MAGAZZINO VIRTUALE
di Alessandro Pezzi, mat. 2148 - 54265
SPECIFICHE DEL PROBLEMA
Un consorzio è
costituito da n aziende, ciascuna dotata di un proprio magazzino e di un
proprio punto vendita, sparse sull' intero territorio nazionale e facenti capo alla
sede centrale.
Ogni azienda possiede un proprio DB con tutti i prodotti presenti in magazzino,
ma al momento non vi è la possibilità di accesso da parte delle altre aziende
alla base di dati:
ogni azienda deve mandare (via fax!) gli ordini dei pezzi esauriti o in
esaurimento alla sede centrale, la quale provvede direttamente o tramite il
fornitore del pezzo all'evasione dell' ordine: ciò impedisce di poter
effettuare ordini di prodotti esauriti presso le altre aziende,funzionalità che
permetterebbe di reperire i pezzi richiesti in tempi più rapidi e in modo da
ottimizzare le risorse e da minimizzare le giacenze.
L' obiettivo è quello di realizzare un sistema software di rete in grado in
futuro di automatizzare la richiesta e l' ordinazione dei pezzi, fornendo ora
la visibilità delle risorse disponibili presso tutte le altre aziende del
consorzio.
ANALISI
Il caso in questione
rappresenta un problema di reperimento di informazioni distribuite all' interno
di una rete di calcolatori dislocati su una vasta zona geografica.
Il sistema software che si vuole progettare dovrà quindi fornire un servizio
con precisi vincoli prestazionali relativi ai tempi di
risposta alle richieste, alla disponibilità
stessa del servizio che deve essere continua, alla correttezza delle risposte fornite .
TEMPI DI RISPOSTA: per un servizio di questo tipo (richieste dati su disponibilità prodotti) sono tollerabili attese da alcuni secondi fino a qualche minuto: per la natura stessa del problema le richieste sono operazioni “sporadiche” cioè non troppo frequenti (non si esaurisce la merce ad ogni secondo..) quindi la probabilità di sovraccarico dovrebbe essere bassa; occorre però analizzare attentamente l' impatto dei tempi di trasporto dei dati(viaggeranno sulla rete Internet, con tutti i problemi connessi).
DISPONIBILITÀ
DEL SERVIZIO: è abbastanza importante che le richieste vengano
soddisfatte con continuità; è quindi necessario un minimo di replicazione da
parte del fornitore del servizio ( SERVER che deve fungere anche da DNS)
per far fronte ai possibili guasti.
Data la natura del problema, cioè il reperimento di pezzi che possono essere
presenti in molti magazzini, non è “assolutamente” necessario che il
richiedente riceva proprio tutti i dati da tutti i magazzini, ma in linea
teorica è sufficiente che trovi le quantità di pezzi di cui ha
bisogno: se invece si suppone che un cliente (ad esempio la Sede
Centrale) usi il sistema software per monitorare lo stato di tutti
i magazzini per effettuare eventualmente forniture in maniera automatica allo
scendere delle giacenze sotto una certa soglia, occorre almeno introdurre un
meccanismo che permetta al cliente di sapere da chi ha ricevuto i dati e chi
non ha risposto.
CORRETTEZZA
DELLE RISPOSTE FORNITE: è in generale un aspetto molto
importante ma si assume in questo caso che i dati forniti dai DB locali siano
allineati esattamente con la situazione reale:
inoltre a causa dei tempi di trasporto può accadere che i dati ricevuti dai
clienti non corrispondano più alla realtà ( il magazzino può aver nel frattempo
evaso un ordine o ricevuto una fornitura):l'operazione eseguita (ricerca dei
Pezzi) è comunque “a sola lettura”, nel senso che non modifica lo stato del
sistema per cui si trascura questo tipo di problema.
PROGETTO E REALIZZAZIONE
Si è scelto di realizzare il
sistema software con un modello ad Agenti Mobili, ritenuto il più adatto per
quanto riguarda le problematiche di reperimento dati e monitoraggio in
ambiente distribuito.
Il sistema verrà quindi realizzato in linguaggio Java (che fra l'altro
offre la possibilità di estendere il sistema per poter effettuare tutte
le operazioni da una pagina WEB e in sicurezza) con l' appoggio di
S.O.M.A., un software di supporto agli agenti mobili realizzato dal Dipartimento
di Informatica e Sistemistica della Facoltà di Ingegneria dell'Università
di Bologna.
Si vuole realizzare una struttura non gerarchica, costituita
da Server e Magazzini dove però i Server forniscono semplicemente i meccanismi
di comunicazione e conoscenza reciproca per i Magazzini, che sono isoli
interessati al “traffico”degli agenti: ogni Magazzino alla creazione deve
registrarsi presso un Server, il quale lo tiene informato in modalità
PUSH dell'ingresso di ogni nuovo Magazzino:tale Server si dovrà occupare
anche di avvisare tutti gli altri Server e tutti gli altri Magazzini già
presenti.
Per fare ciò occorre introdurre un apposito protocollo di comunicazione fra le
varie entità.
PROTOCOLLO DI COORDINAMENTO FRA LE ENTITA' COMPONENTI IL SISTEMA
Il sistema deve essere
concepito e realizzato come “aperto” e “modulare”, cioè in grado di
evolvere e crescere nel tempo senza l' imposizione a priori di limiti
stringenti sul numero delle entità che lo compongono: in questo
modo è possibile aggiungere quanti Server e Magazzini si vogliono,
assicurandola piena conoscenza reciproca.
Questo è reso possibile grazie all' introduzione di un protocollo di
comunicazione fra le diverse parti costitutive dell' ambiente, che tutti
devono rispettare una volta entrati nel sistema.
Vediamo ad esempio cosa accade quando entra in scena un nuovo Server che
concorre assieme a quelli già presenti a realizzare un DNS distribuito e
replicato:
|
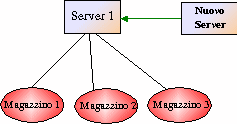
Supponiamo che un Server
(Server1) sia già presente nel sistema: esso è in attesa sulla Porta
di Registrazione dei Sever ( PRS , ad es. porta 18000)
che se ne registri uno nuovo, e sulla porta di registrazione dei Magazzini (PRM,
ad es. 18002) è in attesa della registrazione da parte di uno nuovo di essi.
|
|
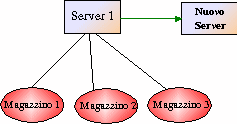
A questo punto il Server1 invia al Nuovo Server, ancora
collegato sulla PRS, il
vettore dei Magazzini presenti nel sistema, in modo da informarlo sulla
struttura del sistema e chiude la Socket, ponendosi in attesa di un nuovo
Server.
|
|
Il Nuovo Server riceve sulla PRS il vettore dei
Magazzini e lo memorizza al suo interno nella lista dei
Magazzini del sistema, poi chiude la Socket.
|
|
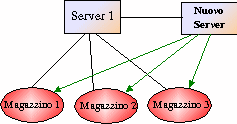
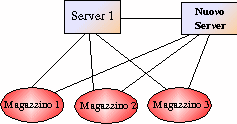
A questo punto è stato
raggiunto uno stato di consistenza globale: tutti i Server hanno la stessa
tabella dei Server e dei Magazzini, inoltre ogni Magazzino può contare sull'
appoggio di tutti i Server per tenere aggiornata la propria lista dei
Magazzini presenti nel sistema:
|
Ora analizziamo il caso in cui sia un Nuovo Magazzino a registrarsi nel sistema:
|
Supponiamo che nel sistema
ci siano già alcuni Server e qualche Magazzino: il Magazzino crea una Socket
e si collega ad uno qualsiasi dei Server (es. Server1) sulla Porta di
Registrazione dei Magazzini (PRM, ad es.
18003), inviando il proprio PlaceInfo:
|
|
Il Server1 riceve il PlaceInfo sulla PRM, aggiorna la propria tabella dei Place registrati ed effettua l' aggiornamento degli altri Server e di tutti i Place registrati nel sistema: per fare ciò crea una Socket e si collega ad ogni Server sulla Porta di Aggiornamento dei Magazzini (PAM , ad es. 18004), inviando il PlaceInfo del nuovo Magazzino, poi chiude la Socket. Allo stesso modo si collega ad ogni Magazzino sulla Porta fra Server e Magazzini (PSM , ad es. 18004),inviando il PlaceInfo del nuovo Magazzino, poi chiude la Socket.
|
|
Tutti i Server e tutti i Magazzini ricevono il PlaceInfo e aggiornano la lista dei Place registrati inserendo il nuovo entrato. E' stato così raggiunto un nuovo stato di consistenza in cui tutti i vecchi Server e Magazzini sono stati informati della presenza del Nuovo Magazzino, e questo conosce tutti gli altri Magazzini presenti.
Tutti i Server sono ora in attesa della registrazione di
un nuovo Server sulla porta PRS o di un nuovo Magazzino sulla PRM
, inoltre sono anche in attesa di un aggiornamento da parte di un Server già
presente nel sistema sulla porta PAS in caso di ingresso nel
sistema di un Nuovo Server; allo stesso modo sono in attesa di
un aggiornamento da parte di un Server già presente nel sistema sulla porta PAM
in caso di ingresso di un nuovo Magazzino. |
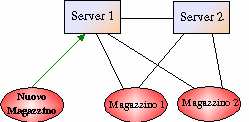
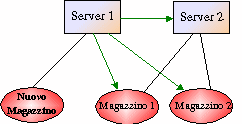
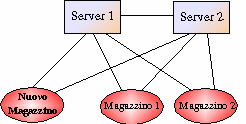
STRUTTURA DEI SERVER E DEI
MAGAZZINI PER SUPPORTARE IL PROTOCOLLO DI
COORDINAMENTO
SERVER
Per poter realizzare il protocollo precedentemente descritto i Server devono
essere strutturati come processi multithread
, in grado cioè di poter eseguire più flussi di esecuzione contemporaneamente,
ognuno dei quali si deve occupare di fornire specifici servizi.
In particolare sono necessari 4 diversi trhead
:
Thread di Registrazione Server: crea una Socket di ascolto sulla porta PRS,
e attende che un nuovo Server si registri inviando il proprio PlaceInfo:
dopo averlo ricevuto,il thread lo aggiunge nell' apposito vettore e
risponde inviando sulla Socket ancora aperta il Vettore dei Server e
quello dei Magazzini,poi procede all' aggiornamento degli eventuali Server già
presenti inviando loro sulla porta PAS il PlaceInfo del nuovo
Server; a questo punto si pone nuovamente in attesa della registrazione di
un altro Server(il thread è realizzato con un ciclo infinito while true..
).
Thread di
Registrazione Magazzini: crea una Socket di ascolto sulla porta PRM,
e attende che un nuovo Magazzino si registri inviando il proprio
PlaceInfo: all' arrivo di questo il thread aggiorna internamente al
Server il Vettore dei Magazzini e risponde inviando sulla Socket
ancora aperta il Vettore dei Magazzini già registrati, poi procede all'
aggiornamento degli eventuali Server e Magazzini già presenti inviando
loro sulla porta PAM (per quanto riguarda i Server)e PSM
(per quanto riguarda i Magazzini) il PlaceInfo del nuovo Magazzino;
a questo punto si pone nuovamente in attesa della registrazione di un altro
Magazzino ( anche questo thread è realizzato con un ciclo infinito while true
.. ).
Thread di
Aggiornamento Server: crea una Socket di ascolto sulla porta PAS,
e attende che un Server già presente nel sistema mandi un aggiornamento
inviando il PlaceInfo di un nuovo Server: dopo averlo ricevuto il thread lo
aggiunge nell' apposito vettore e si pone in attesa di un nuovo aggiornamento (
anche questo thread è realizzato con un ciclo infinito while true .. ).
Thread di
Aggiornamento Magazzini: crea una Socket di ascolto sulla
porta PAM, e attende che un Server già presente nel sistema mandi un
aggiornamento inviando il PlaceInfo di un nuovo Magazzino:dopo averlo ricevuto
il thread lo aggiunge nell' apposito vettore e si pone in attesa di un nuovo
aggiornamento ( anche questo thread è realizzato con un ciclo infinito while
true .. ).
MAGAZZINO
Per quanto riguarda i Magazzini è sufficiente un solo
Thread:
Thread di
Aggiornamento: crea una Socket di ascolto sulla porta PSM
, attraverso la quale riceve da un Server il PlaceInfo di un nuovo
Magazzino registratosi nel sistema: il thread non fa altro che inserire
il PlaceInfo nell' apposito vettore dei Magazzini e si pone poi in attesa di un
nuovo aggiornamento.
Quindi il flusso di esecuzione di ogni Server si può così sintetizzare:
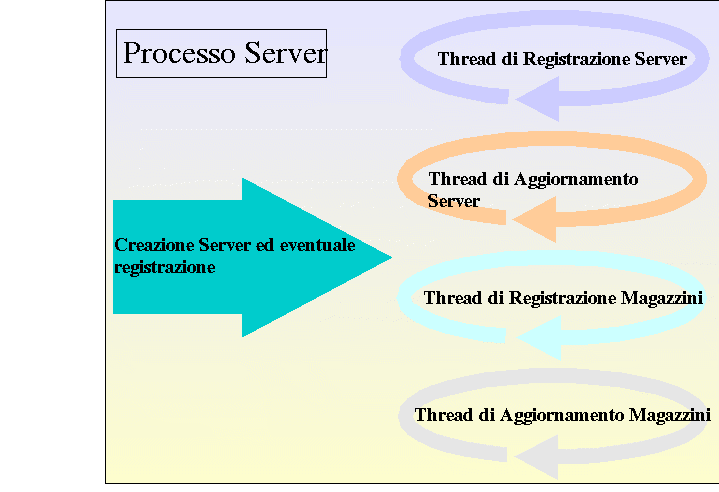
Mentre il flusso di esecuzione di un Magazzino è così rappresentato:
COSTI DI COMUNICAZIONE DEL PROTOCOLLO DI COORDINAMENTO
Per mantenere continuamente aggiornati Server e Magazzini è stato introdotto un
protocollo di cui ora si stima il costo in termini di comunicazione.
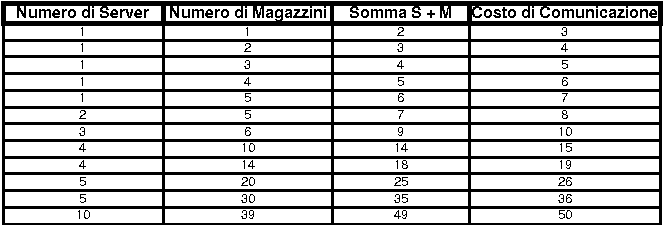
Se poniamo uguale a 1 il costo di comunicazione fra due entità qualsiasi e
consideriamo che il sistema sia costituito da N magazzini e M
server, l'introduzione di un nuovo Server ha un costo di comunicazione
pari a:
Cns= C registrazione_server+ Caggiornamento_server =2 + (M-1) = M+1
mentre l' introduzione di un nuovo Magazzino (evento + frequente) ha un
costo di comunicazione pari a:
Cnm= C reg_magazzino +Caggiornamento_magazzini +Caggiornamento_server
= 2+ N + (M-1) = N+M+1
Il costo di comunicazione è quindi lineare in entrambi i casi (nel numero dei
Server nel 1° caso e nella somma di Server e Magazzini nel 2°caso).
Tabella di Esempio
Grafico
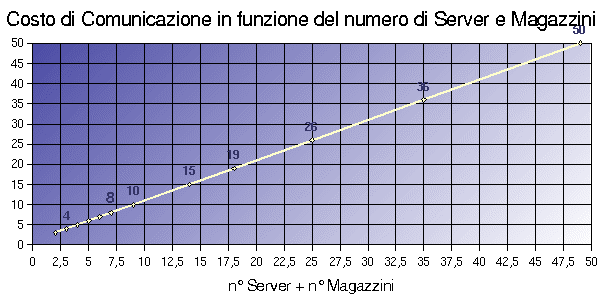
Conclusioni:
poiché il costo
è lineare e le operazioni di inserimento di un nuovo Server o Magazzino sono
sporadiche (normalmente avviene solamente la circolazione e la elaborazione da
parte di Agenti Mobili in transito sul nodo) è auspicabile l' introduzione di
un numero sufficiente di Server per assicurare una buona Fault
Tollerance: l'overhead in comunicazione che si verifica durante l'
introduzione di una nuova entità è in ogni caso ben tollerato dal
sistema.
Sviluppi:
Il protocollo introdotto non assicura in modo
alcuno il controllo reciproco fra i Server e gli altri Server e fra i Server e
i Magazzini: in seguito alla “caduta” di un Server o di un Magazzino
nessuno si accorge del problema e di conseguenza il fatto deve essere gestito a
livello di Agente Mobile, il quale deve implementare meccanismi che gli
permettano di “saltare” nodi guasti e di attendere in caso di nodo di origine
momentaneamente guasto.
Si potrebbe pensare di operare un controllo periodico da parte dei Server sugli
altri Server o sui Magazzini, ad esempio compiendo a intervalli di tempo
prestabiliti una sorta di “ping” verso gli altri per verificare la loro
vitalità: in questo caso i costi di comunicazione diventerebbero però
altissimi e quindi molto probabilmente questa strada non è percorribile.
TOLLERANZA AI GUASTI
Tolleranza ai
guasti sul fronte Server
L' architettura del sistema è stata
progettata per supportare l' introduzione di un numero qualsiasi N di Server,
in grado ciascuno di mantenere l' intera struttura in uno stato
consistente: tutti i Server infatti hanno lo stesso contenuto informativo
e tutte le funzionalità per far sopravvivere il Sistema.
Ogni Server va poi collocato su un nodo della rete differente dagli altri
Server, per cui ogni Copia è Attiva e indipendente dalle altre.
Di conseguenza si possono verificare fino ad N-1 guasti su N-1 nodi diversi
senza che il sistema ne risenta e continui a funzionare correttamente.
Occorre tuttavia tenere conto dell' alto costo in termini di comunicazione
introdotto dal protocollo di aggiornamento Server-Server e
Server-Magazzino, per cui sarebbe buona norma limitare
il numero di Server a poche unità.
Tolleranza ai guasti sul fronte Magazzino
Per quanto riguarda i Magazzini non è
invece stato introdotto nessun tipo di replicazione, per cui un guasto sul nodo
di un Magazzino rende quest' ultimo inservibile sia dal punto di vista del
reperimento dei dati da parte degli altri Magazzini, sia per quanto riguarda le
richieste da questo verso gli altri.
Mentre il primo aspetto può essere tranquillamente tollerato (se un agente non
riesce a migrare sul nodo guasto può sempre reperire i pezzi presso altri
magazzini, poiché tutti vendono la stessa merce)il secondo problema è più
grave in quanto limita drasticamente l' operatività del magazzino stesso.
COMPORTAMENTO DEGLI AGENTI
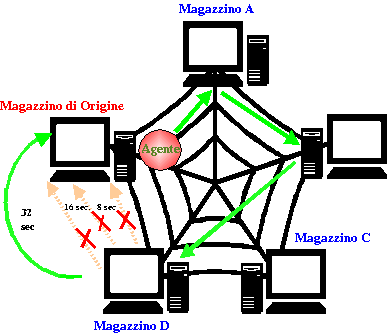
1a Soluzione: FirstAgent
Ogni Magazzino, nel momento in cui effettua
una richiesta per un determinato Pezzo, crea un Agente, passandogli come
parametro il Pezzo in questione e il vettore dei Magazzini da Vistare.
A questo punto effettua la migrazione verso il primo Magazzino e , una volta
giuntovi, apre il file contenente l' elenco dei Pezzi disponibili e cerca il
pezzo che gli interessa: una volta trovatolo inserisce i dati in un
Vettore, assieme al nome del Magazzino, e migra verso il Magazzino successivo.
Dopo aver visitati tutti i Magazzini “attivi” (cioè quelli verso cui la
migrazione va a buon fine!) l' agente torna al Magazzino di origine portando
con se i dati raccolti nel suo viaggio e rendendoli disponibili a chine aveva
fatto richiesta.
Nell'agente sono stati inseriti due meccanismi di controllo atti a far
fronte ad una possibile “caduta” di un qualche Magazzino:
1) il primo meccanismo reagisce al
fallimento della migrazione verso un place da visitare, e opera semplicemente
saltando il Place e migrando verso il suo successivo: questa scelta è
stata fatta per questioni di “velocità”, infatti anche senza conoscere
esattamente l' intero contenuto di tutti i magazzini è solitamente possibile soddisfare
le necessità di chi ha effettuato la richiesta; inoltre è così possibile
anche saltare Magazzini non più presenti nel sistema (cioè smantellati) ma
ancora registrati nei Server; si potrebbe invece ad esempio inserire il
Magazzino guasto in un apposito vettore e tentare alla fine del giro di
tornarvi, sperando che si sia rimesso in funzione o attendendo che venga
ripristinato: il tempo di reperimento dei dati aumenta e assume la
caratteristica di essere molto variabile e difficilmente predicibile.
|
|
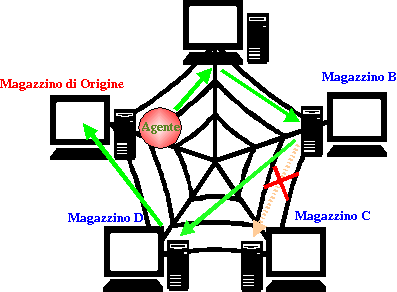
2) Il secondo meccanismo reagisce invece ad una eventuale “caduta” del
Magazzino che ha effettuato la richiesta.
Se infatti l' agente al suo ritorno non riuscisse a tornare“a
casa” morirebbe in seguito al fallimento della migrazione:esso
invece si accorge del problema e si pone in uno stato di quiescenza per un
certo periodo , per poi ritentare il ritorno; a questo scopo l' agente
imposta un timeout e raddoppia il tempo di attesa ad ogni fallimento
(es.8 sec, 16sec, 32 sec, 64 sec, 128 sec , ecc...) fino ad un TMAX (es.
qualche ora) dopo di che l' agente muore, perdendo i dati acquisiti durante
la sua ricerca.
|
Il primo tentativo di ritorno al Magazzino di partenza fallisce, così come il 2° dopo 8 secondi, così come il 3° dopo 24 sec. (8 + 16) , mentre al 4° dopo 56 sec (24 +32) la migrazione ha successo. |
2a Soluzione: SecondAgent
Ogni Magazzino, nel momento in cui effettua
una richiesta per un determinato Pezzo, crea un Agente per ogni Magazzino
registrato nel sistema, passandogli come parametro il Pezzo in questione e
il Vettore dei Pezzi trovati (che risiede sul client , è semplicemente un
riferimento e non verrà usato durante la migrazione: l' Agente vi inserisce il
Pezzo trovato solamente dopo essere tornato a casa);
A questo punto effettua la migrazione verso il
Magazzino assegnatogli e una volta giuntovi, apre il file contenente l' elenco
dei Pezzi disponibili e cerca il Pezzo che gli interessa: appena trovato
memorizza i dati al proprio interno ( in una MyTupla, ovvero un Pezzo +quantità
+ Magazzino), ed effettua la migrazione verso casa.
Una volta giunto nel Magazzino di Partenza procede all' aggiornamento del
Vettore dei pezzi trovati (che in realtà è un vettore di MyTupla).
Anche in questo caso sono presenti i 2
meccanismi di reazione al fallimento della migrazione:
- se un Agente non riesce a migrare verso
il proprio Magazzino di competenza , segnala al Cliente
il fallimento e muore: si potrebbe pensare invece di fargli ritentare
la migrazione...
- se un Agente non riesce a tornare al Place di Partenza
attiva il piano di attesa a Time-out crescenti fino a che non riesce
la migrazione o non raggiunge il Tmax: nel primo caso procede
regolarmente ad aggiornare il vettore, nel secondo muore
perdendo le informazioni raccolte.
|
Es.
|
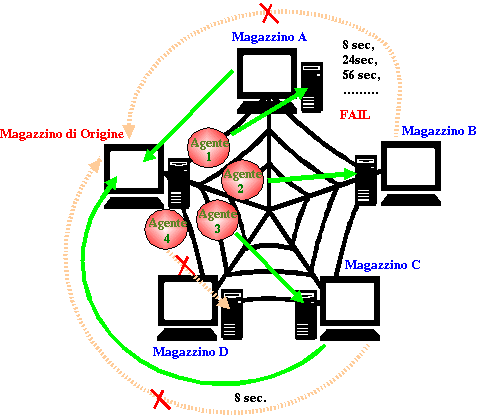
Questo modello ha il difetto della sincronizzazione fra cliente ed Agenti,
ovvero ogni Agente aggiorna in modalità asincrona il vettore dei pezzi trovati
e il cliente non sa quando lo stato di questo vettore è definitivo: se ad
esempio un Agente non riesce a tornare per problemi di rete, esso va
aspettato fino allo scadere del suo Tmax; una possibile soluzione potrebbe
essere quella di fornire il vettore solo in seguito al rientro di almeno un
numero minimo di agenti ritenuto significativo.
FINE