema deve prima farsi riconoscere tramite una specie di login
in cui digita il suo nome e il suo codice. Se l'utente è riconosciuto
può effettuare un ordine presso una delle ditte cui è
convenzionato oppure ricevere informazioni su eventuali ordini da lui effettuati
in precedenza.
Una volta creato l'ordine
l'utente può inviarlo a un database in cui sarà registrato.
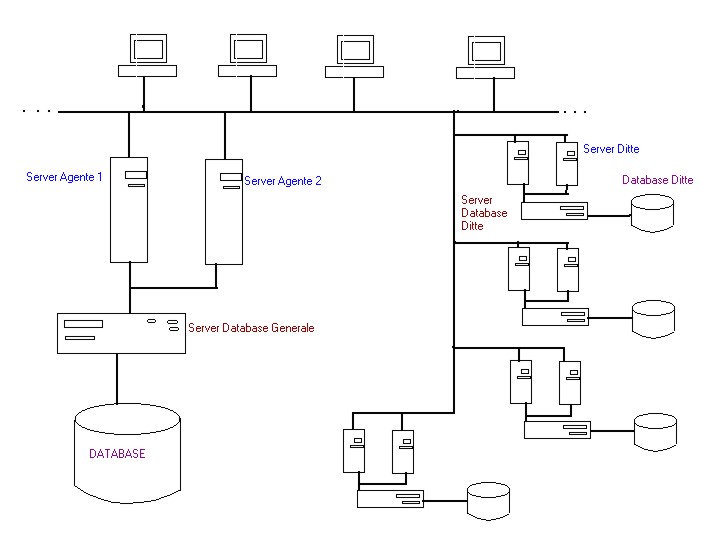
Per ricevere o spedire informazioni il
cliente si avvale di server che a loro volta si metteranno in contatto
con i rispettivi database.
Per avere affidabilità
dei server si utilizza la replicazione: sono presenti due programmi server
su due nodi diversi che sono in attesa di richieste da parte di eventuali
clienti. I server, ricevute le richieste dai client si mettono in
contatto con un altro server , detto di banca , che gestisce tutti i dati.
Il cliente conosce entrambi
gli indirizzi dei server replicati ed effettua le richieste su uno dei
due : selezionandolo , quando gli si presenta un menù di scelta
, oppure in altri casi la scelta sarà quella di default.
Le ipotesi fatte sono:
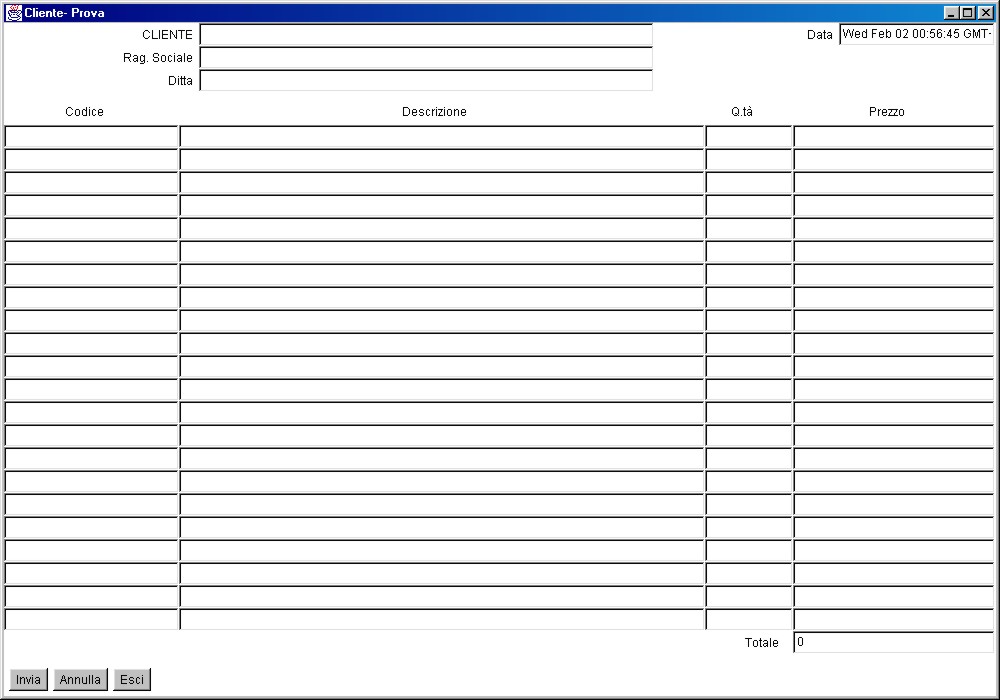
Prima di poter iniziare a definire l'ordine e prima di inviarlo , il client deve farsi identificare tramite un'apposita finestra che richiede nome e codice con cui lo stesso client è stato registrato nel database del sistema aziendale.

Ogni tentativo di invio di
ordini senza essere stati identificati è rifiutato , allo stesso
tempo viene ripresentata la finestra di identificazione.
Prima dell' identificazione
possono comunque essere riempiti i vari campi dell' ordine , ma questi
non sono interattivi :il cliente cioè non è in grado di scambiare
alcuna informazione con le ditte in quanto non è ancora capace di
effettuare connessioni con i loro database.
Quando i campi della finestra
di identificazione vengono riempiti e viene premuto il tasto OK il
client può scegliere con quale server connettersi come primo tentativo.
Se il server prescelto non risponde alla richiesta entro un certo tempo
(timeout), poiché potrebbe essere guasto o non attivo, il client
prova a collegarsi con l'altro e così via alternativamente , di
time out in time out, finche non ce n'è uno che risponde alla richiesta.
A questo server viene spedito
il nome ed il codice del cliente.
A questo punto il client
si mette in attesa di una risposta che gli dovrà fornire il server
con cui si è messo in contatto. Se la risposta ricevuta è
negativa allora il client dovrà provare a riconnettersi per farsi
identificare correttamente altrimenti non può effettuare ancora
alcun tipo di operazione. Al contrario , se la risposta è positiva
il client riceve informazioni sulle ditte con le quali ha stabilito un
rapporto commerciale che quindi possono ricevere i suoi ordini. Infatti
il cliente si trova a dover scegliere quale ditta vuole contattare
, tra quelle a cui è convenzionato.
Scelta la ditta il client
può ora riempire i vari campi dell' ordine ricevendo informazioni
dai database delle ditte. Il campo che definisce il nome del cliente e
della ditta non sono ormai più modificabili e viene inoltre chiesto
con una finestra apposita , se non lo è stato fatto in precedenza
, di definire la propria ragione sociale. Il cliente , a questo punto,
trova il cursore attivo nel textfield del codice del primo pezzo della
videata che rappresenta l'ordine.
Ogni volta che viene scritto
un codice e poi si tenta di lasciare quel campo , il client chiede informazioni
al database della ditta che ha precedentemente scelto , stavolta però
non gli viene chiesto di fare una scelta su quale server della azienda
contattare per primo perché ci si può rendere conto che riempiendo
tutti i campi dei codici , il cliente si troverebbe a dover scegliere tutte
le volte quale server contattare per primo , in questo caso allora , viene
effettuata una scelta di default. Se il codice è riconosciuto dalla
ditta , vengono fornite anche le altre informazioni relative a quel pezzo
, cioè la sua descrizione ed il prezzo ; allo stesso tempo
viene reso attivo il campo che definisce la quantità voluta
dell' oggetto. In base alla quantità desiderata viene ricalcolato
in tempo reale il totale dell' ordine ; se viene digitata una quantità
non corretta , ad esempio non viene scritto un numero valido , rimane attivo
lo stesso campo di quantità in attesa che venga inserito un valore
giusto , se invece si tenta di andare al codice successivo senza aver scritto
nulla , questa azione viene intesa come azione di default : la quantità
desiderata sarà di un' unità.
Se al contrario il codice
non esisteva o non è stato inserito correttamente rimarrà
attivo sempre lo stesso campo di codice finché il pezzo non verrà
riconosciuto. Descritto correttamente codice e quantità viene automaticamente
reso attivo il campo del codice successivo.
Quando il cliente ha completato
l'ordine può inviarlo alla banca dati del sistema principale che
provvederà a registrarlo. Il client si mette sempre in contatto
con uno dei due server che gestiscono le richieste inviate al database
generale del sistema.
Se l' ordine è stato
registrato correttamente il cliente avrà la convalida di questa
operazione altrimenti sarà informato del cattivo esito della registrazione
e sarà invitato a rieffettuare l' ordine , in quanto si potrebbero
essere verificati errori nei server atti alla memorizzazione della commissione
oppure qualche macchina non era ancora attiva. Infine viene presentata
una finestra di opzione in cui si può scegliere se fare un altro
ordine oppure uscire dall' applicazione , se si decide di farne un altro
si ripresenta il menù di scelta delle ditte con cui si può
interagire.
Per realizzare questa applicazione
devo effettuare varie scelte : ad esempio posso scegliere in che modo fare
le connessioni con i vari server e per quanto tempo stabilirle. In effetti
posso scegliere tra connessione affidabili TCP/IP oppure connectionless
con il protocollo UDP. Un' altra scelta riguarda la durata della connessione
: posso scegliere di stabilire una connessione con il primo dei due server
agenti attivo e mantenerla per tutti i possibili invii di ordini o di codici
di identificazione che può fare un client e chiuderla solo al momento
in cui cessa l'applicazione oppure posso preferire di stabilire delle connessioni
provvisorie attive solo per il tempo necessario a trasferire o ricevere
dati. Lo stesso discorso vale per le connessioni che si devono creare con
i server delle ditte.
Per le informazioni
riguardanti i server delle ditte , queste
vengono fornite insieme al DatagramPacket
che viene ricevuto dopo
l' identificazione , questo pacchetto deve essere decodificato e da esso
se ne ricava un elenco di ditte che viene messo in un Vector di dimensione
non stabilita a priori che può variare secondo necessità
; per ogni ditta , oltre al nome , vengono forniti gli indirizzi e i numeri
di porta dei server che possono ricevere richieste per la decodifica dei
codici dei pezzi. Una volta che ci si è identificati e riempito
tale vettore dinamico , l' elenco delle ditte rimane disponibile per tutta
la durata dell' applicazione client , infatti effettuato un ordine se ne
può effettuare subito un altro anche cambiando la ditta presso cui
eseguirlo.
Il fatto di dover configurare
il client per permettergli di stabilire le connessioni con i server e la
scelta di ricevere informazioni registrate nel database generale per sapersi
collegare ai server delle ditte può sembrare una scelta poco efficiente
; sembrerebbe più logico creare una entità unica che sia
in grado di fornire i dati necessari alle connessioni su specifiche richieste
, informazioni che questo gestore riceverebbe ogni volta che un nuovo componente
facente parte del sistema viene avviato , in modo di avere una completa
trasparenza degli indirizzi conoscendo solo quello di questo manager. Tutto
ciò però dipende dall' ottica con cui si guarda il progetto
: la necessità di creare una finestra di configurazione per il client
è stata dettata dal fatto che il progetto è in una fase prototipale
, quindi durante le prove i vari server possono essere attivati su macchine
di volta in volta distinte , ma ragionando in un ottica reale , in una
eventuale simulazione di questo progetto i vari server avranno una localizzazione
fissa e solo in casi del tutto eccezionali si sposteranno su altri nodi
, quindi l' introduzione di un gestore degli indirizzi renderebbe tutta
la applicazione più faticosa aumentandone l' overhead. Inoltre con
un unico gestore si ripresenterebbero di nuovo i problemi di affidabilità
in caso di guasto di quest' ultimo. Si è scelto quindi di seguire
la strada di effettuare una configurazione del client solo su necessità
, in casi cioè del tutto eccezionali.
Per quanto riguarda la scelta
di avviare l' applicazione in modalità "informazioni" sono possibili
due diverse strade su come ottenere i dati riguardanti gli ordini passati
: un modo è quello di ricevere tutti insieme , una volta identificati
, gli ordini passati inserendoli in un vettore dinamico che poi verrà
scandito secondo necessità ; l' altro è quello di richiedere
al database generale , tramite i due server , le informazioni volta per
volta solo quando è necessario. Questa seconda scelta anche se giusta
dal punto di vista di richiedere dati solo quando necessari mi sembra però
allo stesso tempo troppo costosa , infatti ricevuto il primo ordine da
visualizzare (l' ultimo in termini di tempo) , ogni volta che se ne vuole
vedere un' altro è necessario riconnettersi e ricevere informazioni
partendo dal punto in cui si era arrivati , ciò presuppone che ,sia
il server agente , sia il database dovrebbero tenere traccia delle
richieste passate fatte da ogni client attualmente attivo , inoltre si
dovrebbe aprire , per quanto riguarda il database generale , il file contenente
queste informazioni ad ogni richiesta , oppure tenerlo aperto fino alla
conclusione della sessione in cui tale cliente è attivo. Ho quindi
pensato che fosse molto più semplice trasferire in una volta sola
tutti i dati necessari per poi lasciare al solo client il compito
di gestirli e visualizzarli nei modi e nei tempi che ritiene più
opportuni.
Per ottenere informazioni
e per spedire ordini si usa la stessa classe java connOrdine solo che la
connessione viene effettuata con un metodo che ha come parametro di ingresso
un intero il quale funge da opzione , in base a questo intero si effettuano
due diverse sequenze di operazioni diverse per il trasferimento dei dati
a seconda del servizio che si deve svolgere.
Durante tutta l' applicazione del
client sono state introdotte delle finestre informative sulle situazioni
di errore in cui ci si imbatte man mano, ad esempio quando scatta un timeout
o quando non è possibile stabilire una connessione affidabile
etc. Tutto ciò toglie trasparenza
all' applicazione client che si accorge dei tentativi di connessione fatti
di volta in volta. Queste finestre informative però , sono state
introdotte soprattutto per far rendere conto , a chi vede l' evolversi
di tutto il sistema , di come questo funziona e delle cause che inducono
il programma a generare le eccezioni. Per tornare ad una situazione di
completa trasparenza da questo punto di vista , basta eliminare queste
finestre così il client avrà solo le risposte ai servizi
che via via richiede , risposte che però si faranno attendere di
più o di meno in termini di tempo se il programma si imbatte o no
, in casi anomali ma previsti.
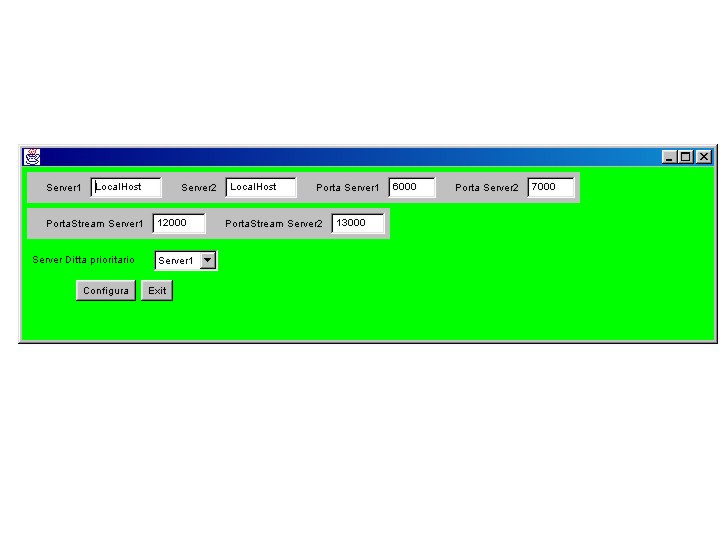
Avviata l' applicazione
server è necessario inizializzarla tramite il pulsante OK del pannello
di controllo. Premendo questo tasto infatti si attiva il server che crea
le connessioni necessarie per ricevere richieste da parte dei client ;
i campi che definiscono le modalità di questa connessione sono riempiti
con valori di default , tali campi però possono essere modificati
prima di configurare il processo.
Questi campi identificano
l' allocazione del database generale , con indirizzo dell' host e le porte
(una per la socketdatagram e una per la stream) che questo ha riservato
per ricevere le richieste che gli invia il server , inoltre si possono
anche modificare i numeri di porta che il server stesso riserva per creare
la socket stream e la socket datagram.
Una volta configurato ed
avviato , il server crea una ServerSocket che si metterà in attesa
, tramite il metodo accept , delle richieste inviate dai client ; siccome
ogni server deve provvedere a rispondere ad un numero non conosciuto di
client è necessario , oltre che esaudire ogni richiesta ricevuta
, tenersi sempre attivi per raccogliere altre eventuali domande anche quando
si è impegnati nell' esecuzione della procedura di risposta ad un
altro client. Ciò è possibile implementarlo tramite l' uso
della classe java dei Threads , cioè dei processi leggeri che vengono
eseguiti parallelamente al processo che li ha generati. Quindi il server
con un ciclo infinito si pone in una continua attesa di richieste e ogni
volta che se ne verifica una , attiva un Thread che ha il compito di inoltrare
la stessa richiesta al server database.
Bisogna dire che è
stato scelto di implementare il servizio con dei Threads perché
in java costa poco , in termini di risorse , un loro utilizzo ; inoltre
la registrazione di un ordine si può considerare un' operazione
lunga in termini di tempo , quindi per avere un servizio real time è
necessario attuare una politica di concorrenza del servizio in modo tale
da poter soddisfare più richieste contemporaneamente.
Per ipotesi abbiamo detto
che il server database è sempre attivo , quindi il gestore di una
richiesta di registrazione di ordine riesce sempre a creare una socket
stream con successo per passare i dati al database , lo stesso discorso
vale per una richiesta di lettura degli ordini : il gestore del server
che fa queste operazioni è sempre lo stesso ma come primo dato che
riceve dai client questo riceve un intero che sta ad identificare il tipo
di richiesta voluta , a seconda dell' opzione selezionata si svolgono due
sequenze di operazioni differenti.
Se il database fosse spento o guasto
si visualizza nella text area un messaggio di errore e al client è
inviata una risposta di cattivo esito per la registrazione.
Per quanto riguarda la connessione
datagram il discorso da fare è un pò diverso : quando il
server riceve un messaggio deve poi inoltrarlo al server che gestisce il
database , ma essendo la connessione non affidabile può accadere
che il messaggio non giunga a destinazione anche se il server è
effettivamente attivo , quindi nell' implementazione di questo servizio
dobbiamo preoccuparci di inviare il messaggio finché non riceviamo
dal server del database un segnale di richiesta ricevuta. Anche in questo
caso , come per il client , il server spedisce il messaggio , setta un
timeout e si mette in attesa di una risposta , se questa non arriva entro
il timeout viene generata un' eccezione catturata dallo stesso processo
server che tenta nuovamente di rispedire. In questo caso però
non generiamo un Thread per ogni richiesta ricevuta , in quanto il servizio
da svolgere è relativamente breve , così ritengo più
conveniente sequenzializzare le richieste tramite il modificatore per i
thread synchronized , questo modificatore svolge una funzione di semaforo
per la risorsa di tipo DatagramPacket per tutta la durata della sezione
critica in cui la utilizziamo per spedire e ricevere messaggi.
Per quanto riguarda il caso
di guasto , dobbiamo rendere il cliente inconsapevole di quello che succede
, infatti , se un client aveva inoltrato una richiesta e questa non viene
soddisfatta perché il server non era attivo o è caduto mentre
la stava esaudendo , il client non riceverà risposta e automaticamente
proverà a collegarsi con l' altro server replicato che per ipotesi
dovrà essere attivo , se anche questo non lo fosse il client non
può ricevere risposta e proverà quindi a richiedere la connessione
in un secondo momento. Vediamo che questi server sono privi di stato ,
cioè non tengono traccia delle interazioni che hanno avuto con i
vari client , nè dei client collegati con loro attualmente ; il
protocollo di rientro da un guasto di un server stateless
è molto semplice perché non è necessario ripristinare
la situazione che si era venuta a creare fino al momento del guasto
; quindi al loro rientro è sufficiente fare l' inizializzazione
e metterli di nuovo in attesa di richieste da parte degli utenti
del servizio.
Lo stesso discorso fatto
qui è valido anche per i server replicati delle varie ditte.
Per quanto di riguarda la
modalità di gestione delle informazioni si possono scegliere diverse
alternative eseguibili con politiche molto diverse fra loro : ad esempio
è possibile tenere in memoria virtuale i dati dei client caricandoli
da programma ogni volta che viene fatta partire l' applicazione e aggiornarli
in tempo reale secondo le richieste fatte dai clienti , così facendo
però , una volta terminata l' applicazione le modifiche apportate
fino a quel punto dall' evoluzione dell' intero sistema , andranno perse
e riavviando il server in un secondo momento ci si ritroverà nella
situazione di partenza iniziale , quella che è stata decisa durante
la stesura del progetto. Questa soluzione non è molto accettabile
anche considerando il fatto che una momentanea caduta di questo server
resetterebbe inevitabilmente ogni volta il sistema. E' quindi necessario
pensare ad una soluzione in cui i dati forniti dai clienti possano essere
reperiti anche in sessioni di lavoro successive. Per realizzare una sorta
di database è possibile usare veri e propri sistemi che gestiscono
questo tipo di informazioni come il linguaggio Oracle o SQL e le loro funzioni
per reperire dati , o più semplicemente si potrebbe implementare
questi archivi con dei file che verrebbero memorizzati su di un supporto
stabile. In questa prima versione del progetto mi limito quindi ad implementare
gli archivi con semplici file.
Quando si deve verificare l' identità
di un cliente con il suo codice viene aperto il file "codici.data"
, se viene trovato in questo file un cliente con nome e codice corrispondenti
a quelli ricevuti via server si invia come risposta l' elenco delle ditte
che possiede questo cliente.
Invece quando deve essere registrato
un ordine si apre in scrittura un file specifico per il cliente e
la ditta in questione posizionandosi alla fine , in modo da
non sovrascrivere informazioni già esistenti , e vengono registrati
tutti i dati relativi all' ordine. Quando sono richieste informazioni sugli
ordini fatti viene aperto il file desiderato in lettura e vengono spediti
al server che ha fatto la richiesta , tutti gli ordini che sono presenti.
Si presenta però il problema
di come memorizzare nuovi dati : bisogna decidere per quanto tempo tenere
il file aperto , decidere cioè , se è più conveniente
tenere aperto il file e registrare man mano i dati inviati per chiuderlo
e aggiornarlo in memoria stabile alla fine di una sessione di interazione
con un client (write-on-delay), oppure se registrare e chiudere subito
il file all' arrivo di ogni singolo ordine applicando così la politica
write-through. Questa seconda scelta risulta essere la più conveniente
in quanto si limita il numero di file aperti e inoltre si limita il rischio
di imbattersi in interferenze a causa di più scritture sullo stesso
file. Il problema delle interferenze può rimanere se consideriamo
il fatto che due clienti , identificatisi con lo stesso nome , provino
a registrare un ordine allo stesso tempo ; considerando questo caso , per
non incorrere in errori , si potrebbe pensare di accedere ai file tramite
un semaforo che ne vieti l' accesso se tale file è stato già
aperto da un altro utente. Considerando il fatto però che un cliente
debba identificarsi anche tramite un codice che dovrebbe essere segreto
ipotizziamo che due clienti distinti non possano accedere allo stesso file
, il nome di questo infatti è proprio costituito in parte dal nome
del cliente.
L' unico campo che compare nella
finestra di inizializzazione di questo server e quello che determina la
porta riservata a ricevere richieste di decodifica dei pezzi che inviano
i clienti tramite i due server ditta replicati.
Inizializzato questo server, ci
si porrà in attesa di richieste secondo lo stesso protocollo che
adotta il server database generale per il caso di connessioni non affidabili.
Ricevuto un codice questo server lo confronta con tutti quelli che sono
registrati in un file che rappresenta l' intero catalogo che possiede la
ditta in questione. Se questo codice è presente allora viene rispedita
una risposta contenente la descrizione e il prezzo corrispondente al codice
altrimenti viene fornita una risposta negativa.
E' invece necessario un altro
administrator che gestisca le informazioni riguardanti i codici dei clienti
e inoltre questo gestore deve anche trattare e definire quali ditte può
contattare ogni singolo cliente , fornendogli , quando richieste , tutte
le informazioni necessarie per poter stabilire delle connessioni con i
server di queste aziende. Quando viene registrato un cliente deve essere
inserito un nome e un codice i quali non devono essere uguali a quelli
già presenti nell' archivio ; inseriti nome e codice corretti viene
scandito per il nuovo cliente l' elenco delle ditte registrate nel database
chiedendo per ciascuna di esse se il cliente in considerazione debba esservi
registrato. Quando invece viene registrata una nuova ditta , oltre al nome
, devono essere forniti i nomi degli host e i numeri di porta dei due server
replicati che ricevono le richieste per la ditta in questione ; il nome
che la identifica deve essere unico e una volta registrata correttamente
, viene , questa volta , scandito l' elenco dei clienti presenti nell'
archivio chiedendo , per ciascuno di essi , se si vuole registrarli per
quella ditta.