Nello sviluppo del prototipo del sistema in oggetto si sono trascurati gli aspetti di tipo applicativo per focalizzare e studiare maggiormente le problematiche di comunicazione e coordinamento.
L'intero sistema è stato progettato usando metodi object oriented ed implementato in linguaggio Java utilizzando il Java Development Kit versione 1.2.2 di Sun.
L'utilizzo del framework Java si è rivelato un'ottima scelta per lo sviluppo rapido del prototipo. La metodologia di sviluppo e testing seguita è stata di tipo bottom-up. Si è proceduto per aggregazione di componenti Java realizzati e testati fin dalle prime fasi. Per facilitare il testing e il debugging, per ogni classe, si è provveduto a ridefinire il metodo java.lang.Object.toString().
Ad ogni classe si è aggiunto inoltre un metodo public static main(String[])per renderla un'applicazione stand-alone e testarla prima di integrarla nel sistema. Per alcune classi si è poi implementata l'interfaccia java.lang.Runnable per effettuare testing in ambiente multithread.
Per le operazioni di testing dell'intero sistema è stato necessario realizzare alcune classi dedicate al monitoraggio dello stato delle applicazioni. La struttura multithread dei Replica Manager e la complessità dello stato e delle operazioni richieste dall'algoritmo gossip, hanno portato allo sviluppo di due classi specifiche per il testing : RMMonitor e Output. La classe denominata RMMonitor è un thread con il compito di visualizzare periodicamente lo stato di un Replica Manager in una finestra grafica dedicata. La classe Output è invece un'interfaccia grafica costituita da una finestra con quattro pannelli di dimensioni variabili all'interno dei quali i vari thread di un Replica Manager dirigono i messaggi di debugging. Separando l'output in quattro pannelli, si possono seguire tutte le fasi dei protocolli di comunicazione e di coordinamento. Entrambe le interfacce grafiche sono basate sul package javax.swing.
L'entità Replica Manager è stata implementata come un'applicazione Java multithread. Ha il compito principale di fungere da server concorrente nei confronti dei Front End realizzando il servizio di bulletin board. Ogni Replica Manager interagisce strettamente con i suoi pari come sarà dettagliatamente descritto nel paragrafo 2.4.3 - Meccanismo di coordinamento.
Nella sua prima forma prototipale, il servizio di bulletin board presenta le funzionalità di base necessarie per soddisfare i requisiti. Queste funzionalità sono state mappate in un'interfaccia denominata News della quale esistono due implementazioni: NewsSet e BoundedNewsSet. Si rimanda alla documentazione javadoc per i dettagli.
Ogni Replica Manager deve possedere staticamente un minimo di conoscenza della configurazione del sistema per poter predisporre opportunamente le strutture dati necessarie al coordinamento con gli altri. E' necessario che conosca il numero di suoi pari presenti e il suo identificativo. E' possibile predisporre staticamente la topologia di interconnessione dei Replica Manager rendendo noti ad ognuno gli indirizzi IP dei pari con cui potrà scambiare gossip message. Tutti questi parametri di configurazione ed altri di più basso livello sono settabili dalla linea di comando dell'applicazione e attraverso l'uso di un file denominato "config.properties". La classe RMSetup ha il compito di analizzare la linea di comando e il file, per configurare staticamente un Replica Manager all'atto della messa in opera.
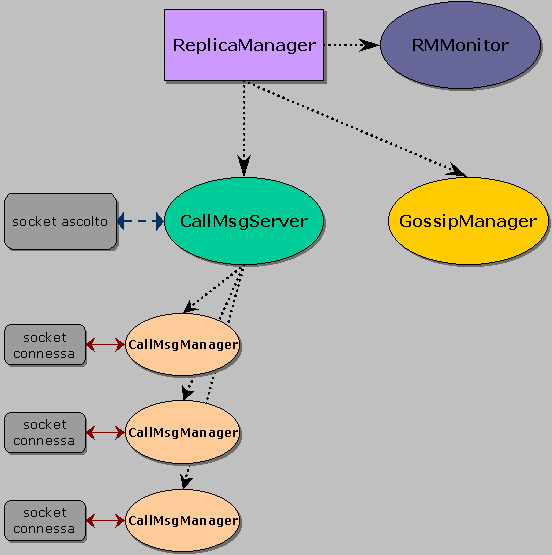
La classe ReplicaManager è composta da un unico metodo main che si occupa di invocare RMSetup, di creare l'interfaccia grafica Output e di istanziare ed avviare i thread che realizzano il servizio concorrente. La figura seguente mostra i thread attivati da ReplicaManager.
Per la comunicazione con i Front End si utilizza una connessione reliable basata su socket stream. Un thread denominato CallMsgServer è posto in ascolto su di una porta nota ai Front End ed ha il compito di creare ed avviare nuovi thread CallMsgManager per ogni nuova connessione.
Ogni thread CallMsgManager si occupa di servire tutte le richieste che il Front End con il quale comunica gli invia. Il protocollo di comunicazione a livello applicativo è di tipo domanda/risposta ed è basato sullo scambio di oggetti serializzati. Questa scelta, forse penalizzante dal punto di vista delle prestazioni, è stata favorita dalla semplicità e dal grado di astrazione fornito dai meccanismi di serializzazione degli oggetti del linguaggio Java.
Stabilita la connessione con un Front End, il protocollo ha inizio con la ricezione di un oggetto Comando che contiene una richiesta di servizio. Ogni thread CallMsgManager esegue un ciclo di attesa comando, esecuzione comando fino a che il Front End non chiude la connessione oppure non si verifica un errore. Gli errori di protocollo a livello applicativo e le eccezioni dovute alla comunicazione, sono trattati chiudendo la connessione con il Front End.
Di seguito si dà una descrizione delle operazioni che un Front End può richiedere ad un Replica Manager attraverso l'invio di un oggetto Comando. La classe Comando contiene al suo interno un intero che identifica l'operazione richiesta. Tale intero deve essere obbligatoriamente uguale ad una delle costanti di classe Comando.LIST, Comando.GET, Comando.PUT, Comando.ACK, Comando.NUM o Comando.LOOKUP (si rimanda alla documentazione javadoc per i dettagli sulla costruzione di un oggetto Comando). La classe Comando ha anche un altro attributo: il multipart timestamp del Front End associato all'operazione. Tale multipart timestamp è significativo solo per le operazioni LIST, GET E PUT. Il protocollo si dirama a seconda del tipo di richiesta inviata al Replica Manager, cioè a seconda del tipo di comando.
- esecuzione della query;
- invio del multipart timestamp val_ts di risposta;
- invio di un intero N che rappresenta il numero di intestazioni presenti nel bulletin board e che saranno restituite;
- se N > 0 invio delle intestazioni una alla volta come oggetti MsgHeader.
- lettura di un oggetto MsgHeader che rappresenta l'intestazione argomento della query;
- esecuzione della query;
- invio di un intero che indica se l'intestazione esiste o no (costanti ReplyCodes.OK e ReplyCodes.MSG_NOT_FOUND);
- se l'intestazione esiste, si invia l'oggetto MsgBody corrispondente al risultato della query e di seguito il multipart timestamp val_ts di risposta.
- lettura di un oggetto Messaggio;
- lettura di un oggetto cid che identifica univocamente l'operazione di posting;
- esecuzione dell'operazione di posting;
- invio del multipart timestamp di risposta val_ts.
- lettura di un oggetto Cid che identifica l'operazione di posting a cui si riferisce l'ack;
- esecuzione dell'operazione.
- invio di intero che rappresenta il numero di Replica Manager presenti nel sistema.
- invio di un intero K che indica quanti altri Replica Manager conosce (escluso se stesso);
- se K > 0 invio di K oggetti java.net.InetAddress che rappresentano gli indirizzi dei pari noti.
L'esecuzione delle operazioni di tipo query, update e ack avviene completamente all'interno di metodi di CallMsgManager e rispecchia l'algoritmo descritto nel paragrafo 2.3 - Protocollo di coordinamento.
Nel caso un’operazione non possa essere eseguita immediatamente perché lo stato del Replica Manager non è sufficientemente aggiornato, sono possibili due comportamenti diversi: attesa attiva dell’aggiornamento da un gossip message (il thread si sospende per un intervallo di tempo prima di ritestare se può eseguire l’operazione bloccata) o gossip by need. Il gossip by need consiste nell'invio di un gossip message al Replica Manager che, dai multipart timestamp presenti nella ts_tabel, risulta più aggiornato. E’ possibile scegliere uno dei due metodi e la durata della sospensione nel caso dell’attesa attiva settando gli opportuni parametri del file di configurazione o della linea di comando.
Le strutture logiche necessarie sono state implementate mediante classi Java definendo le operazioni su di esse come metodi, in stile object oriented. Manipolazioni complesse degli insiemi log e inval necessarie nell'esecuzione di un'operazione di posting sono state nascoste in metodi semplificando notevolmente il codice. In questo modo si sono anche superati brillantemente i problemi di accesso in mutua esclusione dovuti alla natura concorrente dei Replica Manager. Le corse critiche sulle strutture dati condivise da più thread sono state eliminate usando i monitor forniti dal linguaggio Java (costrutto synchronized) e cercando, dove possibile, di ottimizzare la concorrenza.
Gli insiemi descritti nell'algoritmo gossip sono stati implementati usando il Collection Framework fornito dal jdk1.2.2 di Sun.
Tutte le strutture citate nell'algoritmo e tutti i parametri che caratterizzano un Replica Manager sono stati inglobati in una classe denominata StatoRM.
Per i dettagli relativi all'implementazione degli insiemi log, inval, degli elementi log-record, ack-record, update-record e multipart timestamp, si rimanda alla documentazione javadoc (classi Log, Inval, LogRecord, AckRecord, UpdateRecord, MultipartTimestamp). La stessa documentazione riporta anche alcuni problemi di sincronizzazione e le soluzioni adottate per la classe CallMsgManager (vedi metodo CallMsgManager.processAck()).
Lo scambio di messaggi gossip è il metodo con cui i vari Replica Manager si coordinano. L’architettura generale del sistema non specifica quando devono essere scambiati tali messaggi e lascia quindi ampia libertà di scelta nell’implementazione (frequenza degli aggiornamenti, gossip by need o periodico, ecc..).
Tipicamente un messaggio gossip consiste di due parti: timestamp e log del Replica Manager che funge da talker nella comunicazione. In realtà, l’insieme log viene preso in considerazione dal Replica Manager ricevente solo se il timestamp remoto è maggiore dell’ultimo valore conosciuto. Siccome la scelta implementativa per la comunicazione tra i vari Replica Manager era già orientata verso un supporto di tipo socket stream, si è pensato di articolare un minimo questo protocollo in modo che fosse il ricevente a richiedere o meno l’invio del Log dopo avere valutato il timestamp ricevuto.
Il protocollo di gossip è iniziato da un talker che si connette sulla porta gossip del Replica Manager con cui si vuole coordinare. La prima azione che il talker effettua è quella di mandare al ricevente (che sarà un replier sulla macchina remota) il suo numero identificativo e il proprio rep_ts. A questo punto il replier remoto confronta il multipart timestamp ricevuto con quello precedente di cui era a conoscenza. Se non ci sono cambiamenti, esso invia sulla connessione il codice GossipCodes.OK_ALREADYUPDATE, altrimenti richiede esplicitamente un gossip mandando un GossipCodes.OK_SENDGOSSIP. Il talker che ha iniziato la comunicazione serializza il proprio log e lo invia al Replica Manager remoto solo se riceve un GossipCodes.OK_SENDGOSSIP, altrimenti non intraprende nessuna azione. Si è così realizzata la prima metà del protocollo di coordinamento; a questo punto i ruoli si invertono ed è il replier che invia al talker i propri dati. Bisogna notare che il Replica Manager su cui gira il talker sa già chi è la sua controparte remota, per cui il replier non ha bisogno di inviare il proprio codice identificativo assieme al multipart timestamp. Il resto è perfettamente simmetrico, fino al termine della connessione che avviene dopo l’invio del log da parte del replier, se questo è richiesto, altrimenti alla ricezione da parte del replier del comando GossipCodes.OK_ALREADYUPDATE.
Una cosa da notare è che questo meccanismo di coordinamento è bidirezionale nel senso che il Replica Manager che ha ricevuto un messaggio di gossip, una volta terminata l’elaborazione locale, invia le informazioni necessarie per risalire al proprio stato; il tutto nell’ambito di un’unica connessione.
Si riassumono brevemente le elaborazioni locali che vengono svolte all’arrivo di un gossip:
Si è detto che l’architettura gossip prevede un coordinamento lazy tra i Replica Manager, nel senso che i messaggi potrebbero essere scambiati solo occasionalmente, dopo un determinato intervallo di tempo o dopo un numero prestabilito di update, oppure ancora quando un Replica Manager si accorge di avere bisogno di un update che è stato mandato a qualcun altro e di cui necessita per portare a termine una richiesta.
Mantenendo sempre separati i meccanismi dalle politiche, l’obiettivo è quello di realizzare un sottosistema autonomo e parametrizzato per quanto riguarda il coordinamento periodico tra i Replica Manager ma che lasci la possibilità di scatenare dall’esterno il meccanismo di gossip in seguito ad un’esplicita richiesta.
Le relazioni esistenti tra le classi Java che implementano il sottosistema di coordinamento sono illustrate in figura.
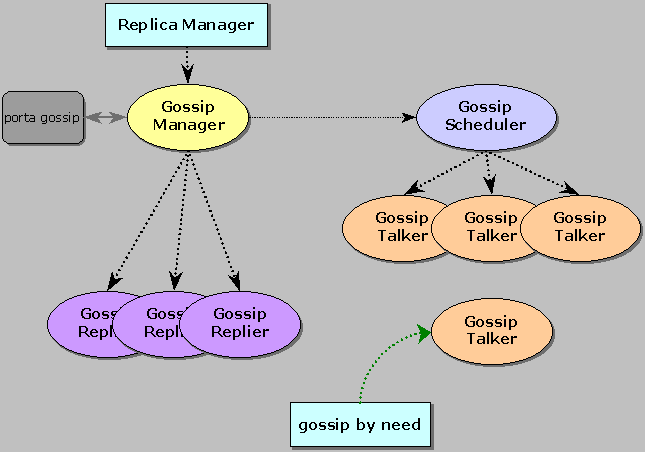
Dal punto di vista dell’applicazione, l’unico oggetto da istanziare è il GossipManager: esso si occupa di organizzare tutte le relazioni tra i vari thread che concorrono alla realizzazione del coordinamento.
Il GossipManager crea ed avvia un thread GossipScheduler, poi si pone in ascolto sulla porta a cui arriveranno eventuali richieste di gossip. Per ogni richiesta ricevuta, viene istanziato un oggetto GossipReplier, che si occupa di effettuare il coordinamento come accennato sopra.
La parte attiva del sistema è invece costituita dalle classi GossipScheduler e GossipTalker: lo scheduler è un thread che periodicamente assegna ad un talker (creato e avviato) l’identificativo di un certo Replica Manager verso cui effettuare un gossip. Modificando l’implementazione dello scheduler o alcuni parametri caratteristici di impostazione del sistema è possibile intervenire sulle politiche oltre che sui meccanismi di coordinamento.
Il GossipTalker è il componente che realizza il protocollo speculare rispetto al replier; diversamente da quest’ultimo, il GossipTalker possiede un ulteriore metodo che consente a classi esterne al sottosistema di scatenare un gossip on-demand (GossipTalker.doGossip(int)). Tale interfaccia viene utilizzata per fornire il meccanismo con cui può essere implementata la politica di gossip by need.
In [LLSG92] un Replica Manager, allo scadere di ogni intervallo di gossip, effettua il coordinamento con l’intero gruppo dei suoi pari per mezzo di comunicazioni point-to-point.
Nell’ipotesi che i vincoli di aggiornamento dell’applicazione non siano stretti, si è scelto di effettuare il gossip, per ogni intervallo, verso un solo Replica Manager scelto dallo scheduler in base alla propria conoscenza e in modo da bilanciare le richieste.
Siccome l’obiettivo dichiarato del progetto è quello di realizzare un prototipo funzionante su cui sperimentare l’impatto di varie politiche per ottenere coordinamento e availability, non è stata posta particolare enfasi sull’ottimizzazione dell’algoritmo. Ad ogni modo, a differenza di [LLSG92], si è scelto di utilizzare un supporto di comunicazione reliable basato su connessioni stream. Grazie alle features fornite dal Collection Framework del jdk1.2.2 è risultato comodo mantenere l’insieme comp (vedi paragrafo 2.3 - Protocollo di coordinamento) ordinato rispetto ai multipart timestamp dei suoi elementi.
Nello sperimentare soluzioni di interconnessione tra i Replica Manager in cui ogni copia non aveva visibilità di tutte le altre, risulta chiaro che è necessario fornire a ognuno una conoscenza indiretta del timestamp di tutti i suoi pari. Solo in questo modo, infatti, è possibile sapere quando un update presente nel log è stato ricevuto da tutti e può quindi essere eliminato (e non più essere trasmesso ad ogni gossip oltre che occupare memoria locale). Il metodo più immediato per fare questo è quello di trasmettere ogni volta l’intera ts_table (cioè la visione locale dell’ultimo stato noto dei Replica Manager remoti) invece del singolo timestamp locale.
Un’ultima nota riguardo alla sincronizzazione: il fatto di avere thread concorrenti che agiscono sulle medesime strutture dati, porta ad inevitabili corse critiche nell'accesso alle variabili condivise. L’ambiente Java fornisce le strutture ad alto livello che consentono di serializzare l'accesso alle risorse, ma l’overhead da pagare risulta pesante. Si è cercato, dove possibile, di limitare l’introduzione di classi e metodi sincronizzati non strettamente necessari ma per fare questo è stato necessario individuare le possibili corse critiche non solo all’interno del sistema di coordinamento ma anche (e soprattutto) tra i thread di gossip e quelli deputati alla gestione locale del Replica Manager.
Il Front End è realizzato mediante un’applicazione stand-alone ospitata da una macchina a cui devono avere accesso i Client. In alternativa si sarebbero potute fondere le funzionalità di un Front End in una classe da accorpare al codice dei Client. La scelta di usare un processo a sé stante consente di alleggerire il carico dovuto alle applicazioni Client che si suppone siano in numero maggiore rispetto ai Front End.
Fornisce le seguenti funzionalità:
L’applicazione richiede un parametro d’ingresso obbligatorio, corrispondente all’hostname del Replica Manager a cui il Front End si connette inizialmente. Questa connessione è fondamentale (vengono effettuati cinque tentativi di ad intervalli prefissati dopo di che, in caso di fallimento, l’applicazione viene fatta abortire) poiché il Front End deve richiedere al Replica Manager iniziale informazioni determinanti sulla configurazione del sistema. Questo avviene attraverso l’invio e la corrispondente esecuzione dei seguenti comandi:
Una volta inizializzate le opportune strutture dati, al Front End non resta che aprire una socket di ascolto sulla porta opportuna (che ha un numero di default che può essere modificato da linea di comando) e mettersi in attesa di connessioni da parte di Client. La comunicazione con ognuno di essi viene affidata, infatti, ad un nuovo thread FrontEndThread generato dal Front End stesso.
La socket di ascolto è un’istanza della classe java.net.ServerSocket, la quale fornisce il metodo accept che restituisce un oggetto Socket attraverso il quale avverrà la trasmissione dei dati fra il Client accettato e il corrispondente servitore. Quest’ultimo è un oggetto della classe FrontEndThread, attivato mediante il relativo metodo start (ereditato da java.lang.Thread). Un servitore viene creato e immediatamente attivato per ogni Client agganciato. Il corrispondente costruttore riceve in ingresso due parametri: il riferimento al Front End che l’ha generato e quello alla socket restituita dal metodo accept.
Con un approccio di questo tipo, le funzionalità offerte da un’entità Front End (da non confondere con la classe FrontEnd) sono in realtà affidate ad istanze della classe FrontEndThread.
Tale classe realizza lo thread servitore creato e attivato dall’applicazione FrontEnd per soddisfare le richieste di un Client, implementando il protocollo Client-Front End lato Front End e il protocollo Front End-Replica Manager.
Per quanto riguarda quest’ultimo protocollo si rimanda al paragrafo 2.4.2 - Replica Manager in cui è descritto il lato Replica Manager. Il lato Front End è del tutto simmetrico.
All’attivazione del thread vengono eseguite le seguenti operazioni:
Si distinguono in questa fase due diversi comportamenti del sistema in corrispondenza del fatto che ci si trovi in uno stato di fallimento o meno: nel caso in cui l’ultima azione eseguita sia terminata con successo, il thread si pone (come da protocollo) in attesa di un nuovo comando da parte del Client. Altrimenti si cerca di concludere la precedente azione, reinvocando il metodo appena fallito (e comunicando con un altro Replica Manager scelto in base alla politica settata). In ogni caso, non si incomincia alcuna azione finché il numero di Replica Manager potenzialmente disponibili non è superiore a quello desiderato (attributo FrontEnd.FT_COUNT, settato da linea di comando con valore di default 1). La disponibilità di Replica Manager eventualmente necessari, viene ottenuta mediante azioni di lookup (metodo FrontEndThread.lookupAction()).
Alle azioni corrispondenti a comandi inviati dal Client in seguito a richieste dell’utente, se ne aggiunge una relativa all’invio degli ack (vedi paragrafo 2.3 - Protocollo di coordinamento) verso un opportuno Replica Manager.
Queste azioni, implementate all’interno dei metodi sotto elencati, prevedono i seguenti comportamenti comuni:
|
|
|
|
Più volte durante l’esecuzione
di uno thread, in seguito a diversi eventi (problemi di
connessione verso un Replica Manager, motivi di
efficienza, politiche varie) viene invocato il seguente
metodo:
|
Per soddisfare alcuni dei requisiti che il sistema intende garantire (availability, fault tolerance) e prestare servizi discretamente efficienti, il Front End può assumere i seguenti comportamenti.
| Fault tolerance. E’ possibile settare il numero di Replica Manager (FrontEnd.FT_COUNT) a cui un messaggio deve essere postato prima di considerare l'operazione di posting (comando PUT) eseguita con successo. Settando valori maggiori di uno si ottengono operazioni di posting che resistono alla caduta dei Replica Manager. |
| Availability ed efficienza. Per garantire continuità del servizio, in seguito a problemi di connessione con il Replica Manager corrente, viene cercato un nuovo servitore in grado di proseguire le operazioni in corso. Un Replica Manager fra quelli noti al Front End (grazie alle precedenti operazioni di lookup eseguite) viene scelto in modo da favorire:
|
| Efficienza. E’ possibile settare il tempo (FrontEnd.TIME_OUT) oltre il quale un thread in attesa di una risposta da un Replica Manager considera sconveniente continuare ad attendere. Scaduto tale intervallo di tempo si rivolge ad un altro Replica Manager scelto in base a uno fra i suddetti criteri. Il valore di default comporta un'attesa infinita. Fondamentale è la scelta di un timeout opportuno. |
| Conoscenza. Un parametro da settare è il numero di Replica Manager (FrontEnd.LOOKUP_T) che il FrontEnd deve riconoscere come potenzialmente disponibili prima di accettare un comando da un Client. Si invia un comando LOOKUP ai Replica Manager noti finché tale requisito non viene soddisfatto. |
Lato Client:
I Client sono applicazioni Java che comunicano tramite una connessione reliable (socket stream) con il proprio Front End che può o meno risiedere sullo stesso nodo.
All’utente vengono fornite le seguente funzionalità:
I messaggi del servizio di bulletin board sono implementati con oggetti dotati di campi di tipo stringa di lunghezza limitata. L’intestazione è costituita dal nome del mittente, dalla data e dall’ora di pubblicazione e dal subject del messaggio. Il corpo del messaggio è una stringa non strutturata di lunghezza limitata. Per ulteriori dettagli si rimanda alla documentazione javadoc.
L’applicazione Client è costituita da un’unica classe omonima (Client) che consente l'interfacciamento con l'utente e che realizza la comunicazione fra Client e Front End, implementando un opportuno protocollo (vedi la sezione Protocollo Client-Front End del paragrafo 2.4.4 - Front End).
La scelta di quale Front End utilizzare per raggiungere il servizio è lasciata all’utente come argomento della linea di comando.
Il main presenta una struttura molto semplice, schematizzabile come segue:
L'applicazione termina in caso di problemi di connessione verso il Front End o in caso di terminazione volontaria da parte dell'utente. Quest'ultima può avvenire in seguito alla richiesta di un comando CLOSE o alla notifica di un <CTRL+C>.
|
|
|
|
|