La seconda parte del progetto è consistita, come detto, nella realizzazione di un servizio replicato e partizionato. Il servizio consente all'utente la lettura dei dati contenuti in una tabella vista dal cliente come una risorsa unica, ma in realtà replicata e partizionata su diversi server. Si vogliono soddisfare requisiti di fault-tolerance e load-balancing.
La specifica IDL del servizio (DBService) è la seguente:
module DBService
{ interface tabella
{ string leggi (in string key);
};
};
Per realizzare questa parte del progetto si sono utilizzate delle funzionalità specifiche messe a disposizione da VisiBroker, ma non appartenenti agli standard definiti dall'OMG.
In particolare il VisiBroker supporta una funzione di clustering che permette a una serie di oggetti di essere associati, nel Naming Service, ad uno stesso nome.
Il VisiBroker in questo caso effettua automaticamente load-balancing tra i differenti oggetti appartenenti al cluster. E' possibile scegliere il criterio di bilanciamento al momento della creazione del cluster (cioè solo a compile-time). In questo senso è probabilmente più appropriato parlare di load-sharing, dato che spesso con load-balancing ci si riferisce a sistemi che decidono la politica di bilanciamento dinamicamente in base allo stato corrente del sistema.
I clienti che in successione richiamano il nome associato al cluster otterranno di vedere eseguita la loro richiesta dai diversi server membri del cluster.
In sostanza, quindi, quello del VisiBroker è un meccanismo di multi-bind che associa (nel Name Service) un nome con un gruppo (cluster) di riferimenti ad oggetti.
Attualmente i criteri che il Visibroker mette a disposizione per il load-sharing sono due: RoundRobin e SmartRoundRobin. Tuttavia attualmente viene consigliato di non usare il criterio SmartRoundRobin. Non è supportata l'introduzione di criteri definiti dall'utente ma si prevede comunque di aumentare il numero di criteri disponibili.
Si deve osservare che anche lo Smart Agent di VisiBroker fornisce di per se, automaticamente, funzionalità di load-sharing (round-robin) e di fault-tolerance. Allo startup di un server esso si registra automaticamente allo Smart Agent (se questo è attivo) e questo, di conseguenza, permette al VisiBroker di fornire un semplice, ma non standard, modo per il cliente di ottenere un riferimento al server (bind). Tutta via queste automazioni non vengono gratuitamente in quanto il programmatore non può scegliere i membri che costituiscono un gruppo. Lo Smart Agent fa tutte le decisioni al suo posto. In questo senso il cluster costituisce una valida soluzione in quanto il programmatore può definire il criterio da usare e può scegliere i membri che formano il cluster. E' inoltre possibile, aggiungere e rimuovere elementi dal cluster a run-time. L'utilizzo di un cluster permette quindi una flessibilità notevolmente maggiore.
Per i membri del cluster il VisiBroker fornisce anche una funzionalità di failover per cui è in grado di tollerare eventuali fallimenti dei server. Quindi, quando noi richiediamo al Naming Service un nome che è legato ad un cluster, esso ci ritorna il riferimento ad un membro del cluster (a seconda della politica scelta); se questo membro ha un crash o diventa comunque non disponibile, l'ORB in maniera trasparente effettua il rebind con il prossimo membro del cluster disponibile.
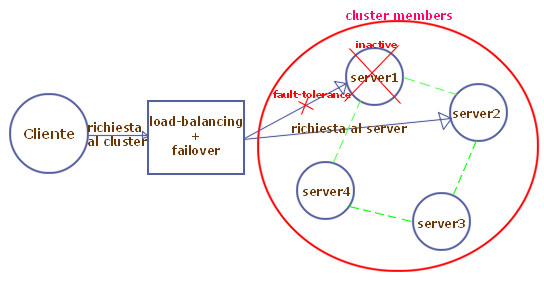
Il funzionamento del meccanismo implementato nel VisiBroker può essere rappresentato dal seguente schema in cui si evidenza un blocco che decide il membro del cluster cui indirizzare la richiesta in base alla politica di load-sharing adottata ed allo stato di disponibilità dei server:
Il server che cade in realtà non viene eliminato eliminato dal cluster ma semplicemente il VisiBroker quando incontra un server del cluster che non risponde, in modo trasparente effettua il rebind con il successivo membro del cluster. Successivamente il server può di nuovo riattivarsi, ritornando così a fornire il suo contributo.
Consideriamo ora gli altri meccanismi alla base del funzionamento del nostro servizio.
Come abbiamo detto i dati sono replicati e partizionati. Questo significa, in pratica, che ogni server possiede un suo file testo contenente delle entry del tipo chiave-valore. Ogni server ovviamente implementa il medesimo servizio di lettura di un valore data in ingresso la chiave. Come abbiamo detto vogliamo che i server possano aggiungersi al cluster in maniera dinamica.
Si suppone inoltre che all'arrivo di un nuovo server, il suo file testo contenga la versione più aggiornata dei dati.
All'inizio quindi il cluster è vuoto, quando arriva il primo server, esso si lega (bind) al cluster, si carica in memoria la tabella letta dal file, mettendo a disposizione tali dati all'utente. Quando arriva un nuovo server (che, per ipotesi, ha dati più aggiornati), questo dopo essersi legato al cluster e dopo aver caricato in memoria i dati corrispondenti al suo file testo, effettua una fase di update dei dati degli altri server. Cioè il nuovo server si collega uno ad uno con tutti gli altri server del cluster e verifica se nella tabella locale del server cui si collega sono presenti entry con valori di chiave uguali ai suoi. Per queste entry verifica se i valori associati alle chiavi sono uguali. I valori non uguali vengono aggiornati con i nuovi valori forniti dal caricamento del suo file testo.
Consideriamo ora il normale funzionamento in cui un utente esegue una richiesta di lettura di un valore.
All'arrivo di una richiesta cliente ad un server si possono verificare due casi:
l'entry è presente nel server stesso: in questo caso il valore posseduto dal server (valore sicuramente aggiornato) può essere restituito direttamente. |
|
|
l'entry non è presente nel server: il server si collega uno ad uno con tutti gli altri server che fanno parte del cluster finché non trova l'entry corrispondente alla chiave richiesta o finché non ha visitato tutti i server. Se l'entry non è in nessun server viene restituito un valore che indica questo fatto. Viceversa se l'entry è stata trovata la coppia chiave-valore viene inserita nella cache del server cui è arrivata la richiesta iniziale e che si è rivolto agli altri. Questo meccanismo consente risposte più veloci per valori richiesti frequentemente (in quanto tali valori finiranno per essere nella tabella in memoria in ogni server). |
Quindi sia nella fase di update iniziale sia nella fase di ricerca della entry richiesta è necessario poter contattare tutti i membri del cluster.
Questo ci è possibile grazie al metodo select() che ci ritorna gli oggetti legati al cluster in base al criterio scelto (round-robin). Se un server del cluster non è più disponibile tuttavia esso ci viene ugualmente ritornato dalla select. Non appena viene invocato un metodo su tale oggetto il VisiBroker si accorge che il server ha problemi ed effettua il rebind con il prossimo oggetto del cluster. Su questo viene eseguito nuovamente il metodo.
Questo comportamento, non intuitivo, è stato dedotto solo in seguito a delle prove in quanto non esiste documentazione al riguardo.
Si potrebbe pensare di eliminare i server inattivi dal cluster. Ciò è possibile attraverso l'uso del metodo _non_existent(), ma introdurre questa fase ad esempio in occasione di ogni richiesta client risulterebbe in un inutile appesantimento del servizio. Infatti si può ragionevolmente supporre che i fallimenti siano piuttosto rari.
Questa fase di controllo viene però introdotta all'avvio di un server. In questo caso vengono eliminati dal cluster tutti i server non attivi. Ciò consente di evitare che la select ritorni tali server e consente di liberare il nome del server caduto. Se infatti il server di nome Server1 cade e allo start-up di un server non si attua questa fase di controllo, il nome Server1 non sarà più usabile. Una soluzione a questo problema si ha anche utilizzando il rebind anzichè il bind nel legare un server al cluster. Il rebind consente infatti anche di legare oggetti con un nome già usato in altro legame. Ciò però avrebbe consentito l'esistenza di 2 server contemporaneamente in esecuzione con lo stesso nome. Inoltre mantenere nel cluster server caduti appesantisce inutilmente la computazione. Per questi motivi non ho seguito questa strada.
La mia soluzione consente quindi che una volta caduto il Server1 arrivi un altro server che si chiama Server1 (magari proprio lo stesso server caduto che ha risolto il problema), ma non consente che ci siano contemporaneamente attivi nello stesso cluster due server con lo stesso nome. Peraltro, come detto, questa fase di "ripulitura" consente anche di evitare che la select ritorni dei server inattivi (cosa che comunque per i meccanismi di failover del VisiBroker non causa problemi).
In generale quindi si possono pensare a politiche diverse per l'unbind, la scelta migliore dipenderà dal contesto cioè dalle caratteristiche del sistema che stiamo di volta in volta realizzando
Si suppone che non vi siano malfunzionamenti nella fase di update che potrebbero portare ad avere dei dati inconsistenti sui vari server. Questo poiché se cade il server che si sta registrando e sta portando dati nuovi alcuni server potrebbero avere dati aggiornati ed altri dati vecchi. La caduta di altri server in questa fase non provoca problemi per i meccanismi spiegati in precedenza. Anche l'arrivo di una richiesta in questa fase potrebbe provocare risultati non corretti. Se abbiamo un numero non troppo elevato di server appartenenti al cluster tale fase è sufficientemente veloce da pensare che non costituisca problemi.
Anche in questa fase di sviluppo del progetto si sono incontrati metodi su cui non ho purtroppo trovato nessuna documentazione e il cui funzionamento è stato capito solo con delle prove. Ciò ha provocato, analogamente ai precedenti casi, allungamenti della fase di codifica.
