Università di BolognaCorso diRETI DI CALCOLATORIAnno Accademico 2000-2001 |
Il telefonino del WEB.
2 Marzo 2001
Quello che si vuole realizzare è un sistema software in grado di far comunicare tipo "chat" due o più persone mediante Internet, assicurando autenticazione e riservatezza dei dialoghi; l'applicazione deve tenere conto di host aventi indirizzo IP dinamico.
La semplicità d'uso è un requisito primario cui non si può rinunciare.
Le seguenti ipotesi saranno d'aiuto nello sviluppo dell'intero progetto:
Il sistema software da realizzare deve costituire l'endpoint di una chatline sicura; semplificando la cosa si può vederlo come nodo sia client, sia server di una versione crittografata e decentrata del noto applicativo ICQ (www.icq.com).
La struttura globale risulta una rete peer-to-peer, perché tutti i nodi hanno la medesima importanza, fungendo sia da client che da server a seconda delle esigenze del momento.
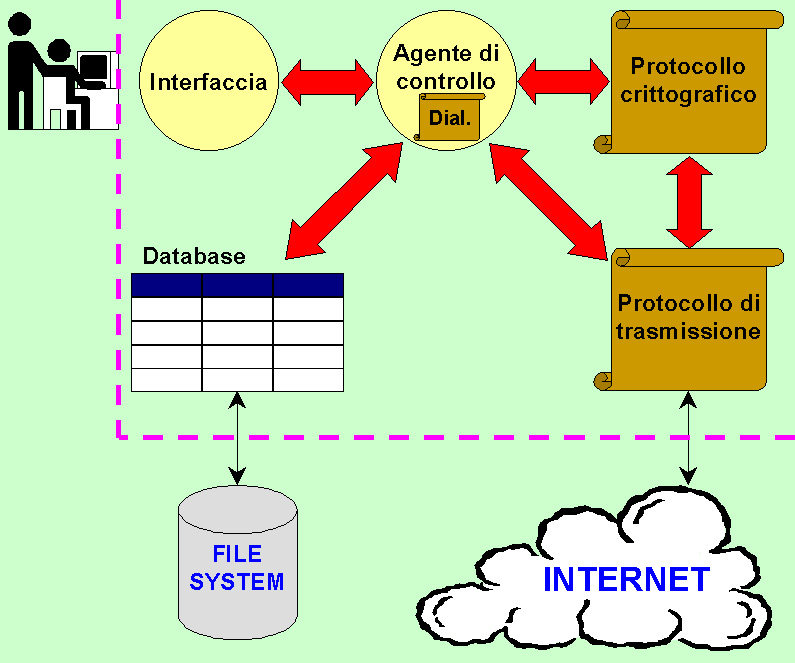
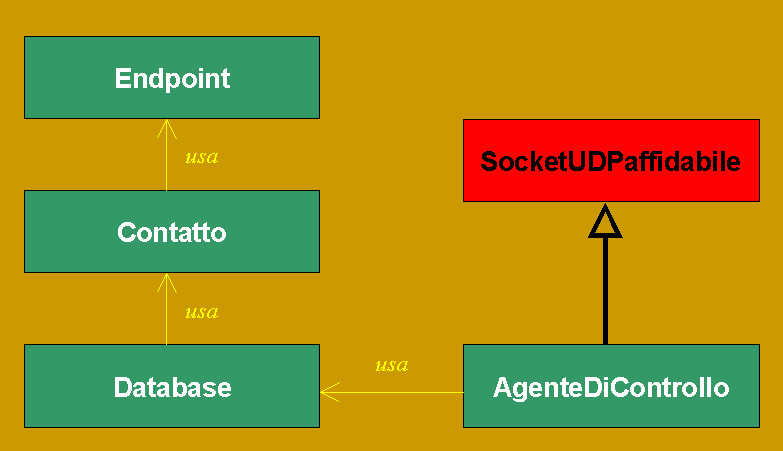
La fase di "Analisi del problema" suggerisce una prima schematizzazione dell'architettura software del sistema:
Indicando col termine "agente di controllo" l'entità software che coordina le attività degli oggetti che costituiscono l'applicativo, si può affermare che esso deve gestire interazioni sollecitate sia dall'utente per mezzo dell'interfaccia, sia dalla rete:
Ciascun utilizzatore è assimilabile ad un possibile destinatario di Contatto, dotato dei seguenti attributi:
I primi due attributi sono costanti e legati permanentemente alla persona in questione, mentre il terzo è modificabile a piacere, purché costituisca sempre un riferimento preciso tramite il quale raggiungere uno user. Non si confonda il termine "indirizzo" qui usato con "indirizzo IP", perché ora si sta parlando di riferimento, astratto ma preciso, ad una residenza di persone. Teoricamente è ammessa la possibilità che alla medesima locazione possano rispondere più utenti distinti, ma non contemporaneamente: quando un indirizzo è "in attività", cioè coinvolto in un dialogo, esso individua sempre una ed una sola persona.
Si introduce innanzitutto l'Abstract Data Type (ADT) Contatto:
| Le istanze dell'ADT sono puri valori oppure oggetti dotati di stato modificabile? | Sono oggetti dotati di stato modificabile. |
| L'ADT è atomico oppure strutturato? | È un tipo di dato strutturato, entro
cui si possono distinguere:
|
| Quali selettori e predicati è più opportuno introdurre? | Ci sono tre selettori:
ed un predicato:
|
| Quali modificatori inserire? | void aggiungi(Endpoint e): accoda e nella lista di Endpoint propria di ciascuna istanza. |
| L'insieme delle operazioni (primitive) definite è funzionalmente completo? | Sì, perché i tre selettori forniti consentono di avere accesso a tutti gli elementi costitutivi di un oggetto Contatto, ed il modificatore incrementa il contenuto dello stato interno dell'oggetto. |
| Quali operazioni dipendono dalla rappresentazione concreta del tipo? | Escludendo il predicato, le quattro operazioni sono delle primitive. |
| Qual è l'invariante dell'ADT? | Il nome
è sempre una sequenza composta da 1 a 32 caratteri,
ciascuno dei quali soddisfa il predicato di classe carLecitoNome(). La lista degli Endpoint non è mai vuota. |
| Quali elementi costituenti occorrono per formare un'istanza dell'ADT? | Un nome, una chiave crittografica ed un Endpoint sempre; in seguito si
possono aggiungere ulteriori Endpoint
grazie al modificatore. La costruzione di un oggetto fallisce se:
|
dove l'ADT Endpoint è così definito:
| Le istanze dell'ADT sono puri valori oppure oggetti dotati di stato modificabile? | Puri valori. |
| L'ADT è atomico oppure strutturato? | Strutturato, composto da un indirizzo IP ed un numero di porta TCP/UDP. |
| Quali selettori e predicati è più opportuno introdurre? | Solamente due selettori:
|
| Quali modificatori inserire? | Nessuno. |
| L'insieme delle operazioni (primitive) definite è funzionalmente completo? | Sì, perché si può accedere in sola lettura ai singoli membri costituenti l'oggetto. |
| Quali operazioni dipendono dalla rappresentazione concreta del tipo? | I due selettori sono delle primitive. |
| Qual è l'invariante dell'ADT? | 0 £ porta() £ 65535 º 0xFFFF. |
| Quali elementi costituenti occorrono per formare un'istanza dell'ADT? | All'atto della costruzione sono richiesti un indirizzo IP ed un numero di porta che rispetti l'invariante dell'ADT. Qualora ciò non avvenga si produce un fallimento. |
Andando per ordine, si valutino ora i singoli elementi mostrati nella prima figura uno per volta.
Il suo compito è astrarre le richieste sollecitate dall'utente e visualizzare le risposte prodotte dall'agente di controllo.
Visto il tipo di interazione con lo user, quest'entità funge da generatore di eventi asincroni, i quali saranno poi processati dall'agente.
Si conviene di poter mostrare all'utente:
L'interazione dell'entità in esame con l'agente di controllo è regolata dagli eventi originati dalla GUI di sistema, i quali portano con sé un indicatore del tipo di azione da compiere; essi rappresentano delle richieste di servizio che possono essere soddisfatte o meno per decisione dell'agente stesso.
Ciò costituisce un modello push delle informazioni, realizzato con azioni asincrone (= prive di risposta) non bloccanti: generata la richiesta sotto forma di evento, sarà l'agente di controllo a decidere se produrre o meno una risposta, aggiornando di conseguenza l'interfaccia mediante messaggi esplicativi o simili.
L'adozione di un database esterno allargherebbe in modo considerevole le dimensioni del programma, appesantendo oltremodo le risorse necessarie per la sua esecuzione.
In un'ottica UNIX si introduce quindi un file di testo, all'interno del quale l'utente ed il software possono registrare tutti i Contatti noti, secondo una precisa grammatica da definirsi; questa scelta assicura la persistenza delle informazioni fra attivazioni successive, assieme a modularità ed apertura del sistema.
Per elaborare il file ASCII sono sufficienti un lexer ed un parser che estraggono i Contatti uno dopo l'altro, dopodiché il database li memorizza in una sequenza ordinata in modo crescente sulla base dell'attributo nome, con lo scopo di velocizzare le operazioni di ricerca, di tipo "binaria" (o "dicotomica") per questioni di efficienza.
Ecco una possibile grammatica adatta alle esigenze manifestatesi:
scopo ::= nome / chiave @ endpoint
nome ::= lettera | cifra | _ | $ | lettera nome | cifra nome | _ nome | $ nome
lettera ::= a | b | … | y | z | A | B | … | Y | Z
chiave ::= numero | numero , chiave
endpoint ::= ip : porta | ip : porta @ endpoint
ip ::= numero . numero . numero . numero
porta ::= numero
numero ::= 0x esadecimale | intero
esadecimale ::= cifra-hex | cifra-hex esadecimale
intero ::= cifra | cifra intero
cifra ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
cifra-hex ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | A | B | C | D | E | F
che ulteriormente sintetizzata mediante la notazione BNF (Bakus-Naur Form) diviene:
scopo ::= nome / chiave @ endpoint
nome ::= ( a |…| z | A |…| Z | 0 |…| 9 | _ | $ ) { a |…| z | A |…| Z | 0 |…| 9 | _ | $ }31
chiave ::= numero { , numero }
endpoint ::= ip : numero { @ ip : numero }
ip ::= numero . numero . numero . numero
numero ::= 0 [ x cifra-hex { cifra-hex } | { cifra } ] | cifra-non-nulla { cifra }
cifra ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
cifra-non-nulla ::= 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
cifra-hex ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | A | B | C | D | E | F
Trattasi di grammatica di tipo 3 lineare a destra: un parser a discesa ricorsiva è in grado di interpretarla senza ambiguità. La semantica dei numeri è demandata al controllo esterno al lexer, cioé al parser, il quale deve sincerarsi che i numeri relativi ad un IP, ad esempio, rientrino nel range dei byte, e così via.
E' introdotto ora l'ADT Database che ne consegue:
| Le istanze dell'ADT sono puri valori oppure oggetti dotati di stato modificabile? | Sono oggetti aventi stato modificabile. |
| L'ADT è atomico oppure strutturato? | Un Database è un ente strutturato in cui si possono distinguere un primo, un secondo, un terzo, … elemento. |
| Quali selettori e predicati è più opportuno introdurre? | Si definiscono i selettori:
|
| Quali modificatori inserire? | void modifica(Contatto
c): cerca nell'archivio un elemento il cui
attributo nome eguagli il
medesimo campo di c: se
esiste allora ne altera il valore ponendolo uguale a c, altrimenti si aggiunge una
nuova entità posizionandola secondo un ordine crescente
in base al campo (chiave) nome. Questa realizzazione evita la presenza di due entità Contatto aventi lo stesso nominativo, centralizzando i possibili punti d'ingresso nell'archivio. |
| L'insieme delle operazioni (primitive) definite è funzionalmente completo? | Sì, perché:
Non sono previste azioni di cancellazione degli elementi, come specifica di definizione dell'ADT stesso. |
| Quali operazioni dipendono dalla rappresentazione concreta del tipo? | Le tre operazioni illustrate sono tutte delle primitive. |
| Qual è l'invariante dell'ADT? | Un oggetto Database
è sempre costituito da una sequenza ordinata, in senso
crescente, di zero o più elementi Contatto, i quali hanno
l'attributo nome unico
all'interno dell'istanza di ADT. La lunghezza della sequenza di record è non decrescente; seleziona() e tutti() non influiscono sul numero di elementi contenuti, mentre modifica() può accrescerlo di una unità al massimo per ogni invocazione. |
| Quali elementi costituenti occorrono per formare un'istanza dell'ADT? | Nessuno, in quanto è sufficiente creare un archivio inizialmente vuoto, dopodiché il modificatore illustrato costituirà il mezzo per introdurre un qualsivoglia numero di Contatto. |
Dovendo trattare problematiche di autenticazione, integrità e riservatezza, la crittografia a chiave pubblica è uno strumento idoneo ad assolvere a tutti questi compiti, tantopiù che oggigiorno la sua adozione nelle strutture informatiche rivolte al pubblico è in continua crescita.
Reperire strumenti che supportano queste tecnologie è certamente facile, quindi perché non approfittarne? perché rinunciarvi dovendo progettare complessi protocolli a sfida o simili?
L'unico aspetto negativo è il carico computazionale richiesto dalla crittografia in generale, ma poiché l'applicazione è di tipo elastica-interattiva il problema non si pone.
Come prima cosa è necessario attribuire una coppia di chiavi a ciascun utente; l'algoritmo universalmente usato è RSA (Rivest-Shamir-Adleman), mentre la dimensione delle chiavi la si sceglie in base alle esigenze ed al livello di sicurezza desiderato: 1024 bit sono più che sufficienti oggigiorno.
Trattandosi di cifratura a blocchi occorre suddividere il plaintext in unità di dimensioni fisse opportune, scegliendo anche una regola di padding; gli autori di RSA suggeriscono PKCS#7 per questo secondo problema (si veda www.rsa.com a tal proposito), mentre per la frammentazione dei messaggi conviene lavorare in ECB (Electronic Code Book), perché tutte le alternative ad esso obbligano a condividere ulteriori informazioni all'atto della decifrazione.
Va rilevato che il modo ECB tratta ciascun blocco indipendentemente dagli altri, dunque un ipotetico intruso potrebbe facilmente distinguere ogni frammento all'interno di un lungo messaggio; in seguito a ciò si deve fornire un check d'integrità complessivo del pacchetto informativo scambiato tramite la rete.
La scelta più logica per garantire sia l'integrità del messaggio, sia l'autenticazione del mittente è costituita dalla firma digitale: le chiavi asimmetriche adottate per RSA fanno all'uopo, garantendo la riservatezza del dialogo cifrando la sequenza [plaintext + firma digitale] con la chiave pubblica del ricevente. A tal punto solo il reale destinatario sarà in grado di risalire al vero contenuto della "busta" pervenutagli, verificandone sia l'integrità che la provenienza grazie alla firma digitale inclusa in essa.
Come alternativa si possono adottare due cifrature consecutive mediante RSA: prima impiegando la chiave privata del mittente, poi quella pubblica del destinatario; il livello di sicurezza offerto da questa soluzione è maggiore di quello precedente, in virtù del fatto che la cardinalità dello spazio delle firme digitali di un messaggio è minore della cardinalità dello spazio dei messaggi stessi. Occorre evidenziare però che due passaggi di RSA richiedono molta elaborazione per il processore, quindi non sempre sono convenienti in termini di tempo.
Entrambi i metodi illustrati possiedono un vizio di fondo comune: non sono utilizzabili in ambiti di gruppo, nel senso che è impensabile creare un messaggio specifico per ciascun destinatario quando il numero di partecipanti può essere di una o più decine, ad esempio.
Una risposta a questo problema consiste nella chiave segreta (simmetrica) di sessione, la quale permette di far fronte a molteplici aspetti pratici, perché computazionalmente la crittografia simmetrica è molto più leggera, inoltre la generazione di una chiave dedicata per ciascun dialogo rende più ardua la vita di un intruso che voglia intercettare i dialoghi. Modificare la chiave di sessione ad ogni dialogo consente di ottenere differenti messaggi a livello di rete, anche quando il loro contenuto non cambia.
Resta inteso che lo scambio iniziale della chiave di sessione fra i partecipanti avviene secondo lo schema iniziale, facendo riferimento alla firma digitale seguita da cifratura mediante RSA.
Riassumendo:
PROTOCOLLO CRITTOGRAFICO |
VANTAGGI |
SVANTAGGI |
| Singola (de)cifratura a chiave asimmetrica con firma digitale |
|
|
| Doppia (de)cifratura con chiavi asimmetriche |
|
|
| Chiave segreta (simmetrica) di sessione con firma digitale |
|
|
La terza soluzione proposta è interessante soprattutto per la sua versatilità, in quanto adottabile sia in contesti di coppia che di gruppo. Con un solo protocollo crittografico si fa fronte ad entrambe le tipologie di conversazioni; implementativamente è un grosso sollievo! Introduce meno codice, quindi un minor numero di possibili errori progettuali, implementativi o di codifica; ne beneficia anche la semplicità dell'intero apparato software.
L'algoritmo crittografico a chiave segreta può essere IDEA, Triple DES, Blowfish, RC4 o simili: in questa sede si opta per IDEA, perché di elevata robustezza ed universalmente noto in ambito informatico, perciò facilmente realizzabile. Sono comuni i tool software che lo includono, in qualsiasi linguaggio. Da sottolineare anche le buone prestazioni di IDEA in termini di velocità.
Osservazioni:
Avendo dialoghi distribuiti ad intervalli impredicibili nel tempo l'adozione di un protocollo connection-oriented come TCP è sinonimo di "spreco", perché impegna risorse di rete anche quando non c'è scambio di messaggio fra gli utenti. La sua adozione risulterebbe poi sovrabbondante durante conversazioni di gruppo, con un canale bidirezionale per ciascuna coppia di interlocutori: n partecipanti richiederebbero n·(n-1):2 stream full-duplex, µ n2!
Scartando TCP resta a disposizione solo UDP: essendo connectionless la cosa è soddisfacente per quanto concerne l'impegno di risorse, sia come traffico di rete, sia come elaborazione locale richiesta nel trattamento dei singoli datagrammi.
La caratteristica unreliable di UDP obbliga a cercare una soluzione per informare il mittente dell'avvenuta ricezione di quanto inviato: semplicità ed efficienza orientano immediatamente verso Automatic Repeat reQuest (ARQ). Valori ammissibili di timeout sono 5÷10 secondi, mentre 3÷5 ripetizioni per ciascun datagramma sul lato del mittente costituiscono un'insistenza non esagerata ma sufficientemente accorta. Si noti come l'elaborazione crittografica dell'applicativo, caricando il processore, possa far propendere per timeout di 8÷10 secondi piuttosto che 5, a meno di usare concorrenza ed eventi asincroni all'interno del software, disaccoppiando la computazione vera e propria dalla gestione della rete.
La concorrenza in termini di multithreading sarebbe la soluzione più elegante, però la preemption non assicurata dallo scheduler della JVM e la semplicità richiesta all'applicazione consigliano una metodologia a polling: periodicamente si interroga l'interfaccia di rete, dandole precedenza qualora essa segnali attività UDP, per poi riprendere solo in seguito l'elaborazione sospesa.
In questo modo l'applicativo possiede un unico flusso di esecuzione, il quale saltuariamente si occupa di testare gli apparati di rete per concedere loro, eventualmente, la capacità computazionale necessaria per trattare datagrammi UDP.
Adoperando opportunamente gli eventi asincroni generati dall'interfaccia è possibile creare un main-loop dedicato alla porta UDP di ascolto, il quale viene interrotto se e solo se lo user richiede operazioni: qualora queste risultino prolungate nel tempo è possibile adottare anche il polling descritto, altrimenti l'asincronia offerta dalla GUI è più che sufficiente.
È necessaria la frammentazione/ricomposizione di messaggi a livello applicativo in più datagrammi UDP?
Ecco una stima basata sui seguenti dati sperimentali:
dunque a fronte di un ipotetico messaggio a livello di applicazione, composto da 1000 byte, si ottiene un datagramma di:
128 / 112 * (1000 + 128) @ 1290 byte (+ header UDP di 8 byte)
ai quali si possono aggiungere alcuni byte di padding per la cifratura a blocchi, oltre ad un eventuale sequence number al di sopra di UDP: 1400 byte è una stima altamente pessimistica, considerando che parte dell'overhead introdotto è costante con la lunghezza del plaintext.
Il campo dati di un datagramma UDP è composto al massimo 65527 byte (0xFFFF - 8 di header UDP) => non è richiesta frammentazione/ricomposizione per messaggi applicativi fino a 56 Kbyte circa; tale valore discende dall'applicazione inversa della succitata formula.
L'interfaccia seguente astrae le azioni che si possono richiedere:
public interface ITrasmissione {
int invia(DatagramPacket[] d);
int disponibili();
void ricevi(DatagramPacket *d);
void chiudi();
}
dove:
È necessario relazionare il protocollo di trasmissione con quello crittografico? In caso affermativo, qual è il legame fra i due?
Si considerino gli ACK: in intruso esterno, dotato di sniffer di rete, può appropriarsi dei datagrammi in transito, producendo un acknowledge per il mittente anche quando il vero destinatario non viene raggiunto dalle informazioni a lui indirizzate => la crittografia deve proteggere l'ACK stesso.
Si può cifrare il sequence number del messaggio da spedire, dopodiché sarà solo il vero destinatario a poterne ricavare il valore numerico per produrre la conferma associata. Qualora i sequence number siano casuali fra messaggi successivi non è necessario applicare la cifratura dell'ACK: se l'intruso legge il numero della conferma non può utilizzarlo a suo favore, perché i prossimi datagrammi avranno certamente numeri diversi, non correlati (o quasi...) a quello osservato al momento.
Questa gestione degli acknowledge incarna un "protocollo a sfida" fra il mittente ed il ricevente.
La mancata cifratura dei messaggi di conferma alleggerisce anche l'elaborazione matematica richiesta al processore!
Questa stretta correlazione fra la parte crittografica ed il protocollo di trasmissione non permette di asserire che si viene a costituire un vero e proprio livello di presentazione, in quanto esso collabora attivamente con la sottostante infrastruttura di trasmissione per realizzarne le funzionalità. I due livelli non sono autonomi presi singolarmente.
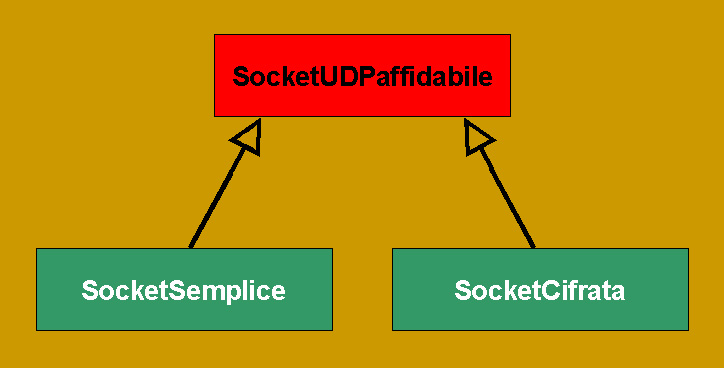
La modularità dell'architettura spinge ad incapsulare entro una classe base SocketUDPaffidabile il protocollo di trasmissione, lasciando che sia una sua specializzazione a gestire materialmente i numeri di sequenza. In questo modo, grazie all'ereditarietà, è possibile riutilizzare il pattern di socket UDP reliable in ambiti non crittografati, ad esempio, oppure specializzando la classe per esigenze particolari:
L'adozione di un socket UDP per scambiare informazioni con più endpoint remoti obbliga a conservare una "storia" riferita a ciascun mittente remoto: il numero di sequenza dell'ultimo messaggio ricevuto. Questo serve per non replicare più volte lo stesso segmento ricevuto passandolo al livello di applicazione; è la soluzione adottata da TCP.
Ecco i passi elementari da effettuare all'atto di una ricezione:
[lettura del datagramma UDP dallo stack TCP/IP];
seq_num := [numero di sequenza estratto dal datagramma];
IF (seq_num > last_seq_num ricevuto dallo stesso endpoint) THEN BEGIN
[per l'endpoint di provenienza del datagramma porre last_seq_num := seq_num];
[consegna del datagramma al livello OSI superiore];
END;
ELSE
[scarto del datagramma, perché già ricevuto in precedenza];
Più rigorosamente, l'ADT SocketUDPaffidabile è così definito:
| Le istanze dell'ADT sono puri valori oppure oggetti dotati di stato modificabile? | Oggetti dotati di stato modificabile. |
| L'ADT è atomico oppure strutturato? | L'ADT è strutturato al suo interno, ma
questo non deve apparire osservandolo dall'esterno; si
possono individuare:
|
| Quali selettori e predicati è più opportuno introdurre? | Si introduce la seguente proprietà:
|
| Quali modificatori inserire? |
|
| L'insieme delle operazioni (primitive) definite è funzionalmente completo? | Sì. |
| Quali operazioni dipendono dalla rappresentazione concreta del tipo? | Le quattro operazioni illustrate sono delle primitive. |
| Qual è l'invariante dell'ADT? |
|
| Quali elementi costituenti occorrono per formare un'istanza dell'ADT? | Il numero della porta UDP alla quale legare il socket sock, eventualmente, oppure lasciare che sia il S.O. sottostante ad occuparsene, prendendone una disponibile a runtime. |
L'Abstract Data Type appena illustrato prevede anche due operazioni che devono essere obbligatoriamente implementate dalle classi derivate:
In questo modo è possibile specializzare SocketUDPaffidabile riscrivendo solo i due metodi d'istanza sovrastanti, i quali diventano così per il caso in esame:
int inserisciSeqNum(DatagramPacket *d) {
seq_num += [numero casuale intero strettamente positivo];
[inserisci seq_num nel campo dati di d];
md5rsa.firma(d, chiave_privata);
[inserisci la firma digitale appena calcolata nel campo dati di d];
IF (il destinatario di d è un interlocutore) THEN
idea.cifra(d, chiave_di_sessione);
ELSE
rsa.cifra(d, [chiave pubblica del destinatario]);
RETURN seq_num;
}
int estraiSeqNum(DatagramPacket *d) {
IF (il mittente di d è un interlocutore) THEN
idea.decifra(d, chiave_di_sessione);
ELSE
rsa.decifra(d, chiave_privata);
[estrai la firma da d, verificandone la bontà con la chiave pubblica del mittente];
RETURN [sequence number estratto da d];
}
Nel pseudo-codice illustrato la variabile seq_num è un campo d'istanza interno all'ADT, inteso come un contatore intero. È una sorta di accumulatore che viene incrementato di una quantità random ad ogni nuovo datagramma da spedire in rete.
Quali messaggi devono scambiarsi i singoli nodi della rete per chattare fra loro?
Ricalcando alcune caratteristiche di TCP, i datagrammi si possono classificare in cinque tipologie distinte:
Ecco un esempio nel caso in cui lo user A voglia comunicare con B, il quale sta già colloquiando con altri:
A |
¾¾¾¾¾ SYN ¾¾¾¾® ¬¾¾¾¾ OK ¾¾¾¾¾ |
B |
| ¾¾¾ ADD ¾¾® ... ¾¾¾ ADD ¾¾® |
||
¾¾¾¾¾TEXT¾¾¾¾® ¬¾¾¾¾TEXT¾¾¾¾¾ ... ¬¾¾¾¾ FIN ¾¾¾¾¾ |
Ciascuna freccia rappresenta un datagramma UDP affidabile.
Fra il SYN ed il corrispondente OK non ci sono vincoli di tempo: questo consente a B di riflettere prima di accettare la richiesta pervenutagli da parte di A.
Una richiesta è tacitamente negata sino a quando non viene espressamente confermata dall'OK.
Nel caso in cui B fosse già a colloquio con altri utenti il messaggio di OK informa A di essere in contatto non solo con B, ma anche con altri individui; in questi frangenti A può allargare il proprio giro di conoscenze, eventualmente aggiungendo i nuovi "amici" al proprio database interno che funge da rubrica.
E' compito di B informare i suoi interlocutori di aver concesso ad A il permesso di intervenire nel colloquio in atto, inviando un datagramma di ADD recante con sé il nickname, la chiave pubblica e l'endpoint di A.
Come realizzare il groupcast per i messaggi di tipo TEXT?
Una politica fair incarica colui che interviene nella discussione di recapitare le proprie asserzioni a tutti gli interessati, ossia a tutti i componenti del gruppo di discussione. Questa è la soluzione più semplice.
Quest'entità incapsula il coordinamento complessivo di tutto il sistema. Dal momento che il legame con il protocollo crittografico è molto forte (per funzionare quest'ultimo necessita delle due chiavi RSA dell'utilizzatore, della rubrica con le chiavi pubbliche, della lista degli interlocutori e della chiave di sessione), la prima conseguenza è che l'agente deve inglobare al suo interno il protocollo crittografico stesso. Si ricordi però che questi specializza SocketUDPaffidabile, quindi la situazione è presto schematizzata:
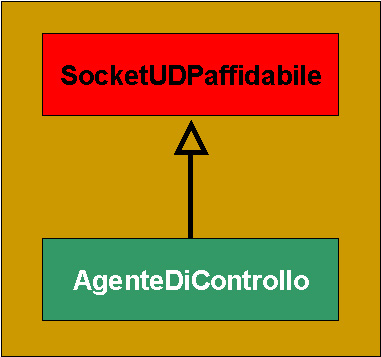
SocketUDPaffidabile contiene il protocollo di trasmissione, mentre quelli crittografico e di dialogo sono inglobati entro l'agente di controllo.
Dal punto di vista algoritmico, l'agente esamina sia le richieste provenienti dall'utente tramite l'interfaccia, sia i datagrammi ricevuti dalla rete tramite SocketUDPaffidabile, formulando le eventuali risposte ed assicurandosi che il protocollo di dialogo sia rispettato.
Nella fase di avvio egli deve:
In fase di terminazione del programma occorre:
Il Class Diagram complessivo è così composto:
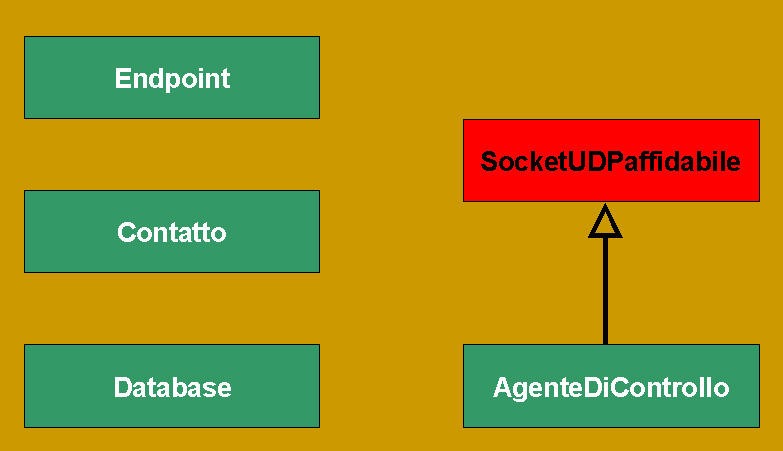
mentre il Collaboration Diagram è il seguente:
E' già stata fissata Java 1.2 come piattaforma di sviluppo; il supporto crittografico è realizzato dal package Cryptix (www.cryptix.org) nella sua attualmente più recente versione, la 3.2.0, in quanto Open Source e sufficientemente completo.
Tutto il codice che riguarda il progetto è racchiuso dentro il package chat.
Procedendo secondo l'ordine seguito in fase di progetto si introduce una public class Endpoint, la quale è perfettamente definita dall'omonimo ADT; l'unica aggiunta da apportare è la generazione di una IllegalArgumentException in fase di costruzione, qualora il numero di porta specificato come parametro non rientri nell'intervallo chiuso [0,65535].
Essendo in ambiente Java, può risultare utile ridefinire il metodo public boolean equals(Object obj) per effettuare il confronto fra due istanze di Endpoint, restituendo true se e solo se obj != null ed i campi private dell'istanza e di obj sono uguali fra loro.
E' semplice anche implementare l'Abstract Data Type Contatto:
if (!dove.contains(e))
dove.add(e);
L'interfaccia dell'applicativo, in un'ottica di semplicità estrema, può essere mantenuta di tipo "testuale", evitando di ricorrere ai package java.awt e java.swing che obbligano all'adozione di una GUI a runtime. Questo però solleva un problema: l'asincronia massima offerta dai canali standard di I/O è quella associata al polling dei medesimi, metodo che, secondo prove sperimentali effettuate, rende inutilizzabile la console, perché rallenta esageratamente la visualizzazione dei caratteri inseriti dall'utente, nascondendoli del tutto in certe situazioni.
Una possibile soluzione per non rinunciare alla modalità "testuale" è spezzare in due parti l'applicativo: un primo programma legge perennemente da System.in inviando i dati su un file, mentre un secondo prende le linee di testo dal supporto di massa precedente per elaborarle e produrre le eventuali risposte su System.out. In sintesi, la prima applicazione gestisce la propria finestra come canale di input della chat, mentre la seconda realizza lo schermo di visualizzazione del dialogo:
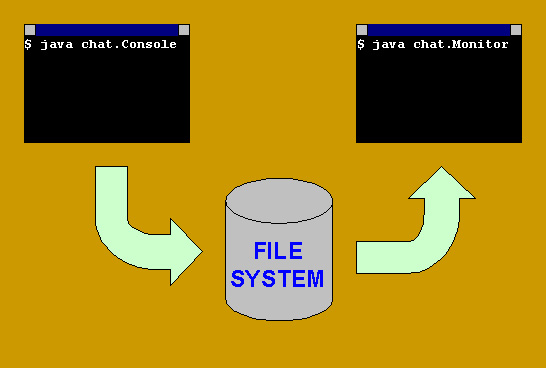
Visti i problemi causati dal polling di System.in, si ritiene opportuno maneggiare SocketUDPaffidabile da parte del canale di uscita della chat.
Questa suddivisione obbliga a definire un protocollo secondo il quale le due parti comunicano, introducendo semplici linee di comando per lo user finale:
Per comodità, il file di scambio delle informazioni viene gestito a linee di testo: ogni linea definisce un comando.
Si indica con Console la public class che realizza l'interfaccia di ingresso del sistema, mentre public class Monitor identifica la parte di output. Esse saranno descritte solo al termine della fase d'implementazione, perché maneggiano oggetti non ancora implementati.
Proseguendo, l'ADT Database può essere implementato come wrapper attorno ad un java.util.SortedSet, il quale permette una gestione ad albero binario di un insieme di java.lang.Object, ordinandoli a piacere secondo una funzione di confronto da specificare. Quel che ne risulta è:
public class Database {
private SortedSet s = Collections.synchronizedSortedSet(new TreeSet(new ComparaContatto()));
public Database() {}
...
dove ComparaContatto è una classe avente un solo metodo che rispetta le specifiche di java.util.Comparator, relazionando fra loro due istanze di tipo Contatto sulla base dell'attributo nome. Essa si occupa dell'ordinamento fra gli oggetti contenuti nell'albero binario costituito dal SortedSet s.
Il completamento di Database non presenta difficoltà, perché l'interfaccia java.util.SortedSet presenta già le funzioni elencate nella specifica dell'ADT in esame. L'unica particolarità consiste nell'ammissione di "duplicati" da parte di un SortedSet: questo può essere facilmente evitato verificando la presenza di un certo individuo entro l'albero prima di modificarlo:
public synchronized void modifica(Contatto c) {
s.remove(c); // Prima si elimina l'eventuale record già presente...
s.add(c); // ...poi si reinserisce, evitando duplicati sulla base del nome.
}
Rispetto a quanto definito in fase di progetto, è conveniente incorporare entro Database anche un metodo che cancelli un record sulla base del nome: in questa maniera un'istanza della medesima classe può essere adottata per individuare anche il gruppo di discussione, soggetto ad ingressi ed uscite dei partecipanti.
Il lexer ed il parser per la manipolazione del file ASCII usato per assicurare la permanenza non presentano difficoltà: il corso di "Linguaggi e traduttori" la fa da maestro, consigliando un lexer che specializzi java.io.streamTokenizer per il corretto trattamento dei numeri interi (espressi anche in notazione esadecimale), mentre il parser realizza una classe a se stante, inglobando un'istanza privata di lexer tramite la quale agire sullo stream di char passato come parametro in fase di costruzione:
class Lexer extends StreamTokenizer {
Lexer(Reader r) {
super(r);
resetSyntax();
wordChars('a', 'z');
wordChars('A', 'Z');
wordChars('0', '9');
wordChars('_', '_');
wordChars('$', '$');
commentChar(';'); // Carattere di inizio dei commenti sino a fine linea
slashStarComments(true); // Riconosciuti i commenti con sintassi C...
slashSlashComments(true); // ...e C++
whitespaceChars('\t', '\t'); // I separatori fra le parole
whitespaceChars('\r', '\r');
whitespaceChars(' ', ' ');
eolIsSignificant(false); // 'End Of Line' come un blank
ordinaryChar('/'); // 5 tipi di token specifici
ordinaryChar(',');
ordinaryChar('@');
ordinaryChar(':');
ordinaryChar('.');
}
public int nextToken() throws IOException { ...
class Parser {
private Lexer lexer;
Parser(Reader stream) { lexer = new Lexer(stream); }
...
In caso di errori sintattici/semantici è sufficiente generare una RuntimeException corredata di un messaggio esplicativo, il quale chiarisca il perché dell'eccezione. Questo causa la terminazione del programma, ma ciò non costituisce un problema visti gli obiettivi iniziali.
L'adozione delle due classi Lexer e Parser consente di aggiungere un ulteriore costruttore a Database, agevolandone l'uso pratico:
public Database(String nome_file) throws FileNotFoundException, IOException {
InputStreamReader is = new InputStreamReader(new FileInputStream(nome_file));
try {
Parser p = new Parser(is);
p.avanzaToken();
while (p.tokenCorrente().length() > 0)
modifica(p.prossimo());
} finally { is.close(); }
}
Il protocollo di trasmissione resta individuato dall'ADT SocketUDPaffidabile, rispecchiato da un'omonima classe Java di tipo abstract dotata di:
Gli acknowledge adottati possono essere rappresentati da numeri int, sufficientemente capaci (32 bit) da evitare riavvolgimenti causa overflow per quest'applicativo software.
Un cenno in merito a sock: le DatagramSocket di Java non consentono la gestione a polling, quindi la cosa più simile che si possa realizzare è rendere sock "il meno bloccante possibile", invocando:
sock.setSoTimeout(1);
in fase di costruzione. Questo permette di intercettare la mancanza di datagrammi disponibili alla lettura mediante java.io.InterruptedIOException, restando bloccati sul socket al massimo per 1 millisecondo (forse…).
Gli algoritmi in pseudo-linguaggio illustrati in fase di progetto sono sufficientemente dettagliati da essere realizzati senza inconvenienti in Java. L'unico dettaglio riguarda i record contenuti nell'history delle conversazioni transitate attraverso sock:
class HistoryEntry {
java.net.InetAddress IP;
int port;
int last_seq_num;
HistoryEntry(java.net.InetAddress IP, int port, int last_seq_num) {
this.IP = IP;
this.port = port;
this.last_seq_num = last_seq_num;
}
}
risolve il problema, essendo visibile solo all'interno del package chat. Le istanze di questa classe saranno immagazzinate nel Vector history interno ad ogni oggetto SocketUDPaffidabile. Ereditando da quest'ultima classe si viene a costruire ciò che in fase di progetto è indicato col nome di "agente di controllo", qui implementato dalla classe Monitor già introdotta.
Per semplificare l'adozione della crittografia e della firma digitale da parte di un applicativo Java, è utile realizzare due semplici classi che permettono di applicare le suddette operazioni secondo uno stile funzionale: gli oggetti descritti dalla JCA sono atti a trattare un solo flusso informativo, perché al loro interno memorizzano tutti i dati, senza dare modo di azzerare questo buffer privato.
Per la firma digitale si può ricorrere a:
public class Firma {
// L'algoritmo del java.security.Signature da impiegare.
private String algoritmo;
public Firma(String algoritmo) throws NoSuchAlgorithmException {
Signature.getInstance(this.algoritmo = algoritmo);
}
completandola con due funzioni di creazione della firma e di verifica della medesima, ove si crea un nuovo java.security.Signature per ciascuna invocazione:
public byte[] firma(byte[] messaggio, int offset, int lun, PrivateKey chiave) {
try {
Signature sign = Signature.getInstance(algoritmo);
sign.initSign(chiave);
sign.update(messaggio, offset, lun);
return sign.sign();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
throw new RuntimeException("Ora l'algoritmo non è più supportato?");
}
catch (InvalidKeyException e) { e.printStackTrace(); }
catch (SignatureException e) { e.printStackTrace(); }
return null;
}
public boolean firmaOk(byte[] messaggio, int offset, int lun, byte[] firma, PublicKey chiave) {
try {
Signature sign = Signature.getInstance(algoritmo);
sign.initVerify(chiave);
sign.update(messaggio, offset, lun);
return sign.verify(firma);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
throw new RuntimeException("Ora l'algoritmo non è più supportato?");
}
catch (InvalidKeyException e) { e.printStackTrace(); }
catch (SignatureException e) { e.printStackTrace(); }
return false;
}
Il problema di risolvere è il medesimo nel caso della crittografia, quindi la soluzione non si discosta troppo da quella appena illustrata:
public class Crittografia {
// L'algoritmo da usare nelle operazioni di cifratura e decifratura
private String algoritmo;
public Crittografia(String algoritmo) throws NoSuchAlgorithmException {
Cipher.getInstance(this.algoritmo = algoritmo);
}
public byte[] cifra(byte[] dati, int offset, int lun, Key chiave) throws KeyException {
try {
Cipher c = Cipher.getInstance(algoritmo);
c.initEncrypt(chiave);
return c.doFinal(dati, offset, lun);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
throw new RuntimeException("Ora l'algoritmo non è più supportato?");
}
}
public byte[] decifra(byte[] dati, int offset, int lun, Key chiave) throws KeyException {
try {
Cipher c = Cipher.getInstance(algoritmo);
c.initDecrypt(chiave);
return c.doFinal(dati, offset, lun);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
throw new RuntimeException("Ora l'algoritmo non è più supportato?");
}
}
Prima di passare al vero cuore del sistema si implementano i messaggi scambiati dall'applicativo.
Una public class MessaggioBase rappresenta un generico scambio di informazioni fra un mittente ed un destinatario, essendo composta da:
I tre campi vengono inizializzati in fase di costruzione da altrettanti parametri, mentre possono essere acceduti in lettura da tre omonimi selettori d'istanza public.
Dato che un messaggio è spesso destinato ad uno stream, si ricorre alla serializzazione di Java per assolvere a tale compito:
public class MessaggioBase implements java.io.Serializable {
La classe appena descritta può essere specializzata per ottenere un messaggio più conforme alle esigenze del problema, interpretando l'array di byte che_cosa secondo un preciso formato:
Dunque:
public class Messaggio extends MessaggioBase {
La "formattazione" del messaggio viene gestita dal costruttore:
public Messaggio(String da, String a, int seq_num, byte tipo, byte[] testo, byte[] firma) {
super(da, a, new byte[4 + 4 + 1 + (testo==null?0:testo.length) + (firma==null?0:firma.length)]);
scriviSeqNum(seq_num); // Metodo d'istanza per scrivere il sequence number
Utili.intToArray(firma == null ? 0 : firma.length, che_cosa, 4); // Serializzazione di un int
che_cosa[8] = tipo;
if (testo != null)
System.arraycopy(testo, 0, che_cosa, 4 + 4 + 1, testo.length);
if (firma != null)
System.arraycopy(firma, 0, che_cosa, che_cosa.length - firma.length, firma.length);
}
mentre opportuni metodi d'istanza fungono da selettori per accedere in lettura o scrittura ai singoli campi.
Questo "compattamento" di singoli campi entro un unico vettore di byte consente una facile cifratura dell'intero array, proteggendo tutti gli elementi che lo compongono da sguardi indiscreti.
Rimangono da definire Console e Monitor.
La prima classe è semplicissima, in quanto composta dal solo main:
public class Console {
public static void main(String[] args) {
...
}
}
All'interno di tale metodo essa deve:
BufferedReader stdin = new BufferedReader(new InputStreamReader(System.in));
File f = new File(Monitor.FILE_SWAP); // Monitor.FILE_SWAP è il nome del file
if (f.exists() && !f.delete()) {
System.out.println("Impossibile cancellare " + f.getName() + ".");
System.exit(1);
}
FileWriter swap = new FileWriter(f);
Database db = new Database(Monitor.FILE_DATABASE);
String prompt = "";
do {
System.out.print("Inserisci il nickname da usare: ");
try { prompt = stdin.readLine().trim(); } catch (IOException e) {}
} while (prompt.length() == 0);
per poi scriverlo come prima cosa nel file di scambio:
swap.write(prompt + "\n"); // Scrittura del proprio nickname
swap.flush();
Da notare che Console non possiede uno stato interno inerente la chat in corso, perché questo viene lasciato a Monitor; la classe appena descritta incarna un cosiddetto "terminale stupido", il quale si limita a fornire direttamente le risposte più semplici (la lettura della rubrica), demandando invece a Monitor le richieste che non è in grado di interpretare.
Per quanto concerne il Monitor si può affermare che esso realizza l'agente di controllo, venendo a costituire il lato "server" del sistema software.
Come stabilito, esso eredita da SocketUDPaffidabile, implementando i due metodi abstract che gestiscono i DatagramPacket provenienti e/o destinati alla rete; realizza inoltre il protocollo di dialogo, avvalendosi delle costanti che, per comodità, possono essere inglobate entro un'unica classe:
public class Protocollo {
public static final byte SYN = (byte) 0x80;
public static final byte OK = (byte) 0x40;
public static final byte ADD = (byte) 0x20;
public static final byte TEXT = (byte) 0x10;
public static final byte FIN = (byte) 0x08;
}
La situazione è dunque la seguente:
public class Monitor extends SocketUDPaffidabile {
...
Si vuole incapsulare entro tale classe un gestore di chat, in modo da permettere esecuzioni di più istanze su una medesima stazione, associando ciascuna ad una porta UDP differente; di per sé questa caratteristica sembra superflua, ma non si vede il motivo per cui precluderla a priori, dato il minimo sforzo richiesto.
Entro Monitor si trova il metodo main, il quale si obbliga di avviare un'istanza della classe legandola, eventualmente, alla porta UDP specificata come primo parametro sulla linea di comando:
public static void main(String[] args) {
Security.addProvider(new Cryptix()); // Installa dinamicamente Cryptix
try {
switch (args.length) {
case 0: new Monitor().esegui();
break;
case 1: new Monitor(Integer.parseInt(args[0])).esegui();
break;
default: System.out.println("Sintassi d'uso: java chat.Monitor [porta UDP]");
}
} catch (SocketException e) {
e.printStackTrace();
}
}
La prosecuzione del lavoro è deputata alla classe in esame, la quale contiene molteplici variabili di istanza di tipo private che vengono inizializzate in fase di costruzione, dovendo:
swap = new BufferedReader(new FileReader("swap.txt"));
rubrica = new Database("Database.txt");
nickname = swap.readLine();
c_pubblica = new RawRSAPublicKey(new FileInputStream(nickname + ".pub"));
c_privata = new RawRSAPrivateKey(new FileInputStream(nickname + ".pri"));
md5rsa = new Firma("MD5/RSA");
rsa = new Crittografia("RSA/ECB/PKCS#7");
idea = new Crittografia("IDEA/ECB/PKCS#5");
generatore_c = KeyGenerator.getInstance("IDEA");
generatore_c.initialize(entropia);
dove entropia è un'istanza di java.security.SecureRandom;
rubrica.cancella(nickname);
Qualche messaggio diagnostico risulta utile per verificare il corretto funzionamento dell'applicativo.
I due metodi seguenti implementano concretamente quanto richiesto dalla super-classe:
protected int inserisciSeqNum(DatagramPacket d) {
Messaggio m = messaggioFromDatagram(d);
seq_num += entropia.nextInt(0xffff) + 1; // Il contatore pei sequence number
if (ACCLUDI_FIRMA_DIGITALE)
m = new Messaggio(m.daChi(), m.aChi(), seq_num, m.tipo(), m.testo(), md5rsa.firma(m.testo(), c_privata));
else
m.scriviSeqNum(seq_num);
if (ADOTTA_CRITTOGRAFIA)
try {
m = new Messaggio(m.daChi(), m.aChi(),
interlocutori.contiene(m.aChi()) ? idea.cifra(m.cheCosa(), c_sessione)
: rsa.cifra(m.cheCosa(), rubrica.seleziona(m.aChi()).chiave()));
} catch (KeyException e) {
e.printStackTrace();
}
messaggioToDatagram(m, d);
return seq_num;
}
protected int estraiSeqNum(DatagramPacket d) {
Messaggio m = messaggioFromDatagram(d);
if (ADOTTA_CRITTOGRAFIA)
try {
m = new Messaggio(m.daChi(), m.aChi(),
interlocutori.contiene(m.daChi()) ? idea.decifra(m.cheCosa(), c_sessione)
: rsa.decifra(m.cheCosa(), c_privata));
messaggioToDatagram(m, d);
} catch (KeyException e) {
e.printStackTrace();
}
return m.seqNum();
}
dove ACCLUDI_FIRMA_DIGITALE e ADOTTA_CRITTOGRAFIA sono costanti private di classe usate come flag per rendere più versatile il sistema, escludendo eventualmente la firma digitale e il supporto crittografico.
Il solo metodo public della classe è esegui(), il quale si occupa di realizzare il loop principale:
if (swap.ready()) {
String cmd = swap.readLine().trim();
if (cmd_uscita.contains(cmd)) // cmd_uscita è un Vector coi 4 comandi per terminare
break;
processaComando(cmd); // Metodo d'istanza che processa il comando inserito
}
if (disponibili() == 0) { // Ci sono datagrammi disponibili?
...
}
Le due azioni precedenti vengono ripetute fintanto che dal file di scambio viene letta una linea eguale ad uno dei quattro comandi che determinano la fine dell'applicazione.
Di seguito l'esito della codifica:
| NOME DEL FILE | AZIONE SVOLTA DAL FILE |
| Endpoint.java | Implementazione di un endpoint di rete. |
| Contatto.java | Astrazione di un utilizzatore del sistema software. |
| Lexer.java | Lexer per l'analisi lessicale del file ASCII usato come rubrica persistente. |
| Parser.java | Parser per l'analisi sintattica del file ASCII usato come rubrica persistente. |
| Database.java | Rubrica di tutti i Contatti. |
| MessaggioBase.java | Generico messaggio scambiato fra due utenti. |
| Messaggio.java | Messaggio specifico per le esigenze dell'applicativo in questione. |
| Firma.java | Classe per semplificare l'impiego della firma digitale. |
| Crittografia.java | Classe per semplificare l'impiego della crittografia. |
| SocketUDPaffidabile.java | Realizzazione (abstract) di un socket UDP reliable. |
| Protocollo.java | Insieme delle costanti definite dal protocollo di dialogo. |
| Console.java | Il "lato client" del sistema, usato come terminale di input. |
| Monitor.java | Il "lato server" del sistema, usato come terminale di output. |
| Utili.java | Funzioni di utilità generali. |
| CreaChiaviRSA.java | Programma stand alone per creare delle coppie di chiavi RSA. |
| Cronometro.java | Utility per misurare intervalli di tempo. |
La fase di test ha proceduto correttamente, senza inconvenienti considerevoli.
Le prestazioni crittografiche non sono così "drammatiche" come ci si poteva aspettare, fornendo un'interattività sufficientemente buona da rendere il prodotto sicuramente accettabile. Anche la firma digitale richiede pochi millesimi di secondo, facendo sì che la scalabilità complessiva sia discreta.
Particolare degno di nota è il funzionamento delle java.net.DatagramSocket: nonostante la dimensione massima di un datagramma UDP sia di 64Kbyte, il messaggio più lungo che si è riusciti a scambiare si attesta sui 12Kbyte circa, adottando il JDK versione 1.2.2 su piattaforma Windows 98. Impossibile porre rimedio al problema, anche agendo sui buffer di invio/ricezione tramite i metodi setReceiveBufferSize(int) e setSendBufferSize(int) appartenenti ad un oggetto di tipo java.net.DatagramSocket.
Un problema riscontrato, peraltro non imputabile al progetto in esame, risiede in un certo overhead introdotto dalla libreria Cryptix 3.2.0 quando genera la chiave di sessione per la prima volta: prove sperimentali hanno dimostrato che tale package impiega venti/trenta secondi per creare la prima chiave di sessione, dopodiché le chiavi successive richiedono pochi decimi di secondo. Apparentemente inspiegabile la causa di ciò, potrebbe essere il caso di cercare entro il codice sorgente del package stesso il motivo di questo avvio assai lento. Improbabile che la tecnologia JIT possa produrre benefici così estremi.
A seguito dei test condotti è emerso un particolare interessante: l'implementazione dell'algoritmo RSA inclusa entro Cryptix 3.2.0 è "parziale", nel senso che obbliga ad utilizzare chiavi pubbliche in fase di cifratura e chiavi private all'atto della decifratura. Questo non fa parte dell'algoritmo stesso, perché secondo le sue specifiche le due chiavi sono totalmente intercambiabili. E' immediato verificarlo anche osservando la dimostrazione matematica dell'algoritmo stesso!
La cosa lascia certamente perplessi; non è sembrato il caso di disturbare gli autori della libreria in merito alla questione.
Il codice prodotto è stato realizzato con i commenti opportunamente
formattati per venire elaborati dal tool javadoc fornito
col JDK della SUN®; la documentazione così ottenuta è ispezionabile
seguendo questo link.
Il sistema software complessivo appare accettabile, pur mantenendo certi aspetti un poco "rudi" per quanto concerne la gestione del database e l'interfaccia fornita. D'altronde questo rientra nelle decisioni prese in fase di lavorazione.
Il protocollo crittografico adottato risulta sufficientemente sicuro: gli unici attacchi cui è soggetto sono quelli di forza bruta, come tutti i messaggi cifrati, ed i replay attack relativi al messaggio di SYN. Motivando questo secondo problema, la cosa sta a significare che un intruso dotato di sniffer, consapevole che il primo datagramma inviato da un utente è certamente un SYN, può registrare tale informazione per poi riproporla in un secondo tempo al destinatario del messaggio stesso.
Questo non è un problema, perché la risposta ad un SYN è cifrata con la chiave RSA pubblica del ricevente, e solo quest'ultimo è in grado di estrarre la chiave di sessione contenuta nel datagramma. Il solo inconveniente è che il gruppo di discussione crede di aver introdotto un nuovo membro quando invece questi ignora completamente la situazione!
In un'ottica di "prodotto atto all'uso" è consigliabile anche limitare la scalabilità del sistema, ponendo un limite massimo al numero di membri appartenenti ad un gruppo di discussione. La cosa non presenta difficoltà, vista l'architettura adottata.
Un possibile miglioramento consiste nell'adozione di directed broadcast per l'invio dei messaggi di SYN: questo obbliga a non utilizzare ARQ per tali datagrammi, perché a fronte di un unico invio sono prevedibili molteplici ricezioni, quindi altrettanti acknowledge, peraltro non significativi perché solo il destinatario cercato è in grado di risalire al numero di sequenza corretto del segmento ricevuto, essendo protetto da cifratura RSA.
A tal fine è presente la funzione directedBroadcast(java.net.InetAddress) entro il file Utili.java, anche se non viene usata in questa versione dell'applicativo.
Da evidenziare il mancato uso dei thread per assicurare la portabilità su JVM con scheduler not-preemptive (vedi Solaris).