Titolo del progetto
Agenti mobili per musei virtuali
Applicazioni per l'ambiente SOMA
Autore
Zappacosta Emiliano matr . 21 48 53664
Data delle revisioni
26 . Marzo . 2001
Obiettivo
Nell'intento di realizzare un progetto attinente le argomentazioni della tesi di laurea relativa ai Musei Virtuali, l'idea è quella di progettare e realizzare un semplice agente mobile basato sul sistema ad agenti SOMA che sia in grado di ricercare informazioni museali su più host. Scopo finale di questa esperienza, oltre alla realizzazione di un primo prototipo funzionante dell'agente, è :
- Mettere in luce quelle che sono le potenzialità dei linguaggi di Mark Up, quale XML, nel campo della descrizione di risorse.
- Conoscere l'ambiente di programmazione ad agenti mobili SOMA, come supporto alla realizzazione di una mobilità debole.
- Approfondire l'uso del linguaggio Java in applicazioni di rete.
Analisi
La ricerca di informazioni distribuite è un problema a tutt'oggi ancora aperto. Il grosso del problema risiede nel riuscire ad organizzare le informazioni a nostra disposizione in maniera tale da consentire una ricerca efficiente ed efficace. In altre parole bisogna dare una buona descrizione delle risorse oggetto della ricerca, una descrizione completa e a 360° che descriva la risorsa sotto tutti i punti di vista.
Un andamento emergente è quello di descrivere il materiale a disposizione con metadati. I metadati sono "informazioni sui dati". Essi descrivono una risorsa: che cosa è, cosa contiene, dove si trova e così via.
Il Resource Description Framework(RDF) del World Wide Web Consortium (W3C), è da tempo impegnato nella definizione di un'architettura di metadati per funzioni di filtro del contenuto dei documenti Web. In questo contesto è stata redatta la norma Dublin Core(DC) (1996), sviluppata appositamente per:descrivere risorse informative generiche che potessero essere recuperate in una sola sessione di ricerca, trattando i documenti come oggetti forniti di etichette (tag) che ne evidenziano determinate caratteristiche.
Proprio la caratteristica di utilizzare delle etichette fà risultare il linguaggio XML particolarmente adatto per la codifica di informazioni di questo tipo (il binomio è quasi inscindibile). Dando il giusto peso agli standard del settore, la scelta di codificare le informazioni museali in XML attenendosi alle direttive DC risulta giustificata.
Dal punto di vista del modello di comunicazione, una applicazione di questo genere potrebbe rifarsi al modello cliente-servitore (es. i tradizionali motori di ricerca). Una realizzazione di questo tipo pone forti limitazioni. Tale modello, basandosi sul semplice scambio di dati, necessita spesso di una ampia banda, disponibile in reti locali ma non necessariamente in reti geografiche. Inoltre, i servizi non sono flessibili; se un cliente ha bisogno di un servizio che il servitore non realizza, non può far altro che andare su un'altro servitore.
Queste motivazioni hanno spinto verso modelli di comunicazione diversi, in particolare il modello ad agenti mobili. Questo modello è caratterizzato da entità (agenti) che sono in grado di spostarsi di propria iniziativa tra i vari nodi del sistema. Inoltre, essendo in grado di eseguire, portano con loro tutta la logiga di funzionamento del processo applicativo che realizzano. Il recupero di informazioni distribuite è il campo applicativo in cui il modello ad agenti mobili mostra tutte le sue potenzialità. Prendiamo un'applicazione che richiede a vari siti (uno alla volta) una grande quantità di dati che, successivamente, "filtrerà" localmente. In genere la maggior parte dei dati che transitano sulla rete sono "inutili" per l'applicazione che li ha richiesti. Ecco allora che si può pensare di mandare in giro per la rete un agente mobile che raccoglie le informazioni dai vari nodi. Ovviamente raccoglierà solo le informazioni "utili" per l'utente che l'ha creato (saprà quali sono perchè l'agente ha una "logica interna",cioè ha un codice). Poichè tali informazioni sono in generale di dimensioni ridotte, può essere addirittura enormemente vantaggioso l'uso di un agente mobile anzichè il classico modello cliente-servitore.Queste sono i motivi percui, nello sviluppo del progetto, abbiamo deciso di adottare una codifica dei dati in XML seguendo lo standard Dublin Core e di realizzare una applicazione ad agenti mobili.
Requisiti è Specifiche
L'ambiente ad agenti mobili a nostra disposizione è l'ambiente SOMA (Secure and Open Mobile Agent) e su questa assunzione basiamo le nostre specifiche.
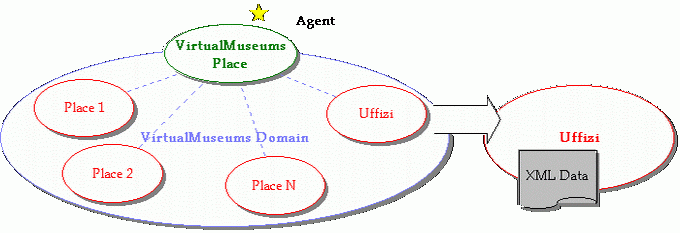
Il sistema prevede una serie di host (musei) che conterranno i nostri dati ed un nodo principale che funge da dominio (museo di musei). Il sistema rispetta le seguenti specifiche:
- Il sistema degli host è organizzato secondo 'domini SOMA', in particolare esisterà il domonio VirtualMuseums.
- Ogni nodo che vorrà condividere le proprie informazioni dovrà appartanere al dominio succitato.
- Le informazioni museali contenute sui nodi saranno codificate in XML secondo il modello di metadati Dublin Core.
- La ricerca partirà sempre dal place di default (VirtualMuseums), che per ipotesi svolge il solo ruolo di coordinatore (in pratica non contiene informazioni da ricercare). Per la effettiva realizzazione dell'agente questo requisito può essere rilasciato, in effetti la ricerca potrebbe partire da uno qualsiasi dei nodi.
Progetto
L'intera organizzazione del sistema è caratterizzata dall'utilizzo di SOMA come ambiente per la mobilità. Difatti abbiamo previsto di organizzare la struttura dei nodi sfruttando la naturale organizzazione a domini dei place di SOMA, la quale prevede di raggruppare place (nodi) che hanno uguali caratteristiche sotto l'aspetto fisico o logico in uno stesso dominio. I domini SOMA sono organizzati ad albero gerarchico; noi per semplicità limitiamo il nostro sistema ad un solo livello, supponendo che i nodi del dominio non siano eccessivi e che dunque siano contenibili in un solo dominio. Nulla ci vieta in futuro di organizzare i place in più sottodomini gerarchici, per far fronte ad eventuali motivi di scalabilità del sistema. Nel nostro caso avremo che i PNS (Place Name Service) dei place del nostro dominio conterranno l'elenco dei place su cui dover ricercare le informazioni (tutti conoscono tutti).
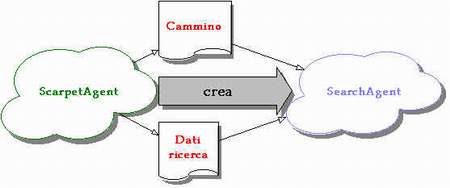
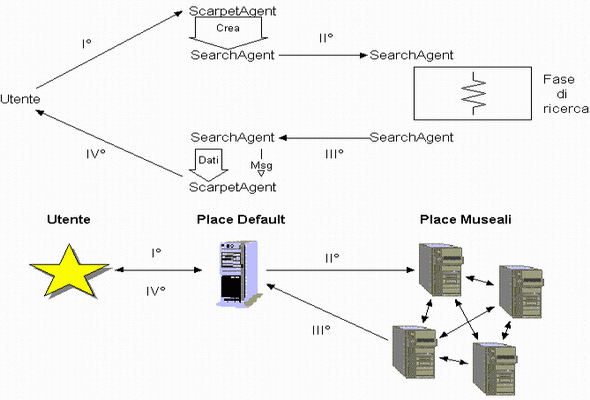
L'applicazione è costituita di due agenti. Il primo ScarpetAgent (committente) funge da interfaccia utente per la ricerca e il secondo SearchAgent (cercatore) è l'entita in grado di compiere la ricerca sui nodi. L'agente cercatore contiene un vero e proprio interprete del linguaggio DublinCore-XML usato per codificare i dati. In sostanza il committente prepara tutto il necessario per la ricerca, lancia l'agente cercatore e visualizza infine i dati portati indietro dal cercatore stesso. Durante la fase di ricerca, l'agente che si muove è ovviamente l'agente cercatore. L'altro è comunque un agente mobile in grado di spostarsi, ma durante la fase di ricerca resta fermo sul nodo dove si trova in attesa del risultato.
Un aspetto interessante da affrontare riguarda la modalità di esecuzione della ricarca. La ricerca può essere portata avanti secondo due differenti modalità:
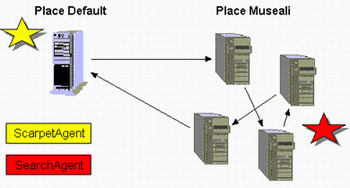
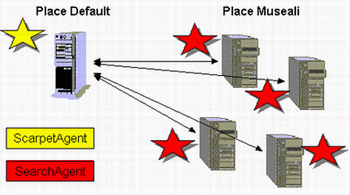
seriale : tutti i nodi vengono visitati uno per volta (in sequenza) dallo stesso agente;
parallelo : ogni nodo viene visitato da un proprio agente, più o meno contemporaneamente.
L'interessante è valutare il comportamento di entrambe le soluzioni su una rete reale e sotto diversi livelli di carico, valutando il traffico generato ed i ritardi introdotti. Purtroppo non è stato possibile effettuare dei test su una rete reale, ma entrambe le soluzioni sono state implementate con la costruzione di unico agente cercatore. Ciò è stato reso possibile dal fatto che l'agente cercatore, quando viene creato, accetta come parametro un cammino di nodi (un cammino può essere anche di un solo nodo).
Nel primo caso l'agente committente crea un solo cercatore passandogli la lista dei nodi da visitare (in realtà non è proprio così), nel secondo crea un cercatore per ogni nodo passandogli il nodo stesso.Coordinamento richiesta/ricerca/risposta
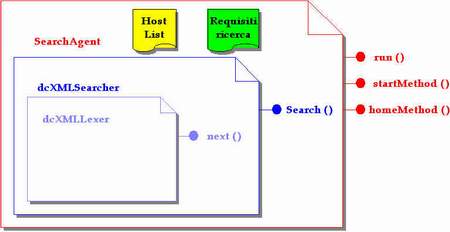
Il modello di richiesta della ricerca è un modello client/server tra l'utente e l'agente SearchAgent, mentre è a demandazione tra i due agenti come illustrato nella figura.
La gerarchia delle classi
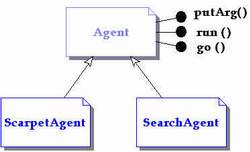
Le classi che implementano i due agenti discendono entrambe dalla classe base Agent messa a disposizione da SOMA e che fornisce le funzionalità di base di cui deve essere dotato un agente mobile.
L'agente SearchAgent
L'agente cercatore è il cuore dell'applicazione. Esso si occupa di effettuare la ricerca delle informazioni sui vari nodi. Per come è stato pensato ha bisogno di almeno due informazioni per poter operare: la lista dei nodi che deve visitare ed una struttura dati che specifichi le proprietà di interesse per gli oggetti da ricercare. Ricevuti questi dati alla creazione, l'agente parte alla volta del primo host, dove prende il file dei dati museali e cera al suo interno. Ovviamente l'agente deve essere in grado di "capire" (interpretare) il contenuto di questo file. L'agente cercatore di per se non è in grado di farlo ma contiene un oggetto (è a tutti gli effetti un parser-valutatore) che, accettando in ingresso la struttura dati contenenti i requisiti della ricerca, valuta la bontà di ogni record e restituisce un vettore contenente alcune informazioni sui record rilevanti ai fini della ricerca. Questo oggetto a sua volta si avvale dell'aiuto di un oggetto lexer che scandisce le parole del file di dati.
Questo agente porta con se oltre alle due strutture dati sopra citate anche un vettore contenente i risultati della ricerca; è da notare che si potrebbe fare a meno di portare dietro la lista dei nodi da visitare per le assunzioni fatte (tutti i nodi hanno lo stesso PNS) ma si è riscontrato che i PNS dei nodi sono in ordine differente e ciò comporta difficoltà nell'individuare l'host successivo da visitare. La scelta fatta da noi è dunque quella di portarsi dietro la tabella ed eliminare, man mano che si procede, i nodi visitati (ciò porta ad una maggiore efficienza essendo la lista sempre più corta).
Per far migrare un agente, SOMA sfrutta la proprietà di "serializzabilità" che può essere imposta su un oggetto (gli agenti SOMA sono oggetti passivi), dunque questa proprietà deve essere posseduta da queste strutture dati.
Il metodo StartMethod() si occupa di far migrare l'agente da un nodo all'altro e di far fare le ricerche. Esso viene lanciato automaticamento dopo ogni migrazione.Terminato il percorso, l'agente torna al nodo di partenza (home place) e riprende l'esecuzione con il metodo HomeMethod() (possibile perche Soma consente di specificare il metodo con cui ripartire dopo una migrazione). Il metodo si occupa di comunicare l'esito della ricerca al committente. Si pone a questo punto un problema di comunicazione tra agenti. Soma prevede una interazione "stretta", possibile solo attraverso condivisione di oggetti, ed una "lasca", realizzata mediante scambio di messaggi (mette in piedi un un intero sisteme di mailbox). Noi abbiamo utilizzato entranbe le forme di comunicazione. Difatti si usa la condivisione di un vettore per passare i risultati al committente ed un messaggio dalla dicitura <SearchAgent_result> per avvertirlo che il risultato è pronto.L'oggetto dcXMLSearcher
Giunti su un nuovo nodo, l'agente cercatore crea una istanza di questo oggetto e lancia il metodo search() passandogli la struttura dati contenente i termini della ricerca. L'oggetto è in grado di scandire e riconoscere tutti gli elementi del file di dati. Di fatti riconosce la seguente grammatica :
DCS ::= <dublin-core-simple> RL </dublin-core-simple>
RL ::= <record-list> LIST </record-list>
LIST::= DCR | DCR LIST
DCR ::= <dc-record> 1 o + tag dublin core </dc-record>La tecnica usata per realizzare il "mini interprete" è quella dell'analisi ricorsiva discendente.
Il file di dati
Il file di dati è un file di metadati DC codificato in XML e presenterà la seguente struttura :
<?xml version="1.0" ?>
<dublin-core-simple>
<record-list><dc-record>
<type>...</type>
<format>...</format>
<title>...</title>
<description>...</description>
<subject>...</subject>
<creator>...</creator>
<contributor>...</contributor>
<publisher>...</publisher>
<date>...</date>
<coverage>...</coverage>
<identifier>...</identifier>
<source>...</source>
<relation>...</relation>
<language>...</language>
<rights>...</rights>
</dc-record>...... "serie di record dublin core" .....
</record-list>
</dublin-core-simple>Per facilitare l'accesso da parte dell'agente si è pensato di stabilire il nome e la posizione del file. Il file dati deve dunque essere posizionato, nel file system locale degli host, nella directory che contiene le classi degli agenti ovvero :
" ...\SOMA\agents\xyz.xml "
Il nome del file è dato invece dal nome del place seguito dal suffisso "data.xml", così per esempio per il place "VirtualMuseums Uffizi" il file si chiamerà "Uffizidata.xml".
Politica di ricerca
Quello che si è tentato di fare è realizzare una ricerca che sfruttando le proprietà descrittive dei metadati DC sia la più aderente possibile alle richieste di un cliente. Più che all'efficienza, abbiamo badato all'efficacia del metodo di ricerca. La valutazione di un record avviene assegnando ad esso un punteggio che dipende dal numero e dal tipo di termini che fanno match con le richieste. Il peso di un termine dipende dall'importanza del tag a cui è associato. Per semplicità abbiamo supposto di poter fare le ricerche basandoci su un set limitato dei tag DC :
Tag Descrizione Importanza Peso <type> tipo di oggetto deve coincidere se viene specificato 10000
<creator> autore "
1000
<title> titolo "
100
<language> lingua originale "
10
<subject> soggetti basta la presenza di alcuni soggetti 1
Come si vede si da più peso a quei tag che devono combaciare necessariamente per poter essere rilevante ai fini della ricerca, nel senso che se un utente specifica il titolo o l'autore, un record rilevante deve avere necessariamante quel titolo o quell'autore (non posso portare all'utente un titolo o un autore diversi da quello specificato). La rilevanza o meno di un record si ottiene confrontando il punteggio ottenuto con una soglia calcolata in base ai dati forniti dall'utente (con la stessa tecnica). La proprietà dell'essenzialità dei tag più importanti è ottenuta variando di un ordine di grandezza i pesi di ogni differente tipo di tag. In tal modo se calcolo una soglia di 21010 per poterla superare devo necessariamente almeno avere 2 type, 1 creator ed 1 language che coincidono con le richieste dell'utente, altrimenti non riuscirei mai a totalizzare un punteggio almeno pari alla soglia.
Risultato della ricerca
Come risultato di una ricerca, dcXMLSearcher fornisce delle informazioni relative ai record risultati rilevanti. In particolare le informazioni relative al record devono essere significative per la descrizione dell'oggetto a cui si riferisce il record stesso. Quelle da noi ritenute tali sono :
Titolo il titolo dell'oggetto o dell'evento descritto Descrizione breve descrizione dell'oggetto Autore chi è l'autore della cosa descritta Identificatore un identidicatore univoco per l'oggetto all'interno del dominio Come risultato della ricerca su un nodo, si otterrà una lista di questi elementi (t-d-a-i), uno per ogni record trovato. Le informazioni relative ad un record sono almeno 4 considerando che i campi titolo ed autore potrebbero essere multipli anche se DC non esclude la ripetizione anche degli altri due.
Problema che resta da risolvere è come legare i risoltati otteniti al nodo in cui sono stati trovati (questo per la rintracciabilità delle risorse reali). Due sono le possibilità:
includere nella struttura dati del risultato anche il nome del place su cui sono stati truvati i record (incapsulare dati e provenienza in una unica struttura);
seguire le specifiche Cimi premettendo all'identificatore locale della risorsa, l'identificatore del nodo (host o museo) che lo detiene. Es. :
Uffizi : wac Oldenburg interview 1974-08-25/1974-08-26La soluzione da noi seguita è la seconda.
Implementazione
L'ambiente di sviluppo utilizzato è Kawa 3.22 , ed il linguaggio di programmazione usato è Java (jdk 1.2 ). Abbiamo detto che gli agenti discendono entrambi dalla classe SOMA.agent.agent, inoltre implementano alcune interfacce:
public class ScarpetAgent extends Agent implements LinguaListener,
PropertyChangeListener,FinSearchListener,FinAgentMessageListenerpublic class SearchAgent extends Agent implements FinAgentMessageListener
In particolare ScarpetAgent implementa l'interfaccia FinSearchListener di cui parleremo più avanti.
Due sono gli aspetti implementativi più interessanti da evidenziare. Il primo riguarda il flusso di informazioni che và dall'agente committente a quello cercatore. Soma prevede che alla creazione di un agente si possa passare un parametro di inizializzazione che verrà raccolto dall'agente stesso come oggetto parametro d'ingresso al metodo putArgument() attivato dal sistema prima di ogni altro metodo.
public AgentID createAgent(String agentName,Object argument)
[metodo della classe AgentManager]public void putArgument(Object obj) [metodo della classe Agent]Le informazioni passate al cercatore sono tre:
- una stringa che identifica il place di destinazione (placeID se la ricerca è parallela, altrimenti la stringa "RicercaSequenziale" e sarà l'agente cercatore a precurarsi la tabella PNS)
- una struttura dati contenente le specifiche della ricerca
- l'AgentID dell'agente committente, necessario al cercatore al momento del ritorno quando dovrà mandargli un messaggio.
La struttura dati preposta a contenere le informazioni necessarie alla ricerca dovrà contenere per ogni tag rilevante l'elenco dei termini richiesti. Per esempio:
<subject> "sculpture","exibition","friedman martin" ecc. <type> "event","original","cultural" ecc. ...... ......... La struttura dati che a noi è parsa più adatta a questo scopo è un HashTable con chiavi i diversi tag DC (<type>, <title>, <creator>...) e come oggetto associato un vettore contenente tutti i termini specificati per le ricerca e associati al tag in questione.
Il secondo riguarda la struttura dati usata per restituire i risultati al committente. Le informazioni portate indietro vengono messe una dopo l'altra in un vettore, sotto forma di stringa di caratteri. Ogni elemento del vettore conterrà le informazioni relative ad un record risultato rilevante. Il committente al lancio degli agenti deposita un vettore nell'area degli oggetti condivisi. Ogni agente di ritorno da una ricerca, accoda i suoi risultati in questo vettore. Al ritorno di tutti gli agenti, il committente preleva il vettore e visualizza i risultati all'utente.
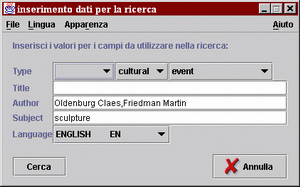
Infine osserviamo che oltre alle classi già citate è stato necessario estendere l'interfaccia grafica di soma con la implementazione di una finestra di ricerca FinSearch, che consentisse l'immisione delle informazioni necessarie per la ricerca. Tale finestra fà poi riferimento al metodo eseguiAzioneSearch() dell'interfaccia FinSearchListener, nel momento in cui si deve eseguire l'operazione associata al pulsante "cerca" per poter ripassare il controllo al committente.
Tale finestra ha il compito quindi di raccogliere le informazioni, organizzare la struttura ad hashtable e restituirlo all'agente committente che lo ha generato.
public class FinSearch extends Finestra
Codifica
Verifica
Riportiamo di seguito le fasi di una sessione di ricerca.
Sull'interfaccia grafica dell'agente ScarpetAgent si notano i pulsanti "CercaS" e "CercaP" usati per avviare una sessione di ricerca Sequenziale o Parallela.
La fase successiva è l'immissione dei dati per la ricerca.
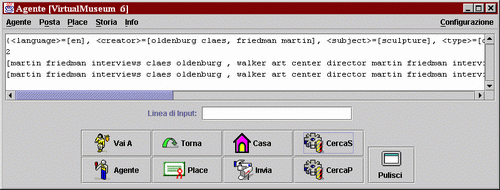
Dopo aver lanciato la ricerca ed atteso qualche istante ecco cosa prenta l'agente come risultato.