2. ARCHITETTURA DEL SISTEMA.
Progetto per il Corso di “Reti di Calcolatori” (Prof. A.Corradi)
“Database distribuito
per una struttura ospedaliera”
(R.Castagnoli)
1. PRESENTAZIONE DEL PROBLEMA.
3. REQUISITI DEL SISTEMA SOFTWARE.
4. PROBLEMATICHE INDOTTE DALLA SCELTA DELLE TECNOLOGIE.
5. PROTOCOLLI.
7. ESECUZIONE.
8. ASPETTI PER POSSIBILI MIGLIORAMENTI.
9. REFERENCES.
10.IMPLEMENTAZIONI DI CORBA PRESE IN CONSIDERAZIONE
1. PRESENTAZIONE DEL PROBLEMA.
AUTOMATIZZARE E OTTIMIZZARE LE OPERAZIONI DI GESTIONE SUI DATI DEI PAZIENTI IN UNA STRUTTURA OSPEDALIERA, GARANTENDO UN ACCESSO CONCORRENTE E DISCIPLINATO AD ESSE.
3. REQUISITI DEL SISTEMA SOFTWARE.
Protezione delle informazioni.
Soluzione:devono essere garantiti accessi controllati alle informazioni sulla base di livelli di privilegio assegnati ai vari utenti. Si assume che ogni componente del personale medico-infermieristico afferisca ad un reparto. Il personale è suddiviso in 4 “classi”:
|
|
Lettura |
Modifica |
Creazione |
Cancellazione |
Capability |
|---|---|---|---|---|---|
|
Infermieri |
X |
|
|
|
40 |
|
Medici di reparto |
X |
X |
|
|
30 |
|
Specialisti |
All |
All |
|
|
20 |
|
Primari |
X |
X |
X |
X |
10 |
Nota: All:“su tutti i reparti“; X:“solo sul reparto a cui l'utente afferisce“.
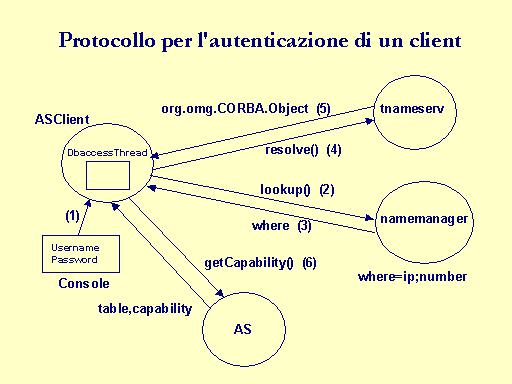
Al momento dell'accesso al sistema, l'utente inserisce una coppia username e password: la password viene cifrata e trasmessa all'oggetto AS che esegue il controllo assegnando una capability all'utente. La capability viene trasmessa in chiaro. Nell'esecuzione di qualsiasi operazione sul database, l'utente usa la capability che gli è stata assegnata dal sistema. Il controllo se una operazione è consentita o meno può essere eseguito sia a livello di client che a livello di server. Una ragione per farlo a livello di client è quella di sollevare i server da un ulteriore carico computazionale, effettuando così un miglio bilanciamento del carico di lavoro nel sistema. Una ragione per farlo a livello di server è quella che è possibile cambiare con più facilità le politiche di accesso relativamente alle varie capability(si assume che i server siano in numero sicuramente minore rispetto ai client). E' stato scelto il controllo dal lato server.
Al fine di evitare accessi non autorizzati al sistema e di garantire un uso razionale delle risorse, il sistema prevede una terminazione automatica del client qualora per un tempo fissato non siano eseguite operazioni dall'utente.
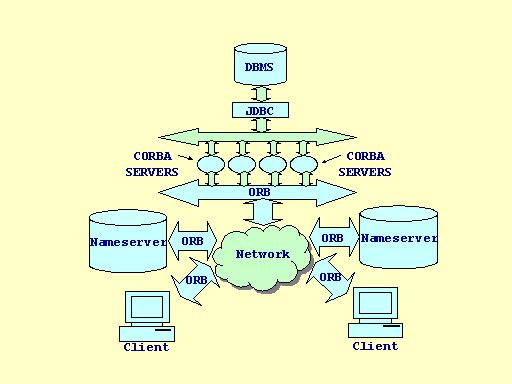
Sistema espandibile che supporti eterogeneità a livello di architettura, di sistema operativo e di linguaggio di implementazione.
Soluzione: utilizzo dello standard CORBA e della tecnologia JDBC per accedere ad un DBMS relazionale che ospita i dati nel sistema. In particolare è stato usata un'implementazione di CORBA 2.0 che garantisce l'interoperabilità degli ORB, ovvero la possibilità di poter usare da un client, che utilizzi un ORB realizzato da un certo produttore, un oggetto CORBA istanziato su un secondo ORB realizzato da un secondo produttore. L'implementazione scelta è SUN IDL.
Java è stato scelto come linguaggio di implementazione per garantire eterogeneità a livello di architettura e sistema operativo. Inoltre la scelta di utilizzare la tecnologia JDBC motiva l'adozione di Java come linguaggio di programmazione lato-server. Java è usato anche come linguaggio di programmazione lato-client per la semplicità che assicura nella realizzazione di GUI e nell'intenzione di realizzare successivamente i client mediante applet.
Facilità d'uso.
Soluzione: GUI per utilizzare il sistema a livello client e trasparenza, dal punto di vista dei clienti, dei fornitori del servizio: ogni client conosce solo dinamicamente i fornitori dei servizi che a lui sono assegnati dal sistema stesso. Questo è reso possibile dall'utilizzo di un sistema di nomi.
Sistema tollerante ai guasti.
Soluzione: è garantita la continuità del servizio nella ipotesi di guasto singolo. Tale ipotesi si concretizza secondo il seguente schema:
GUASTO SUL DBMS: secondo l'interfaccia JDBC, gli oggetti CORBA accedono al DBMS soltanto mediante query SQL. Nel sistema, tali query sono realizzati mediante TRANSAZIONI.
- disattivazione della politica di autocommit(default nel driver JDBC presente nell'SDK 2) per ogni query sul DBMS;
- inserimento della query in un blocco try che preveda come ultima istruzione il commit;
- inserimento del rollback nel blocco catch corrispondente.
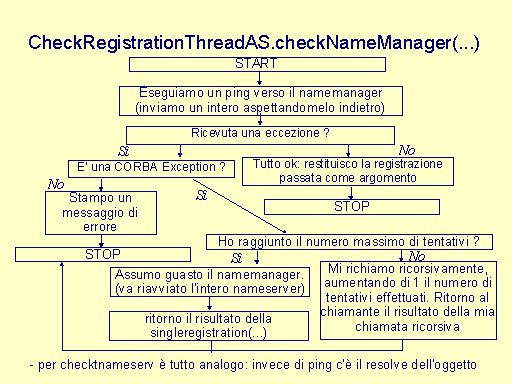
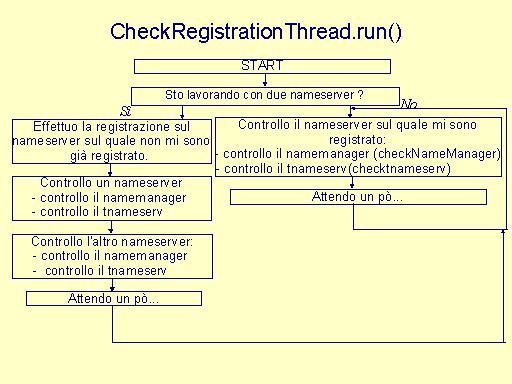
GUASTO SUL SISTEMA SI NOMI(caso di due nameserver): si assume che su soltanto un nameserver alla volta si verifichi un guasto; più precisamente, non è possibile che si verifichino contemporaneamente guasti su entrambi i nameserver nè che si verifichi un guasto su un nameserver nell'intervallo di tempo che intercorre tra il verificarsi del guasto e il ripristino del servizio dull'altro nameserver. Nell'ipotesi di guasto singolo, lavorando con due nameserver, un guasto sul sistema di nomi non causa alcun problema sul client che sicuramente riesce ad ottenere sempre i riferimenti agli oggetti CORBA che utilizzerà. Dal lato servitore, il guasto singolo sul sistema di nomi è risolto da un thread che ogni server avvia(appena avvenuta la registrazione iniziale su entrambi i nameserver) e che si occupa di andare a controllare, ciclicamente e ad intervalli di tempo prestabiliti(individuati durante la fase di debugging), il buon funzionamento dei nameserver(cfr. Implementazione - Lato Server).
GUASTO SU UN SERVER: sono possibili n guasti su n server nel caso in cui per ogni tipo di servizio abbiamo attivi n+1 server. Ad esempio, con due server di autenticazione è garantita la disponibilità del servizio di autenticazione nell'ipotesi di guasto singolo su di essi. Non ci sono problemi di ripristino dello stato dei server perchè i server realizzati sono stateless. Un guasto su un server, tecnicamente, si traduce nella nascita di un dangling reference(cfr. Protocolli).
GUASTO SU UN CLIENT: non creano problemi poichè i client, se si esclude il lavoro che è stato fatto da un certo utente e ancora non è stato salvato, sono stateless.
4. PROBLEMATICHE INDOTTE DALLA SCELTA DELLE TECNOLOGIE.
I riferimenti.
Esattamente come utilizzerebbe un oggetto locale, un client ha bisogno di un „riferimento“ per potere utilizzare un oggetto CORBA. Secondo le specifiche di CORBA, i riferimenti possono essere di due tipi: persistent o transient. Un riferimento è chiamato IOR(Interoperable Object Reference). Un transient IOR è valido e riferisce l'oggetto solo fino a che il corrispondente server è attivo: una volta che il server termina, esso è „dangling“, anche se poi il server viene riavviato. Al contrario, un persistent IOR denota sempre lo stesso oggetto CORBA anche se il server viene riavviato sullo stesso nodo o su uno differente. E' il server che decide quale tipo di IOR vuole usare per l'oggetto(o gli oggetti) che registrerà presso il nameserver. Nel progetto sono utilizzati solo transient IOR(gli unici supportati da Java IDL). Il motivo dell'invalidità degli IOR dopo un server shutdown è il seguente: ad ogni server è assegnato un identificatore unico nel momento in cui viene avviato. Quando il server genera un IOR che identifica l'oggetto CORBA che vuole registrare, l'ORB inserisce all'interno dell'IOR stesso l'identificatore unico del server. Poi l'oggetto è registrato sul nameserver. Se il server cade ed è riavviato, otterrà un altro identificatore unico, diverso dal precedente; quando si vedrà arrivare una richiesta di servizio con il vecchio IOR, trovandovi all'interno un identificatore che non è più il suo, non risponderà alla risposta, certo che l'oggetto coinvolto nell'operazione deve essere gestito da un diverso server nel sistema. L' IOR è divenuto un dangling reference.
Siccome le specifiche OMG di CORBA, al momento del progetto, non standardizzavano il formato di un IOR,“vendor's ORBs“ differenti utilizzano differenti convenzioni nella creazione degli IOR stessi. Di conseguenza non è possibile creare del software portabile su differenti ORBs che ottenga, scandendo gli IOR, informazioni circa l'allocazione dei server e la „paternità“ degli oggetti CORBA. In altre parole non è possibile utilizzare gli IOR per risolvere il problema dei dangling references. Quindi vanno previste le seguenti azioni: 1) deve essere notificato al nameserver la non raggiungibilità del server(al fine di evitare che vengano dati dangling references ai client che richiedano l'uso dell'oggetto); 2) il nameserver deve deregistrare l'oggetto; 3) il client che si è accorto del dangling reference, deve comunque ottenere un riferimento valido per poter eseguire le azioni che desidera sull'oggetto. JAVA IDL non fornisce un supporto per questo.
(References: Michi Henning: „Binding, Migration and Scalability in CORBA“ – Communications of the ACM)
Soluzione.
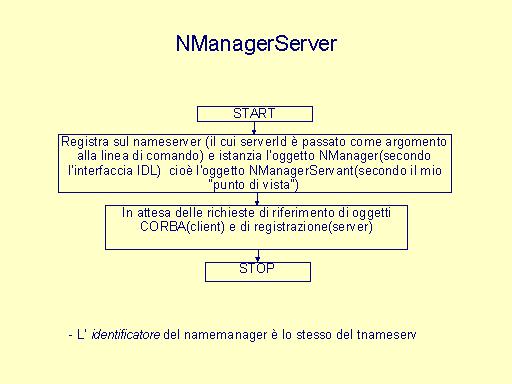
E' possibile rivolgersi ad un agente che tiene traccia di tutte le registrazioni effettuate sul nameserver e che quindi conosce tutti gli oggetti CORBA e i server che li hanno registrati. Tale agente è in grado di identificare gli oggetti in base alla allocazione dei server che li hanno registrati. L'ipotesi è sempre quella che ogni server registri uno ed un solo oggetto CORBA nel sistema. Quando un server vuole registrare un oggetto sul nameserver, si rivolge all'agente con il suo indirizzo IP e ottiene un identificatore unico sul nodo, sul quale sta eseguendo, relativamente al servizio offerto(ovvero per la classe dell'oggetto CORBA che ha intenzione di registrare). Nel progetto, come identificatore è stato scelto un valore intero: il server descriptor. L'agente che si occupa di mantenere la consistenza e l'organizzazione del nameserver è stato chiamato namemanager.
Struttura di un nameserver secondo le specifiche dell'OMG.
Un nameserver è organizzato ad albero analogamente ad un file system di un sistema operativo Unix-like o Win 9x: è un oggetto della classe NamingContext che „contiene“ oggetti di classe NamingContext; la singola registrazione è un oggetto della classe NameComponent. Riferendosi all'analogia con un file system, gli oggetti di classe NamingContext sono le directory mentre gli oggetti di classe NameComponent sono i file. Per semplicità, e comunque senza perdere in generalità, supponiamo di muoverci con un solo livello di profondità dell'albero, ovvero di avere un unico oggetto NamingContext, il „root NamingContext“. Fondamentalmente un oggetto di classe NamingContext presenta una interfaccia con le seguenti operazioni:
- void bind(NameComponent[] n,org.omg.CORBA.Object obj) |
- org.omg.CORBA.Object resolve(NameComponent[] n) |
- void unbind(NameComponent[] n) |
La singola registrazione viene effettuata passando al metodo resolve un array (di un solo elemento) di oggetti della classe NameComponent. Un oggetto della classe NameComponent è costituito da due attributi:id e kind(entrambi sono due stringhe). La coppia (id,kind) costituisce la chiave della registrazione: di conseguenza, non si possono registrare due oggetti in un nameserver con la stessa coppia (id,kind). Quando un server decide di registrare un oggetto CORBA, deve scegliere le due stringhe.
Nota: da questo punto in avanti, con il termine nameserver si indicherà la coppia tnameserv(ovvero il nameserver fornito da JAVA IDL) e namemanager.
NManager è la corrispondente interfaccia IDL. Il sistema è stato provato sia nella configurazione con un solo nameserver sia in quella con due nameserver.
Assegnamento dei server descriptor.
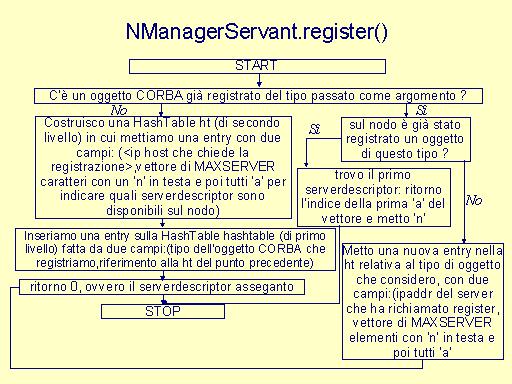
Un oggetto NManager, in pratica un namemanager, ha uno stato interno costituito da una HashTable; ogni sua entry è costituita da due elementi: l'identificatore del servizio(ovvero la classe dell'oggetto CORBA come indicato nel file idl) e il riferimento ad una HashTable. L'entry di quest'ultima è costituita da una coppia: un indirizzo IP e un array di MAXSERVER elementi. Ogni elemento è un carattere che può essere „n“(=not available) o „a“(=available); i server descriptor sono gli indici dell'array, da 0 a MAXSERVER-1. Il server descriptor i-esimo è disponibile quando l'elemento i-esimo dell'array è al valore „a“; effettuato l'assegnamento, l'elemento viene portato al valore „n“.
L'uso del namemanager garantisce ulteriore dinamicità rispetto ad una configurazione che non lo preveda. Infatti i server non conoscono a priori il nome completo che useranno nella registrazione nè i client conoscono staticamente il nome che devono usare per reperire i riferimenti agli oggetti . Quello che un server deve conoscere a priori è il nome della classe dell'oggetto che vuole istanziare come indicato nella interfaccia IDL e l'indirizzo IP del nodo sul quale esegue. Il nome IDL della classe dell'oggetto è anche l'unica informazione che il client deve avere per poter ottenere un riferimento ad un oggetto CORBA.
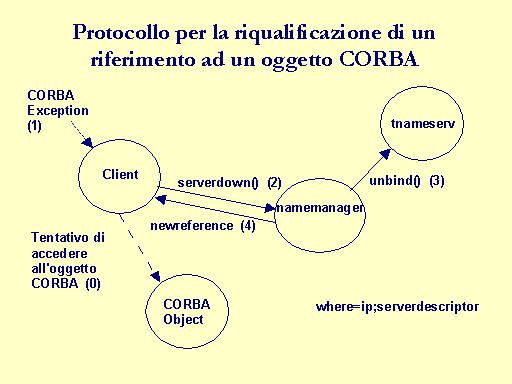
Rimozione di un binding non più valido.
Un'azione ulteriore da compiere è quella di eliminare i bindings non più validi all'interno del nameserver: per questo serve conoscere la coppia (id,kind) dell'oggetto non più disponibile. Tale coppia è senz'altro conosciuta sia dal client che dal server dell'oggetto, poichè il primo ha ricevuto il riferimento e il secondo ha registrato l'oggetto. La soluzione adottata è quella di considerare il client come il punto di partenza per la riqualificazione di un riferimento, dal momento che si può sfruttare il meccanismo delle eccezioni che CORBA fornisce. Infatti, il client, ricevendo una eccezione nella chiamata ad un metodo di un oggetto CORBA, è certo che il relativo server non è più disponiblie e con esso anche l'oggetto. Esso rende nota la situazione al namemanager che, conoscendo sia l'allocazione fisica degli oggetti sia i bindings che sono stati stabiliti all'interno del nameserver, si potrà occupare di eliminare il binding non più valido nel tnameserv, aggiornare il proprio stato interno(hashtable) e restituire al client un riferimento ad un nuovo oggetto CORBA che possa eseguire le stesse funzionalità di quello appena invalidato. Questo meccanismo garantisce un supporto per una forma di migrazione degli oggetti CORBA. Ipotizziamo che un server venga terminato e poi riavviato su un nuovo nodo: questo significa che il server si sarà registrato di nuovo. Un client possiede un riferimento all'oggetto ma relativo alla prima allocazione. Quando tenta di eseguire un metodo dell'oggetto si accorga di avere un dangling reference. Avverte il namemanager che elimina la registrazione non più valida e restituisce al client il riferimento all'oggeto CORBA nella sua nuova allocazione. Il fatto che il namemanager limiti il numero di server( e quindi di oggetti) sul singolo nodo, assicura un load sharing statico. Qualora si tenti di superare tale limite MAXSERVER, il server non riesce a registrarsi e resta in attesa riprovando la registrazione ad intervalli regolari: dal suo punto di vista, il nameserver è come se fosse non disponibile.
6. IMPLEMENTAZIONE.
Ecco le interfacce degli oggetti CORBA utilizzati nel sistema, secondo le specifiche del linguaggio IDL.
INTERFACCE IDL.
|
module DBApp { interface DBS { string execquery(in long capability,in string table,in string queryTable,in string query); };
interface DBC { long execquery(in long capability,in string table,in string queryTable,in string query,in string filecc,in string cc); };
interface DBM { long execquery(in long capability,in string table,in string queryTable,in string query,in string filecc,in string cc); };
interface DBD { long execquery(in long capability,in string table,in string queryTable,in string query,in string filecc); };
interface NManager { long register(in string name,in string ip); string lookup(in string name); string serverdown(in string name,in string kind); long ping(in long i); };
}; |
|
module Security { interface AS { string getCapability(in string username,in string cpassword); };
}; |
Gli oggetti DBS, DBD, DBC, DBM, AS utilizzano l'interfaccia JDBC eseguendo delle query sul DBMS mediante i metodi execquery e getCapability.
|
OGGETTO |
QUERY ESEGUITA |
|
DBC |
CREATE |
|
DBD |
DELETE |
|
DBM |
UPDATE |
|
DBS |
SELECT |
Transazioni.
Secondo la tecnologia JDBC, il DBMS comunica agli oggetti CORBA la non riuscita di una query mediante delle SQLExceptions. Per realizzare delle transazioni, è sufficiente raccogliere tali eccezioni dagli oggetti CORBA assumendo che il verificarsi di una di esse implica il rollback dell'azione mentre una loro assenza implica il commit. In particolare, questo è stato relizzato con le seguenti operazioni:
- disattivazione della politica di autocommit(default nel driver JDBC presente nell'SDK 2) per ogni query sul DBMS;
- inserimento della query in un blocco try che preveda come ultima istruzione il commit;
- inserimento del rollback nel blocco catch corrispondente.
Il JDBC permette inoltre di settare delle particolari proprietà per le transazioni, ma non sono state prese in considerazione perchè non supportate dal DBMS utilizzato.
|
Lato Name Server. |
|
|
|
Linea di comando: java NManagerServer <tnameserv ID> dove <tnameserver ID> identifica il tnameserv nel sistema(es. numero di porta,indirizzo IP del nodo sul quale è in esecuzione) |
|
|
E' il metodo usato da un server per registrarsi presso il nameserver: public int register(String name,String ip) dove name è il tipo di oggetto CORBA che il server ha intenzione di registrare (come indicato nell'interfaccia IDL dell'oggetto) ip è l'indirizzo IP del server che sta eseguendo la richiesta.
|
|
|
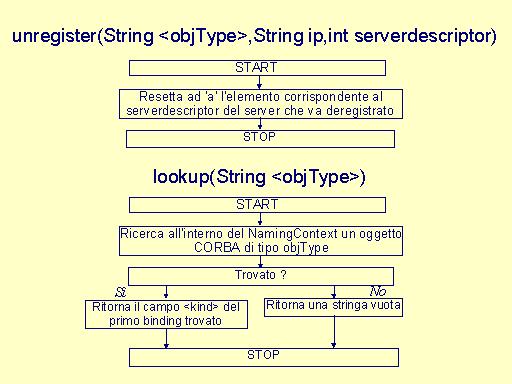
private void unregister(String name,String ip,int number) è richiamato da serverdown.
public String lookup(String serverType) è richiamato ogni volta che si vuole riferimento ad un oggetto CORBA, conoscendone solo il tipo serverType. Ritorna where, ovvero la stringa <indirizzo ip>;<serverdescriptor> che identifica univocamente l'oggetto CORBA di tipo serverType. |
|
|
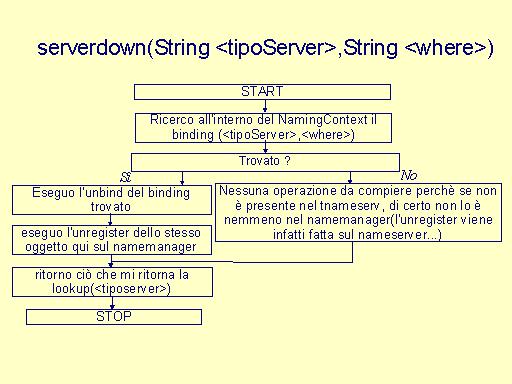
public String serverdown(String name,String kind) è richiamato da un client quando si accorge, avendo ricevuto una eccezione CORBA, che l'oggetto al quale tenta di accedere non è più disponibile. |
|
(si fa riferimento all'AS ma è tutto analogo per gli altri tipi di server). |
|
|
|
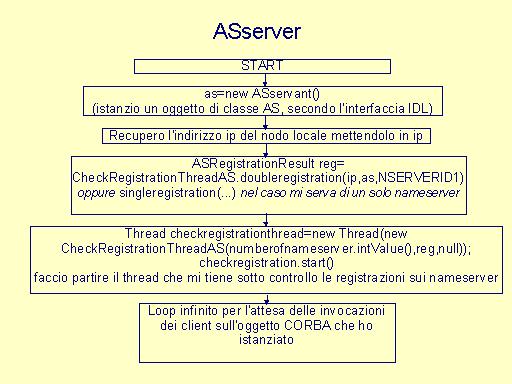
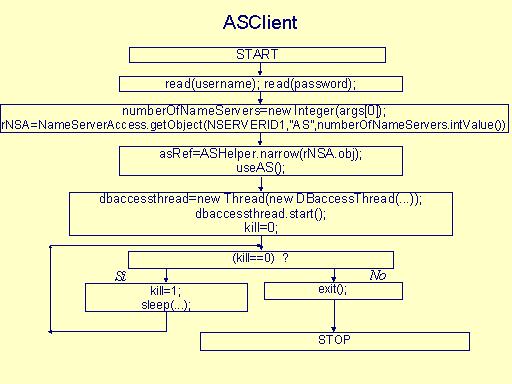
Linea di comando: java NewASserver <number of name servers> dove <number of name servers> è il numero di name servers che sono utilizzati nel sistema. |
|
|
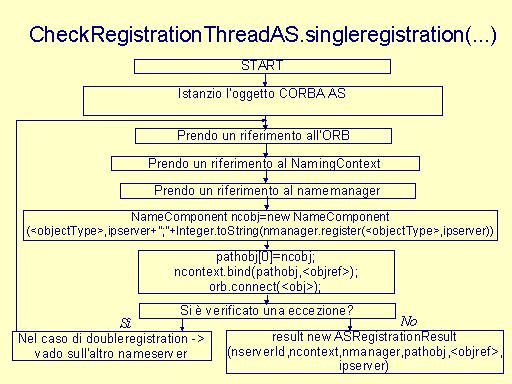
public static ASRegistrationResult singleregistration(String ipserver,ASservant as,String nserverId) public static ASRegistrationResult doubleregistration(String ipserver,ASservant as,String nserverId)
|
|
|
private ASRegistrationResult checkNameManager(ASRegistrationResult reg,int attempt) private ASRegistrationResult checktnameserv(ASRegistrationResult reg,int attempt) Il server, dopo aver effettuato la registrazione, avvia un un processo CheckRegistrationThread che controlla il/i nameserver , sul quale è stata effettuata la registrazione: il thread utilizza i metodi checkNameManager e checktnameserv per controllare le due componenti del nameserver. Il processo è un loop infinito e viene descritto da CheckRegistrationThread.run()
|
|
|
Ogni server avvia un thread di questo tipo per controllare le registrazioni sui nameserver. |
|
Lato Client. |
|
|
|
Linea di comando: java ASClient <number of name servers> dove <number of name servers> è il numero di name servers che sono utilizzati nel sistema. Per accedere al database, il thread che sta eseguendo il main avvia un secondo thread della classe DBaccessThread. e poi, si mette in attesa risvegliandosi ad intervalli di tempo prestabiliti. Ogni volta che si risveglia controlla il valore della variabile kill e quando non la trova uguale a 0, termina. Al contrario, se la trova a 0, la pone a 1 e si rimette in attesa. |
|
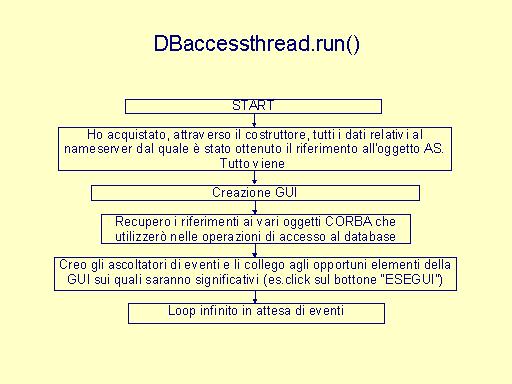
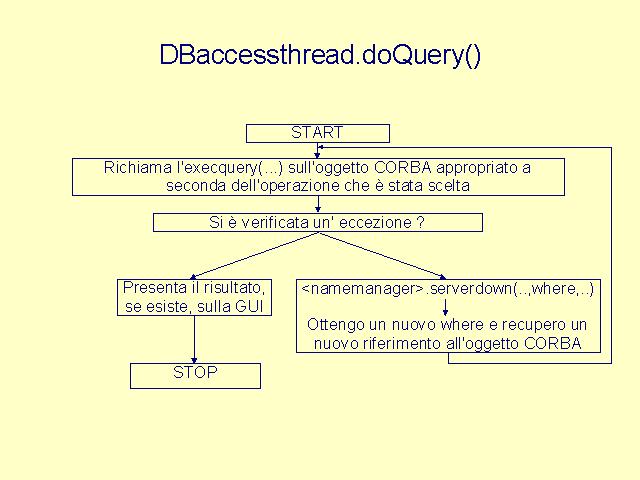
|
Il thread DBaccessThread manda in esecuzione le query dell'utente: ogni qualvolta l'utente richiede una operazione, la variabile kill (visibile sia dal thread principale che dal thread DBaccessThread) viene posta da esso a 0. |
|
|
Esecuzione delle query sul database. |
7. ESECUZIONE.
|
Lato Name Server (per ogni nameserver che si avvia) |
tnameserv -ORBInitialHost <ind IP del nameserver> |
|
java NManagerServer <ind IP del nameserver> |
|
|
Lato Server (almeno una istanza di tutti quelli indicati) |
java NewASserver <numero di nameserver> |
|
java NewDBSserver <numero di nameserver> |
|
|
java NewDBCserver <numero di nameserver> |
|
|
java NewDBMserver <numero di nameserver> |
|
|
java NewDBDserver <numero di nameserver> |
|
|
Lato Client |
java ASClient <numero di nameserver> |
8. ASPETTI PER POSSIBILI MIGLIORAMENTI.
LOAD BALANCING e LOAD SHARING.
- Si può prevedere un vettore di MAXSERVER interi come campo ulteriore di ogni entry delle hashtable di secondo livello all'interno del namemanager: ogni elemento del vettore si riferisce ad un oggetto CORBA istanziato sul nodo e il valore intero(che chiameremo load)indica il numero di client che ne hanno richiesto un riferimento. Quando un server registra un oggetto CORBA nel sistema, il corrispondente load viene posto a 0 dal nameserver. Ogni volta che un client richiede un riferimento ad un oggetto, il nameerver si incarica di fornirgli quello relativo all'oggetto il cui corrispondente valore intero nel vettore è il più basso(cioè per il quale sono stati chiesti meno riferimenti, e che quindi presumibilmente deve sopportare il carico di lavoro meno elevato). Allo stesso tempo è incrementato di 1 tale valore intero. Successivamente va previsto il procedimento per decrementare i valori interi degli elementi dei vettori. Si possono seguire due strade: 1) sono decrementati autonomamente dal nameserver ad intervalli di tempo fissati(tali intervalli saranno il tempo medio previsto di vita di un client); 2) sono decrementati dal nameserver solo dopo che il client, prima di terminare(e quindi prima di “liberare” i riferimenti che possedeva) notifica ad esso la sua prossima terminazione. Durante la fase di recovery da un guasto su un nameserver, va previsto un protocollo tra i due nameserver per recuperare(dal nameserver rimasto attivo) tutte le informazioni sul carico.
SICUREZZA.
- La cifratura e decifratura delle password: possibile mediante delle classi della SDK2 SUN.
MODIFICHE NELL'UTILIZZO DELLA TECNOLOGIA JDBC.
- L'utilizzo di un altro DBMS al posto di MSAccess: INTERBASE(Borland) permette di accedervi in remoto mediante l'URL utilizzato per ottenere l'oggetto Connection(connessione al database).
- Lo spostamento dei files di testo utilizzati per registrare i dati delle cartelle sul nodo nel quale è posto il database (diverso da quello in cui si può trovare un oggetto CORBA che vi accede -> classe URLConnection).
Al momento, per semplicità, il database e i files di testo relativi alle cartelle si trovano sullo stesso nodo in cui sono in esecuzione tutti i server che gestiscono gli oggetti CORBA.
9.REFERENCES.
- OMG: “Naming Service Specification” (version 1.0 – New Edition – April 2000)
- Orfali,Harkey: “Client/Server Programming with Java and Corba” (Wiley)
- Krishnan Eeetharaman: “The CORBA Connection”
(Communication of the ACM,vol.41 n.10)
- Jon Siegel: “OMG overview: CORBA and the OMA in Enterprise Computing”
(Communication of the ACM,vol.41 n.10)
- Steve Vinoski: “New Features for CORBA 3.0”
(Communication of the ACM,vol.41 n.10)
- Douglas C.Schmidt: “Evaluating architecture for Multithreaded ORB”
(Communication of the ACM,vol.41 n.10)
- Michi Henning: “Binding, Migration and Scalability in CORBA”
(Communication of the ACM,vol.41 n.10)
- Paul Haggerty and Krishnan Seetharaman: “The Benefits of CORBA-Based Network Management”
(Communication of the ACM,vol.41 n.10)
- Magelang Institute: “Introduction to CORBA” (Sun's Web site)
- Bryan Morgan: “CORBA meets Java” (Java World)
- Java Developer Connection: “Naming Service”
- Sun's Official Documentation: “The JDBC API version 1.20 – Parts 1,2”
- JavaSoft: “JDBC: A Java SQL API”
- Maydene Fisher: “The JDBC Tutorial and Reference, Second Edition”(JDC)
10. IMPLEMENTAZIONI DI CORBA PRESE IN CONSIDERAZIONE.
|
AUTORE |
NOME |
LINGUAGGI PROVATI |
VERSIONI CONSIDERATE |
|
Gerald Brose |
JacORB |
Java |
Linux |
|
RedHat Labs |
ORBit |
C |
Linux |
|
Borland |
Visibroker |
Java |
Linux e Win98 |