- INTRODUZIONE
- DESCRIZIONE GENERALE DELLE SPECIFICHE DI PROGETTO
- SCHEMA DI REALIZZAZIONE
- IL SERVER DNS
- L'OPERATOR SERVER
- IL SERVER FILIALE
- IL CLIENT
- PROBLEMI RISCONTRATI IN FASE DI PROGETTAZIONE
- PROBLEMI NON RISOLTI IN QUESTA IMPLEMENTAZIONE
- CONCLUSIONI ,POSSIBILI SVILUPPI .
INTRODUZIONE.
Il progetto che abbiano deciso di realizzare è un sistema informatico per la gestione di un insieme di filiali bancarie a cui un utente può collegarsi in maniera remota per effettuare operazioni di versamento e prelievo proprio come avviene in un BANCOMAT.
Tale realizzazione deve tenere conto della possibilità di alcuni nodi di cadere e cercare di garantire sempre un servizio efficace.
La realizzazione di questo software prevede una diffusione delle filiali a livello nazionale si dovrà quindi cercare di realizzare delle politiche di gestione del carico di lavoro sui vari nodi e valutare la realizzazione di soluzioni quanto più scalabili possibili.
Le specifiche sostanzialmente non sono cambiate in maniera sostanziale rispetto alla prima fase di realizzazione , certo è che durante la parte di implementazione software vera e propria si sono dovute rivedere alcune delle specifiche realizzative per rendere più abbordabile sia in termini di costo (misurato come tempo di realizzazione) sia in termini di efficienza il prodotto finito.
Descrizione generale delle specifiche di progetto.
Ecco quali sono stati gli obbiettivi fondamentali di questo progetto software:
- TOLLERANZA AI GUASTI:
una delle caratteristiche che questo software si propone è quella di risultare relativamente sicuro in prospettiva del verificarsi di guasti su alcuni dei propi nodi potendo sempre fornire un servizio affidabile. La soluzione per fornire un servizio affidabile è quella di replicare le risorse . Per motivi del tutto pratici si è introdotta l'ipotesi semplificativa non realistica di guasto singolo , in modo da poter realizzare soltanto due copie di ogni risorsa. Rispetto alle specifiche di progetto originale è stata introdotta un'ulteriore ipotesi :le filiali che rappresentano I nodi terminali dei server in quanto contengono le informazioni di carattere più specifico (I singoli conti correnti) ,e di accesso e modifica più frequente non possono essere duplicate su rete, si pensa quindi per motivi di efficienza che il problema dell'affidabilità sia risolto in maniera locale, con una replicazione della memoria permanente (DISCHI RAID) e delle linee di rete. Risolvere il problema con replicazione su nodi remoti significherebbe introdurre un OVERHEAD comunicativo insostenibile duplicando e a volte triplicando il traffico di rete.
- ATOMICITA' DELLE TRANSAZIONI:
realizzare il concetto di atomicità della transazione era stata una delle specifiche introdotte in fase di analisi del problema , lasciando al protocollo la soluzione. Realizzare però un protocollo che potesse garantire questo concetto si è rivelato molto oneroso in termini di tempo e di costi , risultato che si è pensato che il problema venga risolto non attraverso il protocollo di rete ma attraverso metodi diversi più tipici dei sistemi informativi. (Il file di LOG ad esempio).
- SICUREZZA:
uno dei principali obbiettivi che un sistema bancario dovrebbe porsi è quello di realizzare un sistema sicuro sia in termini di controllo degli accessi sia in termini di controllo dei diritti sull'utilizzo delle risorse(CHI HA IL DIRITTO DI MODIFICARE UN CONTO CORRENTE?), tale obbiettivo però non rientra nelle specifiche di progetto e si ipotizza che il nostro sistema lavori in un'ambiente sicuro e fidato ,dove ogni accesso sia fatto da persone autorizzate e competenti.
- SCALABILITA' :
il problema della scalabilità della soluzione adottata e quindi dell'efficienza della mia implementazione è sicuramente un problema centrale del mio progetto avendo come specifica quella di servire un territorio piuttosto ampio. Per realizzare la scalabilità occorre che ogni nodo lavori nella maniera più locale possibile , e quindi su un numero limitato di possibili clienti. Per fare ciò si è realizzata una gerarchia di nodi ognuno dei quali ha visibilità soltanto dei dati immediatamente al disotto .Strettamente legato al problema dell'efficienza è anche il concetto di ripartizione del carico sui vari terminali . In fase di analisi si era pensato di realizzare una soluzione di ripartizione dinamica del carico di lavoro sui vari nodi in modo che ognuno avesse un uguale numero di utenti sui quali lavorare. Una soluzione di questo tipo però richiedeva a priori l'introduzione o di un nodo che conoscesse tutti gli altri oppure di un carico di comunicazione tra nodi per rimpallarsi il cliente , e d'altro canto in ogni caso non si sarebbe riusciti ugualmente a prevedere l'entità del carico presente sulla rete essendo di per se non note a priori le operazioni che un singolo cliente potrebbe fare. Si è pensato allora ad una soluzione di bilanciamento del carico STATICO , ogni nodo dal grado più alto della gerarchia a quello più basso lavora su una porzione specifica del territorio nazionale. Questa soluzione che di per se si presenta meno "GIUSTA" rispetto ad una soluzione dinamica potendo a seconda delle differenti situazioni privilegiare alcuni nodi ,senza lavoro rispetto ad altri sovraccarichi, elimina però un notevole carico comunicativo e di coordinamento.
- PORTABILITA' :
il problema di realizzare una soluzione software portabile e mutlipiattaforma è stato risolto attraverso l'utilizzo di un linguaggio di programmazione come JAVA. Tale soluzione va contro alle specifiche di efficienza che si propone il progetto ,essendo infatti JAVA notevolmente più inefficiente di linguaggi come il C ad esempio ma ha risposto bene alle specifiche di progetto. Per collaudare la soluzione il software è stato fatto girare su piattaforme di tipo UNIX e PC WINDOWS 98.
- INTERFACCIA UTENTE:
l'utente finale doveva essere supportato nell'operazione di connessione e di trasferimento , per tale motivo si è introdotto una componente di interfaccia grafica attraverso la quale l'utente può colloquiare con il sistema senza dover conoscere alcuna specifica.
- GESTIONE DELLA MOBILITA':
la gestione della mobilità che era una delle caratteristiche della prima fase di progetto viene in questo contesto leggermente trascurata, un nodo deve conoscere l'indirizzo del nodo con cui comunicare, in particolare il server dns deve restare fissato . Tale soluzione risulta più limitativa rispetto a quella originale che prevedeva la possibilità di ogni nodo di migrare sulla rete , tolgie però una notevole quantità di OVERHEAD comunicativo anche in considerazione del fatto che I nodi server sono FILIALI BANCARIE o SERVER DNS quindi oggetti che difficilmente modificano spesso il proprio indirizzo di rete. Per tale motivo si è reputato sufficiente la possibilità di riconfigurare manualmente la rete.
SCHEMA DI REALIZZAZIONE.
Lo schema realizzativo si mantiene fedele a quello proposto nella fase di analisi, in particolare non viene modificata l'organizzazione di tipo gerarchico e la visibilità fra le varie strutture.
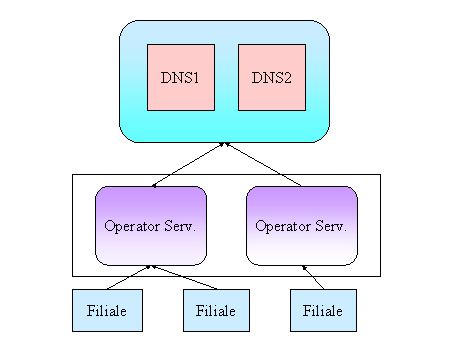 Come si può notare la replicazione è realizzata soltanto per le strutture dati DNS e OPERATOR, d'altronde tali nodi sono quelli presenti al TOP della gerarchia , una loro defezione renderebbe inutilizzabili anche I nodi al disotto, e soprattuto per queste strutture si suppone poco frequente l'introduzione di una nuova filiale , (vorrebbe dire costruire una nuova BANCA!!!!) e quindi poco frequenti eventuali aggiornamenti.
Come si può notare la replicazione è realizzata soltanto per le strutture dati DNS e OPERATOR, d'altronde tali nodi sono quelli presenti al TOP della gerarchia , una loro defezione renderebbe inutilizzabili anche I nodi al disotto, e soprattuto per queste strutture si suppone poco frequente l'introduzione di una nuova filiale , (vorrebbe dire costruire una nuova BANCA!!!!) e quindi poco frequenti eventuali aggiornamenti.
Le strutture dati delle filiale sono invece piuttosto cospicue, rappresentano I conti correnti dei clienti e soggetti a migliaia di transazioni ogni giorno, risulta quindi accettabile eventualmente negare il servizio ad un numero ristretto di clienti per qualche ora piuttosto che ritardare le operazioni di tutti (del resto è ciò che accade nella realta!!!!!!!!!!).
Il rapporto di comunicazione avviene soltanto tra pari o immediatamente inferiori o superiori, mentre la visibilità è limitata al proprio nodo pari e ai nodi figli.
NON ESISTE IN QUESTO SCHEMA UN NODO CHE CONOSCE TUTTI GLI ALTRI , come del resto è plausibile per via dell'impossibilità di gestire strutture dati tanto complesse come sarebbe un'unica banca centralizzata per l'intero suolo nazionale.
IL SERVER DNS.
Il server DNS è realizzato in due copie , ognuna delle quali è attiva su una partizione distinta di operator server che si registrano fornendo il nome di una città e l'indirizzo IP equivalente.Le operazioni che deve svolgere il server DNS sono le seguenti:
- Fornire risposte alle interrogazioni da parte del cliente.
- Mantenere una tabella per I propri O_S
- Mantenere una tabella di backup per il server DNS gemello
- Fornire le modifiche al server dns gemello
- Ascoltare le modifiche del server dns gemello
- Mantenere una eventuale tabella di backup per il server O_S eventualmente gemellato
- Ascoltare eventuali modifiche fornite dal server O_S gemellato.
- Mantenere traccia dell'indirizzo del server O_S
- Gestire inserimento dei server O_S con eventuale scelta del gemello.
- Reeboot in caso di CRASH registrandosi nuovamente al DNS gemello e riimmagazzinando le strutture dati perdute.
Tali funzionalità devono essere svolte dal server in modo del tutto parallelo, esso deve poter gestire le varie tabelle ,le richieste del cliente senza dover attendere sequenzialmente, tale funzionalità è resa dalla possibilità in JAVA di realizzare il MULTITHREADING .
A questo punto però si pone il problema di coordinare l'accesso alle risorse , tali parti di codice infatti rappresentano delle regioni critiche , tale soluzione è resa in JAVA attraverso l'utilizzo di particolari funzionalità implementate dall'interfaccia SYNCHRONIZED.
Vediamo ora In dettaglio l'implementazione del server dns.
LE STRUTTURE DATI
Ogni DNS manipola tre diverse strutture dati ,che devono contenere dei MATCHING nome-indirizzo IP ,tali strutture che nella nostra implementazione sono mantenute in memoria volatile ma che nella realtà dovrebbero essere quantomeno salvate su memoria di massa , trovano una facile ed efficiente implementazione in JAVA attraverso la classe HASHTABLE che realizza un'associazione automatica NOME-OGGETTO.
Ogni server DNS dovrà quindi manipolare 3 hashtable contenenti I propri dati , I dati del DNS gemello ed I dati relativi al O_S generato. Le tre tabelle quindi conterranno dati del medesimo tipo coè indirizzi IP, anzi in paricolare una classe creata da me e denominata ADDRESS.
Nella figura sopra riportata è possibile vedere la struttura interna del server DNS.
In particolare vengono evidenziati I vari processi THREAD che realizzano I servizi messi a disposizione dal software in esame.
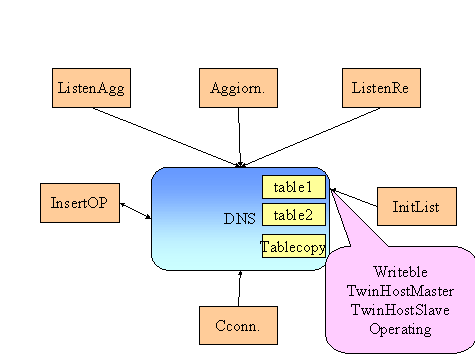
Le funzionalità del server DNS primario devono essere garantite anche in caso di guasto per questo esso è realizzato in due copie delle quali una è il Backup dell'altra e si comportano come MASTER rispettivamente ognuna di una propria partizione. Queste due copie devono comunicarsi tra loro I singoli cambiamenti ed inserimenti di O_S in modo da mantenere coerenti le due tabelle.
Per questo esiste un processo THREAD che si incarica proprio di fare questo , cioè comunicare con il DNS gemello ed inviargli notifica di ogni cambiamento . Esiste poi anche un processo del tutto duale che si occupa di ascoltare tali messaggi e di aggiornare la tabella di BACKUP.
IL REINSERIMENTO DEL DNS A FRONTE DI UN CRASH.
Dopo che è avvenuto un crash del sistema il server deve essere in grado di riprendere le proprie funzionalità, in particolare deve poter riaquisire la conoscenza riguardo alle proprie tabelle , esistono pertanto due processi che si incaricano di effettuare tale compito, il primo comunica con l'altro DNS e gli domanda le tabelle (potrebbe mantenere memoria della tabelle e inviare la richiesta soltanto per un'eventuale aggiornamento ma ciò per semplicità non è previsto) ed un'altro processo che si incarica di effettuare l'init della tabella di copy cioè il BACKUP del O_S (vedi oltre) .
IL SERVIZIO OFFERTO AI CLIENTI
Il server a fronte di un'interrogazione da parte del cliente deve interrogare la propria tabella MASTER oppure la tabella SLAVE a seconda che la richiesta provenga da un cliente della propria partizione oppure da un cliente di una partizione appartenente al DNS gemello, tale informazione è specificata dallo stesso client all'atto della richiesta.
In questo senso occorre specificare due caratteristiche del progetto:
-il server può in questa fase anche ignorare che il proprio server gemello sia o meno in vita, non esiste infatti nessun motivo per cui ne conosca la situazione liitandosi ad inviare la risposta che possiede.
-il server non ha alcuna idea di quale sia la sua partizione di appartenenza nella quale schedare I vari O_S , sono gli stessi O_S che fanno richiesta per una o per l'altra .
LA GESTIONE DEI GEMELLI PER GLI O_S.
Il server si deve incaricare tra l'altro di realizzare l'assegnamento del gemello per ogni O_S. Tale operazione è svolta in maniera sequenziale formando le coppie man mano che queste di presentano ,ed in caso questi ultimi siano in numero dispari fornendosi di fare da BACKUP momentaneo.
Il server DNS mantiene quindi un'ulteriore struttura dati che è una copia della tabella posseduta dal O_S virtualmente gemellato con lui.
OPERATOR SERVER.
La struttura degli OPERATOR SERVER è sostanzialmente identica a quella del server DNS come sono del tutto identiche le operazioni che questo deve effettuare .
Le uniche differenze significative sono l'assenza della terza tabella di BACKUP virtuale in quanto non è prevista duplicazione per I nodi filiale , e quindi anche l'assenza del processo adibito alla gestione del gemello.
Vediamo uno schema di realizzazione del mio OPERATOR SERVER.
 LA FASE DI REBOOT.
LA FASE DI REBOOT.
Nella fase di REBOOT il mio Operator Server deve poter conoscere se è la prima volta che è attivato oppure se è già stato attivato ed in questo caso con quale processo risulta gemellato.
Per fare ciò si è scelta la strada di utilizzare il file System della macchina come memoria permanente , quindi nella fase di reboot il mio Operator interroga il file e scopre indirizzo e porta del mio processo gemello, a questo punto invia un messaggio e si fa consegnare aprendo una connessione TCP /IP le tabelle dati.
Qualora il SERVER OPERATOR caduto sia gemellato con il DNS al fine che quest'ultimo non perda la traccia della tabella e del gemello , si prevede blocchi la possibilità di scrittura .
IL SERVER FILIALE.
Il server filiale è un semplicissimo server che si mette in ascolto della connessione da parte di un cliente e a fronte di una connessione , crea un processo THREAD che si occupa della gestione della richiesta da parte del cliente.
La filiale manipola delle strutture dati di tipo conto corrente organizzate in HASH TABLE dove la chiave di ricerca risulta il nome del cliente stesso.
Soltanto la FILIALE ha la possibilità di creare un nuovo conto corrente e su questo mette a disposizione 3 operazioni , deposito, prelievo ,lista movimenti.
Abbiamo già detto che per la mia FILIALE non è prevista duplicazione , si ritiene quindi accettabile che in un determinato momento un cliente non possa effettuare operazioni bancarie.
Tale scelta è stata dettata dalla considerazione che mantenere in rete due copie di una risorsa FILIALE sarebbe risultato troppo oneroso in termini di comunicazione e coordinamento tra I server per mantenere coerente la tabella. Non di meno si sarebbe dovuta gestire anche tutto il problema della TRANSAZIONE , considerando che un guasto può avvenire in un qualunque momento e che quindi si sarebbero dovuti prevedere delle fasi di controllo ed eventualmente di ABORT dell'operazione , richiedendo quindi un prodotto software di notevole complessità.
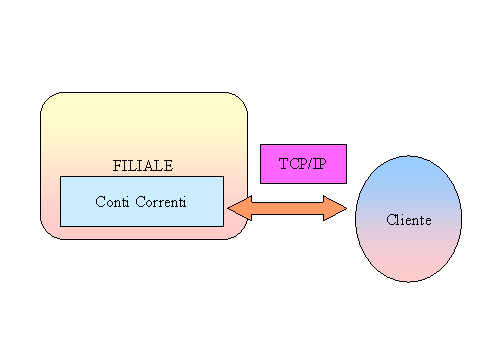 IL PROCESSO CLIENTE
IL PROCESSO CLIENTE
Si assume che il processo cliente debba essere quanto più possibile trasparente nella gestione della comunicazione . Per tale motivo il cliente deve conoscere soltanto l'indirizzo di partenza ossia quello del DNS , la propria città e la filiale a cui è interessato. Tali informazioni è ragionevole siano conosciute da un utente che si voglia collegare via rete alla propria banca.
A questo punto non si richiede nient'altro , vengono consultati in sucessione I server DNS primario ( e secondario se il primario è in CRASH ) , l'operator server ed infine viene stabilito un canale con la mia filiale , ora ho accesso al conto corrente che ho richiesto , e su questo posso chiedere di effettuare un prelievo un deposito o di visualizzare la lista delle transazioni effettuate.

LA SCELTA DEI PROTOCOLLI.
I protocolli utilizzati nella progettazione software sono piuttosto diversi da quelli proposti in fase di analisi. In particolare nella fase di analisi si era ipotizzato di utilizzare una comunicazione di tipo UDP per realizzare gran parte delle comunicazioni. Tale proposta era stata dettata dalla considerazione che essendo UDP un protocollo più "leggero" si sarebbero ottenute prestazioni decisamente migliori. UDP però essendo un protocollo di trasferimento dati non sicuro doveva essere supportato da protocolli di livello più alto che mettessero in conto una possibile defezione della rete , quindi la possibilità di perdere messaggi o di riceverli alterati o nell'ordine non prescritto. Tali protocolli dovevano quindi prevedere scambi di messaggi di tipo REQ , RISP ,ACK
E l'introduzione di messaggi di fallimento e di ulteriore richiesta corredando il tutto con opportuni timeout.
Passando alla fase implementativa si è visto che nella situazione favorevole , cioè tutti I messaggi andavano a buon fine si ottenevano tempi decisamente buoni ma che qualora anche soltanto uno dei messaggi fosse perso oppure fosse intervenuto un piccolo ritardo della rete , I tempi andavano nettamente peggiorando.
Si è allora provato di implementare il tutto con u semplice protocollo TCP/IP , nettamente più oneroso a basso livello , dando però la possibilità ad alto livello di creare protocolli snelli di tipo richiesta attesa della risposta e lasciando al sistema il problema del controllo dell'integrità del messaggio stesso.
A questo punto si è verificato che se in situazione normale I tempi di comunicazione risultavano leggermente peggiori anche se non di molto la situazione restava sostanzialmente stabile lungo tutto l'arco della comunicazione. In questo modo si ottengono tempi medi decisamente migliori rispetto alla comunicazione UDP .
Tutti le comunicazioni avvengono allora attraverso l'utilizzo di TCP a basso livello e di protocolli snelli di tipo request-reply ad alto.
Tanto più che utilizzando le socket TCP in JAVA è possibile inviareinteri oggetti all'altro pari nella comunicazione , lasciando alla JAVA VIRTUAL MACHINE il compito di effettuarne la serializzazione.
PROBLEMI E LIMITI DEL SOFTWARE.
Per quanto riguarda la fase di collaudo del software , esso sembra rispondere abbastanza bene a fronte di un guasto su un nodo della rete , e anche all'eventuale reinsermento.
Il problema fondamentale è che il guasto deve risultare unico su tutta la rete ,non è infatti previsto che si possano guastare assieme ad esempio DNS e O_S .
Un'altro problema è la gestione del guasto del DNS