Relazione sul Progetto di Lorenzo Tomasi
Un'applicazione ad Agenti Mobili: un'agenda distribuita
Obiettivi del progetto
Con questo progetto si vuole realizzare un'applicazione che gestisca lo scheduling d'eventi rilevanti per un gruppo d'utenti (riunioni, incontri, ecc…), coordinando le risorse, cioè le agende, dei singoli in modo trasparente per questi.
Altri obiettivi del progetto sono l'esplorazione del paradigma di programmazione ad agenti mobili e il confronto di tale paradigma con quello tradizionale C/S dal punto di vista delle prestazioni ma soprattutto da quello architetturale e progettuale.
Sarebbe a dire che si vedrà questo lavoro più come un case study o un esperimento, piuttosto che come il progetto di un'applicazione vera e propria. Per questo si trascureranno requisiti anche fondamentali per un'applicazione di CSCW (si veda più avanti, soprattutto nella formulazione del protocollo di coordinamento) per arrivare prima ad una prototipazione del sistema che permetta alcune prove ed esperimenti.
Scenario applicativo e requisiti generali del sistema
Si immaginino più gruppi di lavoro, all'interno di un'organizzazione (impresa, università, ecc…), che collaborano tra loro. I singoli individui appartengono a vari gruppi o fanno da tramite tra gruppi diversi. Ogni gruppo ha la necessità di coordinarsi al suo interno e con altri gruppi. Una parte fondamentale di questo coordinamento è il trovarsi per discutere insieme e per scambiarsi informazioni. Per questo è necessario per i singoli poter accordarsi su dove e quando incontrarsi, compatibilmente con i propri impegni personali.
Si pensi che ognuno abbia una propria agenda su cui può segnare i propri appuntamenti e che ogni tanto decida di fissare un impegno d'accordo con altri utenti. Viene naturale pensare ad una soluzione in cui ogni utente gestisce localmente una propria risorsa (l'agenda) che è accessibile, in modo controllato, anche dall'esterno quando è necessaria una fase di coordinamento con gli altri utenti.
Si preferisce questo scenario rispetto ad uno in cui le risorse sono centralizzate, non solo perché l'ultimo non favorisce la flessibilità e la scalabilità, ma anche perché il primo è più adatto alla sperimentazione di sistemi ad agenti mobili.
Il sistema che si vuole progettare dovrà quindi:
Analisi e Progettazione
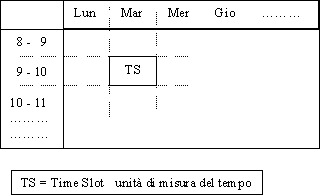
La risorsa
La risorsa presente in ogni nodo è una timetable che può essere vista come in figura. Un evento, oggetto di un'operazione di scheduling, può coprire uno o più time slots contigui (la cui dimensione può essere diversa da quella mostrata in figura).
Le operazioni primitive che si possono eseguire su una timetable, sono operazioni di confronto e operazioni di modifica dello stato: quest'ultime sono "Aggiunta di un evento" e "Cancellazione di un evento". Si noti che una qualunque sequenza di queste due operazioni è idempotente. Infatti, se si esegue la stessa sequenza per due volte, la timetable permane nello stato che aveva raggiunto al termine della prima esecuzione della sequenza.
Quest'osservazione permette di adottare semantiche "at least once", per esempio durante la fase di recovery da crash del nodo.
La timetable deve essere corredata d'opportune strutture che supportino l'accesso concorrente e controllato alla risorsa (ad esempio diverse interfacce o diversi manager), oltre che la persistenza e la fault tolerance.
A questo proposito, è necessario ricorrere a tecniche analoghe a quelle utilizzate nei DBMS, come logging delle transazioni, strategie di Undo e Redo, ecc…
In ogni caso è importante che le tecniche di fault tolerance e di recovery adottate lavorino in modo trasparente, affinché sia possibile modificare o raffinare queste tecniche senza che sia toccato il resto del sistema.
Il protocollo di coordinamento
Si premette che nel seguito il termine "agente" starà per "componente software" o "attore" ma non necessariamente per "agente mobile".
Si supponga che si voglia fissare un incontro tra alcuni utenti. L'iniziativa è presa da uno di questi, che propone un insieme di date possibili per l'incontro. Gli altri a turno o contemporaneamente escludono alcune date, secondo la disponibilità individuale. Infine tra le date rimaste, cioè quelle in cui tutti sono disponibili, n'è scelta una per l'incontro. Questo è fissato aggiornando le agende di tutti i partecipanti.
Il protocollo è quindi distinto in due fasi: la prima, la negoziazione, in cui ci si mette d'accordo su un insieme di date, e la seconda in cui si rende effettiva la decisione presa in comune durante la prima fase.
La negoziazione
La negoziazione è, in effetti, molto limitata se ci si attiene a quanto descritto finora, ma come già detto, quello che si vuole è semplificare il progetto, anche trascurando il livello applicativo, per arrivare ad un prototipo.
Tuttavia alcuni aspetti della prima fase vanno ancora chiariti: si supponga di avere un insieme di date possibili per un evento e che un agente (A1) interroghi una timetable (T1) per sapere se una data è compatibile con gli impegni già fissati in essa. Si supponga anche che la risposta ricevuta dall'agente sia affermativa. Un punto da chiarire è se tale risposta sia vincolante o meno per chi la fornisce. Detto in altri termini, la domanda è " Dare la propria disponibilità è impegnativo (in questo caso per il gestore della timetable) ?".
Rispondere sì a questa domanda significa affermare che l'operazione eseguita dall'agente sulla timetable ha, in effetti, il significato di una prenotazione, che va, prima o poi, confermata o disdetta.
Una prima conseguenza di tutto questo è che l'interazione tra l'agente e la timetable non è conclusa. Portare a compimento quest'interazione può essere oneroso.
Infatti, si supponga ora che l'agente che ha eseguito l'interrogazione/prenotazione sulla timetable debba coordinarsi con altri agenti che hanno interrogato altre timetable, oppure debba lui stesso interrogare altre timetable. Queste operazioni possono durare un tempo indeterminato, tuttavia lo stato della prima timetable (T1) non può rimanere sospeso a lungo, in attesa che sia presa una decisione, (se l'agente A1 aveva acquisito un lock sulla timetable T1 è bene che lo rilasci per evitare di essere unfair o di trattenere troppe risorse). Se la risorsa (T1) è rilasciata e resa disponibile ad altri, essa deve comunque tenere memoria dell'agente (A1) e della sua prenotazione, in modo da poter riconoscere l'agente in seguito, quando la prenotazione sarà confermata o disdetta. Nel frattempo se altri chiede di fare la stessa prenotazione si deve o rispondere con un rifiuto (una scelta unfair) o metterlo in attesa. Ma le attese possono essere molto lunghe perché le negoziazioni coinvolgono più risorse (e quindi più code d'attesa), necessitano la sincronizzazione delle risorse (quindi il ritardo di un gruppo è il ritardo del soggetto più lento) e interagiscono presumibilmente con altre negoziazioni in corso, col risultato complessivo di prolungare i tempi dei protocolli (per non parlare dell'aumento di complessità).
Insomma, considerare una semantica basata sull'operazione "prenotazione di time slots" significa introdurre un'interazione molto stretta tra gli agenti e le risorse. Questa semantica probabilmente è lo strumento necessario per consentire negoziazioni articolate (del tipo offerta/contro-offerta), ma produce anche un appesantimento dei costi in termini di tempi e risorse.
Se si vuole risparmiare sui costi e si può rinunciare a negoziazioni complesse, conviene considerare una semantica differente: quando, durante la negoziazione, un agente interroga una timetable, la risposta che riceve riflette lo stato attuale della risorsa, e lo stato tiene memoria delle operazioni già concluse (o meglio dei loro effetti) ma non delle interazioni ancora in corso. Quindi la fase di negoziazione è una fase di raccolta di informazioni sullo stato delle risorse e nulla più. Ci si può basare su queste informazioni per avere indicazioni, ma col passare del tempo le informazioni tendono a perdere di validità. In altre parole, un agente potrebbe considerare libero un intervallo di tempo durante la prima fase del protocollo, ma trovarlo occupato durante la seconda fase, cioè quando si deve fissare l'appuntamento concordato.
E' chiaro che non è il caso di cercare un accordo elaborato tra i partecipanti basandosi su informazioni probabili ma non certe, anche perché queste informazioni si fanno sempre meno probabili col passare del tempo. E' meglio delegare tutta l'interazione di gruppo alla seconda fase, tentando di fissare rapidamente un appuntamento sulle agende degli utenti, magari provando più volte fino a riuscire e contando sul fatto che le informazioni di cui si dispone sono, tutto sommato, molto probabilmente vere.
Riassumendo, la fase di negoziazione è una fase di interrogazione delle risorse che non ne influenza lo stato. Le informazioni raccolte in questa fase hanno il valore di indicazione sulla disponibilità dei singoli, ma non sono considerate vincolanti.
La seconda fase - un'applicazione del two phase commit protocol
Si supponga ora di voler fissare un appuntamento di gruppo su un certo numero di agende. Non si sa con certezza se il periodo di tempo scelto per l'incontro è disponibile su tutte le risorse. Perciò l'operazione nel suo complesso potrebbe anche fallire, se fallisce una singola scrittura.
Questo è proprio un caso in cui si può applicare il two phase commit protocol, famoso per il suo utilizzo nelle transazioni distribuite sui DDBMS.
E' bene ricordare che il protocollo deve resistere a guasti singoli del tipo
Inoltre, è possibile il deadlock di due transazioni che concorrono per due risorse. Si supponga che la transizione T1 si aggiudichi la risorsa R1 e chieda il lock su R2, mentre T2 detiene R2 ma chiede R1. Il protocollo risolve questa situazione facendo scadere entrambi i timeout su ready / not ready dei due coordinatori, quindi facendo abortire le transazioni.
Le caratteristiche di fault tolerance si possono ottenere se ogni nodo tiene un log dello stato dell'agente che lavora su quel nodo. In questo modo è possibile fare il recovery di un partecipante e concludere la transazione.
Perché i guasti siano effettivamente singoli, sarebbe bene che ogni partecipante, coordinatore compreso, risieda su un nodo differente. Questo comporta che anche le risorse siano dislocate una per nodo.
Ancora sulla negoziazione: le possibili strategie di interrogazione
Si è visto che per la seconda fase è preferibile l'uso di un two phase commit protocol, per sincronizzare le singole operazioni locali. Per la negoziazione invece si possono adottare protocolli differenti, dato che si tratta di raccogliere informazioni e comporre i risultati delle varie interrogazioni. Usando sempre il termine agente in modo astratto, si vedranno ora le strategie a confronto.
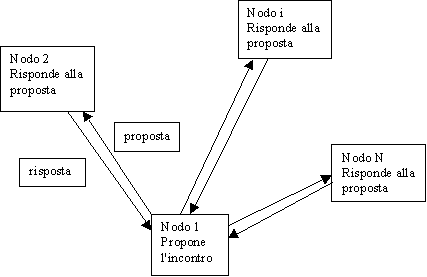
Interrogazione sequenziale
In questo schema un agente interroga in successione tutti i nodi: ogni nodo fornisce la propria disponibilità per l'incontro proposto. Ad ogni passaggio, l'agente corregge la proposta (in pratica elimina gli intervalli di tempo incompatibili) secondo la risposta ricevuta dall'ultimo nodo visitato. Nonostante lo schema imponga la sequenzializzazione delle queries, l'agente può accorgersi in poco tempo di un'eventuale impossibilità d'incontrarsi del gruppo. Inoltre, rispetto ad altri schemi, questo è quello che genera minore traffico di rete.
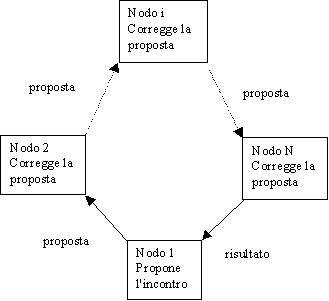
Interrogazione parallela
In questo schema più agenti interrogano le risorse in parallelo. Alla fine è necessario comporre i risultati per avere il quadro generale della situazione. All'opposto dello schema precedente, in questo il traffico di rete è più elevato (approssimativamente il doppio), ma l'azione è più rapida.
Schemi di interrogazione mista
Se s'introduce il concetto di località (per i sistemi ad agenti mobili questo è naturale, per un sistema client-server occorre predisporre un'architettura particolare in cui c'è un server in ogni dominio per coordinare le azioni nella località), si possono adottare schemi misti sequenziale - parallelo.
In particolare:
Si cercherà di implementare tutti questi schemi sia in modalità client-server sia secondo il paradigma ad agenti mobili, per confrontare le prestazioni fornite dalla combinazione tra le strategie descritte e i paradigmi di programmazione adottati.
L'architettura generale
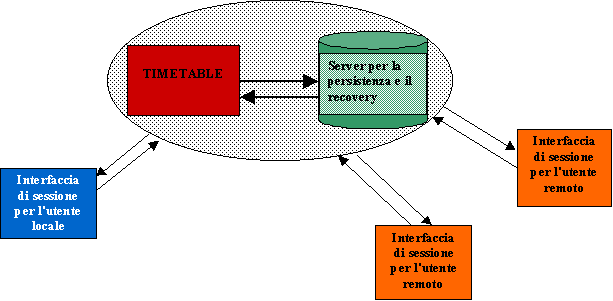
In figura è mostrata l'architettura base del sistema:
La risorsa timetable è affiancata da un altro oggetto, responsabile della realizzazione dei meccanismi di persistenza e fault tolerance necessari. In pratica quest'oggetto gestisce l'I/O necessario e s'interfaccia con il file system della macchina locale. Si ritiene importante la separazione dei compiti tra i due componenti: timetable si occupa dei problemi di consistenza e di controllo degli accessi, l'altro permette di astrarre dai dettagli dell'I/O.
Grazie a questa distinzione diverse interfacce potrebbero implementare diverse politiche di gestione dei log e di sincronizzazione delle copie su disco (checkpointing, tecniche di REDO, ecc…). Questo è ciò che, infatti, è stato realizzato nell'implementazione del sistema: l'interfaccia locale sincronizza la copia su disco periodicamente, mentre l'interfaccia remota forza sempre la sincronizzazione a seguito di una modifica dello stato della risorsa.
Si noti inoltre che in figura sono indicate più di un'interfaccia per utenti (agenti) remoti. Per aumentare la flessibilità del sistema, si permette a più interfacce di essere attive contemporaneamente. Del resto non c'è motivo di imporre il vincolo che tutti gli utenti remoti utilizzino lo stesso oggetto, dato che un meccanismo di sincronizzazione dovrebbe comunque gestire le richieste concorrenti dell'interfaccia locale e di quella remota. Utilizzando, invece, interfacce diverse è possibile fornire meccanismi d'autenticazione dell'utente remoto e d'accesso controllato (tipo ACL), o semplicemente di personalizzazione dell'interfaccia. Inoltre, se all'interfaccia è associato uno stato, è bene che ogni utente, o meglio, ogni sessione d'utente utilizzi oggetti diversi.
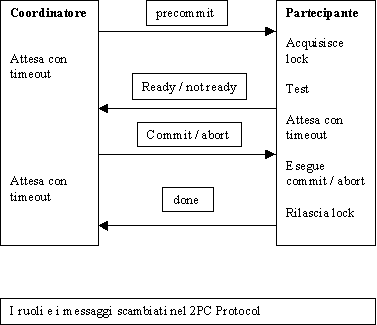
La specifica del comportamento degli attori del 2PC Protocol
Si esaminerà ora più nel dettaglio il protocollo 2PC e come debbano comportarsi il coordinatore ed i partecipanti durante il protocollo, anche a fronte di guasti.
Per capire meglio come il tutto funzioni si deve pensare che l'arrivo di un messaggio del protocollo sia gestito come un evento. In questo modo un messaggio può sbloccare uno degli attori da un'attesa, proprio come accade allo scadere di un timeout.
I messaggi tipici del 2PC sono quelli mostrati nella figura all'inizio della sezione "La seconda fase - un'applicazione del two phase commit protocol".
Il protocollo si articola in più fasi:
Fase di preparazione: in questa fase si verifica la possibilità di avviare il protocollo, si allocano le risorse necessarie, ecc…
E' compito del coordinatore segnalare ai partecipanti la fine di questa fase e l'inizio del protocollo vero e proprio, con l'invio del messaggio "precommit". Quest'impegno deve essere mantenuto anche in caso di fallimento del coordinatore, altrimenti i partecipanti potrebbero rimanere in attesa indefinita.
Nel caso che non sia possibile avviare il protocollo, il coordinatore può inviare un messaggio di "abort", oppure si può prevedere un messaggio ad hoc per questa situazione. Il messaggio di "precommit" potrebbe anche perdersi, nel qual caso l'unica possibilità di sbloccare i partecipanti è l'arrivo di un messaggio di "abort", a seguito dello scadere del timeout del coordinatore durante la fase di precommit (si veda più avanti).
Si potrebbe anche eliminare il messaggio di precommit e far sì che ogni partecipante cominci a lavorare in modo indipendente, avanzando nelle fasi del protocollo. In questo caso l'unica possibilità di fermare i partecipanti già avviati è l'invio di un messaggio di "abort" da parte del coordinatore.
Fase di precommit: in questa fase ogni partecipante verifica la possibilità di eseguire il commit sulla risorsa locale e si dichiara "ready" o "not ready" inviando il corrispondente messaggio al coordinatore. Quest'ultimo attende i messaggi dopo aver fissato un timeout. Se tutti i messaggi sono del tipo "ready" e arrivano entro il timeout, il coordinatore deciderà per il commit, altrimenti per l'abort.
Per il coordinatore questa fase ha una durata limitata da un timeout, mentre i partecipanti entrano nella fase successiva (commit phase) nel momento stesso in cui inviano il (primo) messaggio "ready/not ready".
Fase di commit: questa è la fase più delicata. Il partecipante, come già detto, inizia questa fase inviando il messaggio "ready/not ready" al coordinatore. Subito dopo si pone in attesa della risposta ovvero di un messaggio "commit/abort". L'attesa può essere regolata da un timeout al termine del quale il partecipante è tenuto a rispedire il messaggio "ready/not ready" e ad aspettare per un altro periodo di tempo la risposta. Questo è valido soprattutto se il partecipante si è dichiarato "ready", nel qual caso ha perso il diritto di abortire o eseguire commit singolarmente. Dopo aver ricevuto il messaggio del coordinatore, il partecipante deve "eseguire gli ordini" e inviare un messaggio "done" quando ha finito.
Il coordinatore invece deve durante questa fase inviare il messaggio "commit/abort" e attendere la risposta di tutti i partecipanti, rappresentata dal messaggio "done". Il coordinatore deve anche continuare a rispondere ai messaggi "ready/not ready" spediti dai partecipanti, inviando ancora il "commit/abort".
E' evidente la fragilità del protocollo in questa fase: se un partecipante cade, il coordinatore deve aspettarne il ripristino perché attende il messaggio "done", e ancora, se un messaggio "done" si perde il coordinatore aspetta per sempre.
E' fondamentale quindi prevedere meccanismi che sblocchino il coordinatore: si può far fronte alla perdita di messaggi pensando ad un ulteriore risposta del coordinatore (un ack su "done") che impegni il partecipante a rispedire "done" finché non riceve l'ack. Ma è chiaro che la possibilità di bloccare qualcuno tra gli attori rimane.
L'unica soluzione è prevedere un timeout per il coordinatore al termine del quale questi si può ritirare, magari stilando un report della transazione.
Tuttavia così facendo un partecipante potrebbe rimanere bloccato: si supponga che un partecipante ready cada prima di spedire il messaggio "ready". In seguito il coordinatore gli spedisce "abort" (il suo timeout è necessariamente scattato), ma il messaggio non può essere recapitato. Quindi il coordinatore attende "done" ma allo scadere di un ulteriore timeout rinuncia e termina. Se ora il partecipante caduto è riavviato rimane in attesa perenne di un messaggio di "commit/abort".
Ancora una volta la soluzione è prevedere un timeout per il partecipante, al termine del quale l'attore termina, di fatto, in abort, violando la semantica del ready.
Insomma, si possono prevedere soluzioni che funzionino nella maggior parte dei casi reali (ripetizione di messaggi, ack sui messaggi finali, ecc…), ma se si vuole la certezza che nessuno resti bloccato (magari bloccando anche le risorse) l'unica soluzione è dare un timeout all'intero protocollo, al termine del quale sia il coordinatore sia i partecipanti non sono più tenuti a rispettare i propri impegni. Questo porta con tutta probabilità a violare la semantica del protocollo e comporta il rischio di lasciare il pool di risorse in uno stato inconsistente (anche se permette di liberare le singole risorse), perciò dovrebbe essere tenuto come "ultima carta da giocare".
Se al termine della transazione il coordinatore produce un report che ne descrive l'esito è possibile esaminarlo in seguito per tentare azioni correttive sulle risorse nel caso siano in uno stato inconsistente.
Il protocollo di accesso alle risorse da parte di attori remoti
Un attore del 2PC Protocol deve interagire anche con la risorsa sulla quale deve operare, oltre che con gli altri partecipanti al 2PC.
Quindi è necessario specificare un secondo protocollo che permetta all'attore di ottenere un'interfaccia remota per la risorsa. In seguito, tramite l'interfaccia ottenuta, l'attore potrà aprire (o chiudere) correttamente una sessione di lavoro (operazioni eseguite durante un'apertura di sessione potrebbero essere: autenticazione, acquisizione di lock, ecc…). Dato che si è affermata la scelta di fornire oggetti interfaccia diversi ad attori diversi, per aumentare la flessibilità e la modificabilità del sistema (si veda la sezione "L'architettura generale"), è necessario prevedere un componente "factory di interfacce", da aggiungere all'architettura di base. Un attore del 2PC interessato ad un'interfaccia si rivolgerà alla factory che gliene fornirà una, dopo la conclusione del protocollo di accesso (durante il quale si potrebbe svolgere la procedura di autenticazione).
In questa sezione non si specificherà oltre il protocollo di accesso. Preme soprattutto affermare la necessità di specificarne uno, anche semplice, e di prevedere un componente aggiuntivo (la factory). Come questo componente sia realizzato e come interagisca con gli attori del 2PC dipende molto dal paradigma di programmazione scelto (C/S o MA). Si rimanda alle sezioni successive per l'implementazione.
Implementazione
Il termine "implementazione" potrebbe non sembrare del tutto corretto se usato per definire quanto scritto nelle sezioni seguenti. Si intenda con questo termine che da qui in poi si farà riferimento esplicito a tecnologie utilizzate nell'implementazione del sistema (come il sistema ad agenti mobili SOMA), mentre i discorsi svolti in precedenza si riferivano a scelte progettuali generali. Nelle prossime sezioni, si discuteranno ancora scelte progettuali (la scelta stessa del paradigma di programmazione ad agenti mobili piuttosto di quello client-server, è una scelta di progetto e non di implementazione). Tuttavia queste scelte possono essere modificate senza intaccare l'impostazione generale del sistema, descritta fino a questo punto.
La prima scelta da fare è obbligata se si vuole utilizzare SOMA come supporto per lo sviluppo di applicazioni ad agenti mobili. Si tratta della scelta del linguaggio di implementazione: SOMA è scritto in Java, quindi tutte le applicazioni che usano SOMA devono essere scritte in Java.
L'applicazione del paradigma ad agenti mobili e la sua implementazione attraverso SOMA
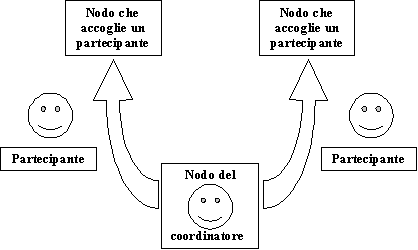
I ruoli del 2PC Protocol possono essere impersonati da agenti mobili. In particolare ogni partecipante può essere rappresentato da un agente. Un agente "speciale" (di una classe differente per usare termini della OOP) può coprire il ruolo del coordinatore.
Il coordinatore è, in effetti, un agente stazionario, mentre i partecipanti sono agenti mobili. Lo schema adottato è lo "Split", cioè gli agenti partono dallo stesso nodo (quello del coordinatore), raggiungono destinazioni differenti e non ritornano a casa al termine della sessione (a differenza di quanto accade in uno schema "Split - Join").
Ogni partecipante deve, una volta arrivato a destinazione, seguire il protocollo di accesso alle risorse locali, quindi acquisire la risorsa, completare il 2PC e rilasciare infine la risorsa.
Come un agente mobile può acquisire un'interfaccia alla risorsa
Come già detto in precedenza un agente mobile appena giunto in un nodo come prima cosa deve procurarsi un oggetto interfaccia per poter lavorare con la risorsa locale. Si noti che ogni operazione svolta dall'agente a questo scopo è un'operazione locale.
Si possono proporre due modi per ottenere il risultato desiderato:
Le due soluzioni possono essere ritenute equivalenti. Bisogna notare tuttavia che per come gli agenti si comportano in SOMA, per realizzare la seconda soluzione sarebbe necessario estendere le classi del package SOMA e in particolare bisognerebbe dotare la classe Environment di un ulteriore campo, cioè dell'oggetto factory.
La soluzione effettivamente implementata è la prima. In particolare il server realizzato:
Il client si rivolge al server spedendo una richiesta ad una porta locale nota. La richiesta contiene l'AgentID del client necessario per recapitare la risposta.
Il meccanismo di risposta è stato concepito in modo che un agente partecipante utilizzi sempre un unico meccanismo di ricezione (la mailbox) sia se deve comunicare col suo coordinatore sia se si rivolge al server.
Si è scelto inoltre di realizzare il server con un agente stazionario perché in questo modo si delega a SOMA la creazione di un demone che esegua il codice del server.
Come un agente evita di bloccarsi in ricezione
Si è detto che l'unico meccanismo di ricezione adottato è la ricezione tramite mailbox. Purtroppo le operazioni di ricezione sulla mailbox sono bloccanti. E' necessario quindi pensare ad un meccanismo di timeout. La soluzione adottata è semplice: prima di eseguire una "receive" sulla mailbox l'agente attiva un timer (un thread indipendente) che allo scadere di un intervallo di tempo spedisce un messaggio alla mailbox dell'agente, sbloccando quest'ultimo. Altre soluzioni introdurrebbero disomogeneità nei meccanismi di sincronizzazione e comunicazione dell'agente, e sono quindi meno indicate.
Come un agente può soddisfare il requisito di persistenza
Se si vuole che le transazioni sulle risorse siano persistenti, bisogna rendere persistenti gli agenti coinvolti in esse. Sebbene SOMA fornisca un meccanismo di salvataggio degli agenti in un place, questo non è molto adatto. Infatti, se un agente richiede di essere salvato (tramite opportuna chiamata all'AgentManager), difatti produce il salvataggio di tutti gli agenti presenti sul place. Inoltre perché un agente possa essere salvato deve essere bloccato, cioè deve in qualche modo interrompere l'esecuzione. In pratica questo significa che un agente può essere interrotto in qualunque momento a causa della chiamata "agentManager.save" effettuata da un altro agente.
Perciò è di gran lunga preferibile modificare tale meccanismo (utilizzando opportune sottoclassi delle classi SOMA) o prevederne uno diverso che non coinvolga SOMA.
La scelta effettuata in fase di implementazione è la seconda: ogni agente salva il proprio stato su un file diverso, dopo aver informato il sistema che sarà necessario ripristinare l'agente in caso di crash.
Note conclusive
Non si è prodotta alcuna implementazione secondo il modello C/S come era invece stato annunciato negli obiettivi.
Inoltre l'implementazione del sistema nel suo complesso è lacunosa: non c'è un'integrazione complessiva dei vari componenti e manca una GUI che sia orientata sia all'utilizzo da parte dell'utente sia al debugging e alla comprensione degli errori.
Anche per questo motivo, il debugging è stato approssimativo. Infatti, la verifica del sistema è stata condotta per mezzo di demos, cioè di esempi cablati in alcuni frammenti di codice che utilizzano i componenti realizzati. Questi demos sono stati fatti girare con successo sulle stazioni Sun del Lab2, utilizzando una JVM 1.2.2 Solaris native threads.
Per il paradigma di programmazione ad agenti mobili e SOMA:
Per Java: