Condivisione di file tramite FTP Server
Il seguente progetto parte dalla realizzazione di un semplice FTP Server che implementa solo alcuni dei possibili comandi specifici del protocollo FTP per poi realizzare una condivisione di risorse tra diversi server. Questa condivisione si attua mettendo a disposizione da parte di ogni server nei riguardi degli altri server attivi i file presenti nella directory di lavoro; si viene così a creare una sorta di LISTA VIRTUALE dalla quale ogni cliente di un qualsiasi server può prendere i file di cui necessita. La realizzazione è stata conseguita tramite l' uso di Java e precisamente del jdk1.2.
Il progetto risulta di semplice formulazione e anche ad una primo sguardo può sembrare di semplice soluzione, questo però se non si considerano vari aspetti collegati alla astrazione che si vuole realizzare, quali:
E' iniziando a rispondere a domande come queste che ho potuto cercare una personale soluzione al problema.
Innanzitutto sono dovuto partire dalle specifiche del protocollo FTP presenti nell' RFC959 indispensabili per realizzare il nucleo del progetto ovvero il Server FTP. In seguito ho dovuto determinare il modo di correlare e coordinare i vari server analizzando un singolo aspetto alla volta e cercando un compromesso tra le varie caratteristiche che avevo individuato e che ritenevo il sistema dovesse avere. Inizio comunque seguendo il percorso che mi ha portato alla realizzazione finale.
Introducendo l' FTP, o meglio File Transfer Protocol, non si può che ribadire che è un protocollo per il trasferimento di file tra calcolatori solitamente remoti. Si prefigge, principalmente, quattro obbiettivi: 1) promuovere la condivisione di file, 2) promuovere indirettamente l' uso di computer remoti, 3) proteggere le risorse di host dalle modifiche ad opera di utenti, 4) trasferimento di dati in modo efficiente e corretto. L' FTP è un protocollo molto semplice ma dalle innumerevoli caratteristiche, basti pensare ai numerosi comandi implementati, che lo rendono ancora oggi molto utile, nonostante le applicazioni Web interattive e graficamente più evolute hanno oramai invaso molti settori, quale appunto la condivisione di file.
Innanzitutto l' FTP si basa su un protocollo affidabile quale il TCP per effettuare le comunicazioni tra Host e Client. Il protocollo TCP è orientato alla connessione e si basa su un protocollo di base non affidabile quale l' IP per realizzare comunicazioni affidabili. Le funzionalità messe a disposizione da TCP sono le seguenti:
Gli elaboratori connessi in rete sono identificabili tramite un indirizzo IP , ovvero una sequenza di 32 bit, anche se comunemente si utilizza una rappresentazione di più facile lettura, ovvero la rappresentazione per decimali puntati (esempio: 127.0.0.1). Gli indirizzi sono, in ultima analisi, assegnati dalla Internet Assigned Number Authority . La connessione TCP necessita inoltre di un numero di porta logica, astrazione che permette di identificare un singolo processo attivo sul computer, mentre il terminale della comunicazione è la socket che rappresenta una interfaccia omogenea per i servizi. Molti numeri di porte sono già stati assegnati dalla Internet Assigned Number Authority per l' utilizzo del protocollo TCP, porte utilizzate per fornire servizi specifici (tra cui anche FTP), mentre un client utilizza solo numeri di porta superiori a 1024.
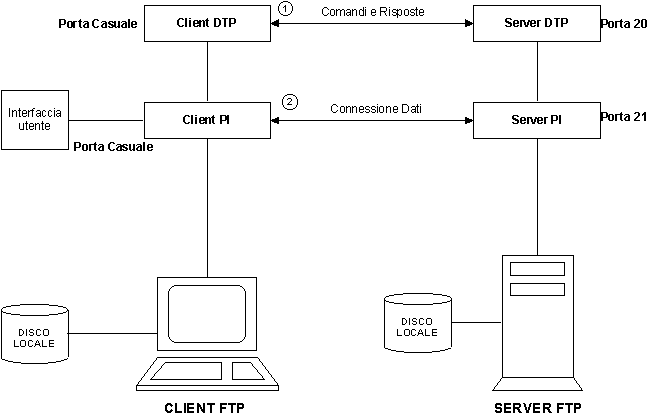
Il protocollo FTP utilizza due processi distinti per il trasferimento dei dati, ognuno assegnato ad una porta specifica.
Durante una sessione FTP la connessione di controllo rimane sempre attiva mentre quella dati soltanto quando vengono effettivamente scambiati dei dati; entrambe sono comunque bidirezionali.
I comandi FTP si possono articolare in quattro categorie:
Inoltre vi sono i Codici di risposta del server FTP.
Nel documento RFC959 sono indicati i comandi da implementare per ottenere un server utilizzabile, essi sono: USER, QUIT, PORT, TYPE, MODE, STRU, RETR, STOR, NOOP ; sono altresì indicati i parametri di trasferimento standard : TYPE - ASCII Non-print, MODE - Stream, STRU - File.
La mia realizzazione implementa questi comandi base con in aggiunta i comandi LIST, DELE, PASS . Per rendere parallelo il server ho realizzato due classi, la prima, che ho chiamato "serverFTP" alla esecuzione si pone in attesa di eventuali connessioni alla porta 21, quindi alla accettazione lancia un Thread (la seconda classe "serverRichiesteFTP") che si occupa di gestire la comunicazione con il client fino alla disconnessione di quest' ultimo. La classe "serverRichiesteFTP" si occupa quindi di interpretare i comandi e di inviare o ricevere dati dal cliente. Registro anche un file che tiene traccia delle operazioni effettuate. Per la realizzazione delle comunicazioni ho utilizzato le classi ServerSocket e Socket di Java. La realizzazione del server è praticamente terminata, ora manca il protocollo di coordinamento.
Protocollo di Coordinamento: generalità
L' astrazione prevede che ogni server metta a disposizione degli altri server i file che esso stesso mette a disposizione degli utenti connessi. I server quindi si troveranno ad indirizzi diversi l' uno dall' altro e saranno indipendenti tra loro, nel senso che l' unica condivisione che voglio realizzare è quella relativa alla possibilità di ottenere file. Questa scelta è obbligata se si vuole rendere ogni server indipendente per ciò che riguarda scelte locali, così possiamo trovare il medesimo file in più nodi (ipotizzando che a nome uguale corrisponda file uguale). L' utente connesso a uno di questi server potrà quindi ottenere file locali e remoti (presso altri server attivi) ed eseguire operazioni prettamente locali quali la cancellazione e la registrazione di un file. Ovviamente la presenza di un file locale e uno remoto uguali obbliga un utente a ottenere quello locale, questo per ragioni di efficienza: che senso avrebbe recuperare un file da un altro server se è identico a quello che si ha già in locale? Invece per la scelta di poter scrivere in locale qualsiasi file anche uguale ad uno remoto senza prevedere alcuna retroazione sui server remoti è dettata da vincoli di indipendenza. Andare ad aggiornare o anche aggiungere o cancellare un file su un nodo remoto sarebbe una operazione non ammissibile perché non potremmo verificare le credenziali che tale utente ha sull' altro server. Pensando alle modalità che permetterebbero ai server di conoscersi ci sono varie possibili soluzioni:
Il principale limite della prima possibilità era quello della scalabilità: aggiungere un ulteriore server comportava l' aggiornamento delle tabelle statiche di ogni server ed inoltre all' aggiornamento di una qualsiasi lista dei file di un server avrebbe richiesto un notevole costo computazionale al server interessato, per non parlare del caso della caduta di un server che sarebbe stata rilevata solo al tentativo di richiesta di un file. La seconda possibilità avrebbe mitigato il limite di scalabilità ma avrebbe lasciato inalterati gli altri problemi, aggiungendone uno nuovo: cosa succede se un server si attiva e l' unico altro che conosce non è attivo? Un giusto compromesso mi è sembrato il Server Coordinatore. Ovviamente non è esente da problemi ma mi sembrava più adatto in questo caso. Il sistema diventa più facilmente scalabile, ogni server deve inviare l' aggiornamento solo al Coordinatore che la propagherà agli altri server inoltre il Coordinatore si occupa anche di monitorare lo stato dei vari server individuando quelli non più attivi. Come inconveniente principale si ha quello che se cade il Coordinatore viene a mancare il collegamento tra i server (anche se solo per alcune operazioni). La possibile soluzione è la replicazione del Coordinatore. Quindi le caratteristiche che dovrebbe avere il sistema sono in sintesi queste:
Per entrare nel dettaglio della realizzazione parto dalle classi realizzate.
L' FTP server è costituito da cinque moduli:
Il Coordinatore è costituito da quattro moduli:
Le strutture dati principali sono:
Sono presenti anche due tipi di strutture di dati utilizzate:
SCHEMA GENERALE DI COMUNICAZIONE
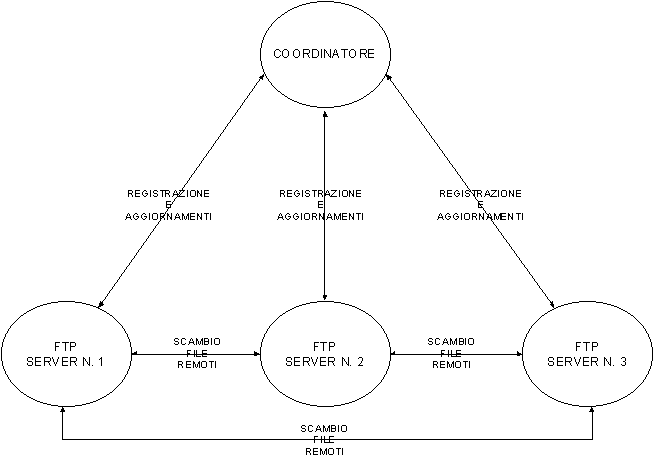
Vediamo la sequenza delle operazioni eseguite in seguito a determinati eventi.
FTP Server
Avvio:
Preparazione delle strutture dati
Esecuzione del processo "registramiFTP" che rimarrà sempre attivo
Attesa di eventuali connessioni di FTP Client
Registrazione (processo registramiFTP):
Creazione della socket di comunicazione e di quella di attesa
Invio della sequenza di registrazione
Predisposizione in attesa di aggiornamenti o richieste
Richiesta connessione:
Esecuzione del processo "serverRichiesteFTP"
Ritorno in attesa di eventuali nuove richieste
Richiesta file (processo serverRichiesteFTP):
Ricerca nella directory locale: se presente lo si invia
Ricerca nella lista dei file degli altri server: se presente....
Si richiede il trasferimento
Si indica il file
Si trasferisce il file e lo si ridireziona al client
Se il file non è presente (in entrambi i casi) si invia un messaggio di errore
Se il server non risponde perché non è più attivo si informa il coordinatore
Upload di un file (processo serverRichiesteFTP):
Se il file esiste viene sovrascritto (in ambito locale)
Se il file non esiste viene creato
Non si verifica se è presente in altri nodi
Si invia un aggiornamento al Coordinatore
Si aggiorna in locale la propria lista
Cancellazione di un file (processo serverRichiesteFTP):
Se il file non esiste si invia un messaggio di errore
Se esiste si effettua la cancellazione
Si invia un aggiornamento al Coordinatore
Si aggiorna in locale la propria lista
Verifica servizio (processo registramiFTP):
Si invia messaggio di conferma
Richiesta registrazione (processo registramiFTP):
Si invia la propria lista di file
Si riceve la struttura dati completa
Si ritorna in attesa di altre comunicazioni
Richiesta file da parte di un altro server (processo registramiFTP):
Verifica dell' esistenza del file
Invio della porta su cui avverrà il trasferimento
Esecuzione del processo "inviaFileFTP" che si occuperà di inoltrare il file al server richiedente
Coordinatore
Avvio:
Esecuzione del processo "verificaServer" che rimarrà sempre attivo
Attesa di eventuali richieste di registrazioni, aggiornamenti
Richiesta di registrazione (processo serverRegistrazioniFTP):
Si riceve la lista dei file del server
Si invia conferma della registrazione
Si invia struttura che memorizza gli indirizzi dei server e i nomi dei file
Si invia l' aggiornamento della struttura agli altri eventuali server attivi
Messaggio di aggiornamento della lista (processo serverRegistrazioniFTP):
Si riceve la lista aggiornata
Si invia messaggio di conferma
Si invia l' aggiornamento della struttura agli altri eventuali server attivi
Messaggio che informa della caduta di un server (processo serverRegistrazioniFTP):
Si riceve l' informazione sul server
Si invia messaggio di conferma
Si aggiorna la lista
Si invia l' aggiornamento della struttura agli altri eventuali server attivi
Verifica dei server (processo verificaServer):
Si invia un messaggio ad ogni server registrato
I server che non rispondono vengono cancellati dalla lista dei server attivi
Si invia un aggiornamento agli altri eventuali server
Ricezione aggiornamento da parte di un server non registrato (processo serverRegistrazioniFTP):
Si richiede la registrazione
Si registra il server
Si effettua l' aggiornamento degli altri eventuali server attivi
Questo disegno visualizza i processi coinvolti.
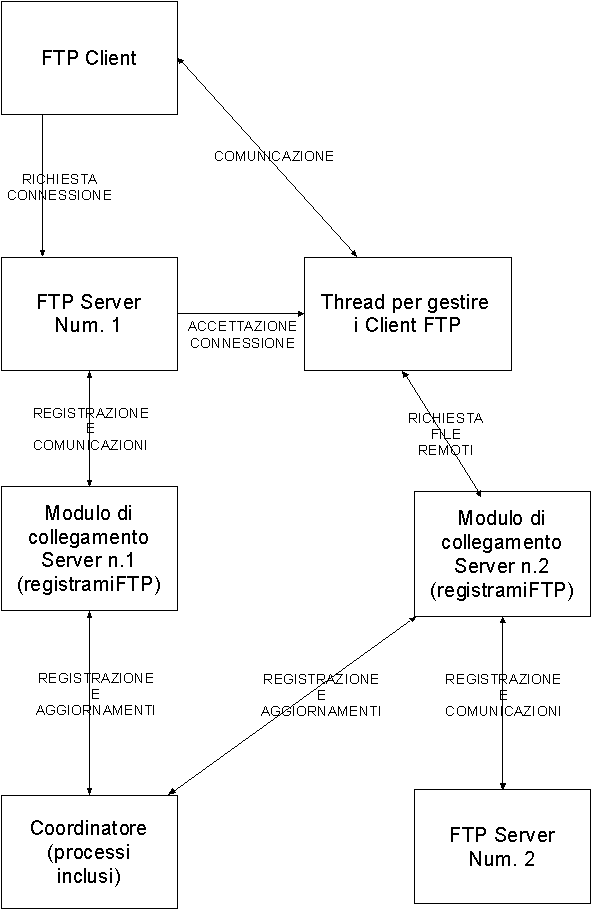
Richiesta di file :
Invio di file:
Cancellazione di file:
Anomalie:
Ho effettuato una prova di funzionamento nel Lab.2 per verificare sia la correttezza del protocollo di coordinamento, sia eventuali sovraccarichi al coordinatore e ai vari server; inoltre ho testato la funzionalità delle procedure nel caso di inconvenienti. Ho effettuato, invece, a casa una prova di carico nel trasferimento di file di varie dimensioni, prova difficile da realizzare in Lab.2 considerando la quantità limitata di memoria sul disco disponibile per ogni account.
Prove del protocollo di coordinamento
Il sistema ha funzionato correttamente durante la prova in Lab.2 e il coordinatore non è sembrato sovraccaricato. I tempi di risposta sono stati molto brevi soprattutto grazie al fatto che tutti i server erano sulla stessa rete locale, probabilmente in presenza di server su reti fisiche diverse e con reti di comunicazioni congestionate i vari server sarebbero stati aggiornati in tempi più lunghi e soprattutto in tempi diversi l' uno dall' altro. Quindi la prova è stata effettuata in una situazione particolarmente favorevole. Comunque essendo i vari server aggiornati tramite Thread concorrenti e indipendenti (un Thread per ogni server da aggiornare) si può presupporre che il coordinatore non rimanga bloccato per lungo tempo per l' aggiornamento (semplicemente il tempo necessario per mettere in esecuzione i vari processi leggeri) e che quindi venga relativamente influenzato dal numero di server registrati. Anche il fatto che i server vengano aggiornati in base all' ordine di registrazione risulta poco influente. Si noti che trascorre un certo tempo, non preventivabile, tra la modifica presso un server e la notifica da parte del coordinatore agli altri server e che quindi i server si troveranno temporaneamente in uno stato incongruente. Nel caso della cancellazione di un file, se questo venisse richiesto si otterrebbe un messaggio di file non presente e quindi il sistema continuerebbe a funzionare correttamente, mentre in presenza di un nuovo file, lo noteremo solo ad aggiornamento avvenuto. Si può ipotizzare, quindi, che i tempi per l' aggiornamento siano esprimibili così:
Si può presupporre che il grafico segua nel caso di una rete locale l' andamento di una retta; in laboratorio sono riuscito a testare fino a 6 server in contemporanea esecuzione su altrettanti indirizzi diversi (limitato dal numero di macchine libere) ed ho utilizzato un aggiornamento sequenziale, senza prevedere la presenza di Thread, così da poter stimare i tempi complessivi per l' aggiornamento, che terminava all' effettiva ricezione del messaggio di aggiornamento da parte dell' ultimo server registrato. Ovviamente questo non è un procedimento efficiente se si esclude il caso di una rete locale. Si può presupporre che in assenza di inconvenienti (server che non risponde prontamente) i tempi abbiano il seguente andamento.
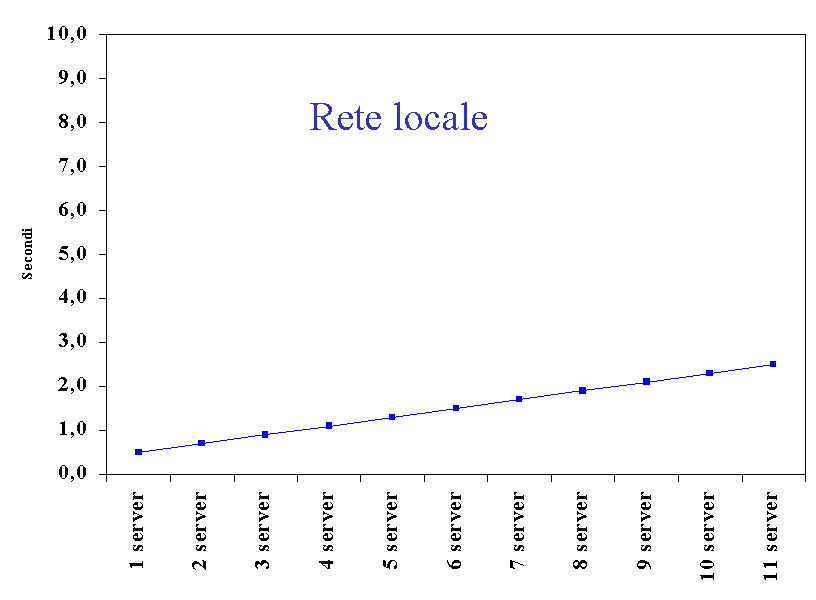
Mentre per il caso di una rete internet è difficile determinare un' andamento, che si presuppone cambi da un momento ad un altro, basti pensare ai percorsi dei pacchetti che non possono essere predeterminati, ma anche dalla disposizione dei server. Anche potendolo testare, non potrei fare alcuna previsione per la difficile ripetibilità e determinazione delle condizioni effettive della rete.

Leggermente diverso è il processo di registrazione perché prevede che il server che si registri riceva a sua volta la lista completa dei file. I tempi possono essere così indicati:
Ovviamente il tempo è influenzato anche dalla dimensione dei dati da trasmettere, ma considerando un caso semplice con una lista di file non eccessivamente lunga, si può ritenere che la singola lista di file trasmessa dal server che si registra abbia dimensioni confrontabili con la lista completa, così che i due tempi sono approssimativamente uguali.
Per verificare invece la procedura automatica che controlla che i server registrati siano ancora attivi, effettuata dal coordinatore, o meglio da un processo del coordinatore, ho fatto diverse prove. Ho simulato la caduta sia di un server che in contemporanea di più server, compreso il caso della caduta di tutti i server registrati, ed in tutti i casi il coordinatore ha portato a termine correttamente l' aggiornamento della tabella degli altri server attivi, se ve ne rimanevano. Il processo di aggiornamento dei server, dopo aver appurato il guasto ad uno di essi, sarà uguale a quello di una modifica, e i tempi possono essere così espressi:
Nel caso che la procedura automatica, non abbia ancora rilevato la caduta di un server e un altro server richieda un file al server caduto, questi, accorgendosi della non attività del server, informerà il coordinatore, inviando il nome del server che non risponde. Anche in questo caso la procedura ha funzionato correttamente. I tempi possono essere analoghi a quelli di una modifica al file system, anche se il server non cancella automaticamente dalla propria lista il server che presuppone sia caduto perché questo avverrà in seguito alla comunicazione del coordinatore.
Infine, nel caso che si guasti il coordinatore, vengono a mancare gli aggiornamenti tra i vari server che riescono comunque a richiedere i file che rimangono disponibili e di cui ne avevano conoscenza prima del guasto al coordinatore. I vari server tentano ugualmente di notificare gli aggiornamenti al coordinatore, se questi ritorna attivo non avrà la tabella dei file e dei server aggiornata e quindi richiederà una registrazione al server che invia un' aggiornamento. Questo vale anche per i server che si sono attivati quando il coordinatore non era disponibile. Ho verificato il corretto funzionamento di tale semplice protocollo di recupero delle registrazioni, comunque, per garantire una più forte consistenza, bisognerebbe replicare il coordinatore.
Prove di trasferimento di file
I file possono essere trasferiti ad un client collegato ad uno qualsiasi dei server in due modalità: diretta, se il file si trova localmente, indiretta, se il file si trova su un altro server. Ovviamente il modo più veloce per ottenere un file è quello di trovarlo sul server a cui si è collegati. I tempi impiegati possono essere così indicati:
I tempi non possono essere predeterminati nel caso non si conoscano le disposizioni dei server e possono essere, altresì, influenzate dal traffico sulla rete. Il modo in cui si seleziona il server per richiedere un file remoto disponibile presso vari server avviene richiedendolo al server che si è registrato prima. Questo può risultare poco efficiente per diversi motivi: si sceglie sempre lo stesso server e non si verifica se il server è quello più vicino (esaminando, per esempio, il tempo per il PING). Ho effettuato delle prove per verificare i tempi per i trasferimenti dei file nei due casi, utilizzando per il test file di dimensioni variabili tra 50Kb e 50Mb, svolgendo quattro trasferimenti diversi per file e facendo una media dei risultati ottenuti. Queste medie sono riportate nella tabella seguente.
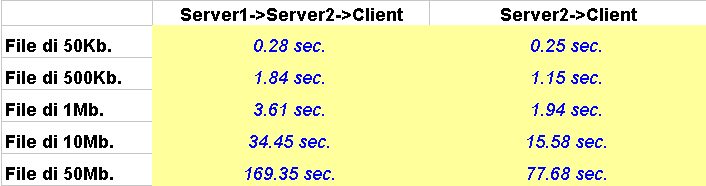
N.B. Il Client e il Server1 si trovano sulla stessa macchina, insieme al coordinatore. Il Server2 si trova su una seconda macchina.
Analizzando le singole colonne si nota che i tempi non sono sempre proporzionali alle dimensioni dei file e questo vale soprattutto se rapportato a file di piccole dimensioni. Ciò è spiegabile con l' overhead introdotto dal protocollo di trasferimento che influenza maggiormente i file più piccoli. Questo è vero tanto più per la prima colonna, dato che è effettuato un trasferimento anche tra server. Analizzando, quindi, le singole righe si vede che protocollo di coordinazione tra i server influenza il trasferimento indiretto (tra due server e un client), infatti ci si aspetterebbe sempre dei tempi circa doppi nella seconda colonna, mentre questo avviene solo per file di grandi dimensioni. I tempi di trasferimento sono proporzionali alla distanza percorsa dai file, che aumenta nel caso di trasferimento indiretto, ma il protocollo di coordinamento influenza i trasferimenti, anche se leggermente, che divengono poco convenienti nel caso di file di piccole dimensioni (ovviamente in percentuale rispetto al tempo totale). Ovviamente l' esempio non può essere che favorito dalla vicinanza dei server e i tempi non sono significativi se rapportati ad altre situazioni in cui la banda disponibile per le trasmissioni è meno ampia e più variabile, comunque danno indicazioni sull' andamento dei trasferimenti al variare delle dimensioni dei file e della località o meno del file stesso. Concludendo, si può affermare che le aspettative sui tempi di trasferimento sono state rispettate poiché risulta più costoso il trasferimento che coinvolge due server, ed anche rispetto al costo dell' implementazione del protocollo che influenza, solo trasferimenti di piccole dimensioni. Ho effettuato anche una prova di trasferimento di due file diversi dal medesimo server remoto contemporaneamente, per testare l' incidenza che può avere una banda di trasmissione ridotta e un potenziale sovraccarico del sistema. Vediamo in dettaglio: avevo in esecuzione come prima il Client1, il Server1 e il coordinatore sulla prima macchina, mentre sulla seconda il Server2 e il Client2. Sia il Client1 che il Client2 erano collegati al Server2 ed ho richiesto in contemporanea con il Client2 il file da 10Mb. e con il Client1 il file da 50Mb. utilizzati prima per il test, i file si trovavano presso il Server1 e quindi necessitavano di un doppio trasferimento. Il risultato è stato di tempi notevolmente superiori al caso precedente, 200% circa, sempre considerando che il Client2 era in una situazione particolarmente favorevole dato che era in esecuzione sulla stessa macchina su cui era in attivo il Server a cui era collegato. Quindi le prestazioni del sistema degradano molto rapidamente sfruttando il parallelismo e per poterlo sfruttare pienamente è necessario avere sia elaboratori più veloci che canali di trasmissione più veloci.