
A.A. 1999-2000
BOLOGNA,
Facoltà di INGEGNERIA
Progetto per RETI DI CALCOLATORI
PROPOSTA DI SVILUPPO PER
RETE UTILIZZATA DA UNO STABILIMENTO TERMALE
A cura di
Gianluca Tonti
2148-52009
mailto: gtonti74@hotmail.com
DEFINIZIONE DEL PROBLEMA
Questo progetto presenta una proposta di evoluzione per la rete di uno stabilimento termale presso cui attualmente lavoro: le Terme di Riccione. Il lavoro ha preso spunto ed è stato svolto utilizzando parte delle conoscenze da me acquisite grazie al corso di Reti di Calcolatori e applicandole alla realtà che mi ritrovo ad affrontare. Il progetto parte da una breve analisi della rete presente nello stabilimento per finire con un piccolo esempio applicativo e si articola nei seguenti punti caratterizzanti:
BREVE ANALISI DELLA RETE ATTUALE
Il sistema attualmente presente nello stabilimento può essere così schematizzato:
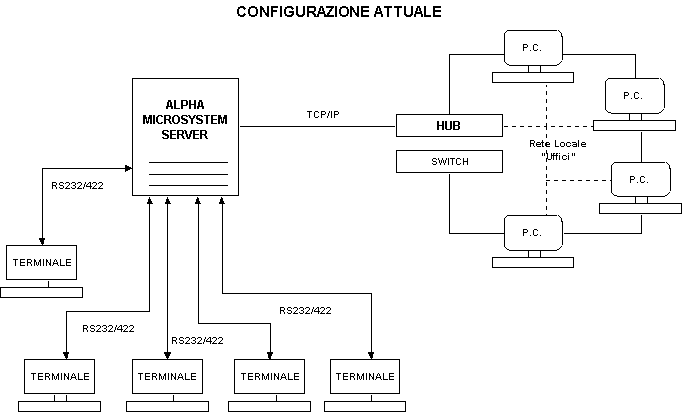
Un server di origine Americana, gestisce in modo centralizzato tutto lo stabilimento. Lavora attraverso porte di comunicazione seriale e gestisce circa 50 posti di lavoro (terminali) divisi tra casse, punti di accettazione cliente, ambulatori(cartelle cliniche), punti di controllo di accesso. Attraverso TCP/IP riesce a scambiare dati con una rete di P.C. con S.O. Windows, utilizzati prevalentemente dagli uffici amministrativi. Questi personal sono collegati con Hub in modo point-to-point. In realtà sono presenti 3 Hub collegati tra loro tramite uno Switch, di cui due sfruttano un collegamento in fibra ottica data la distanza della loro ubicazione (200m.e 500 m.- Lo stabilimento è distribuito su più edifici).E’ possibile anche lavorare con P.C. in emulazione Terminale sul server AlphaMicro.
Nonostante complessivamente il sistema sia abbastanza efficiente, sono due gli svantaggi principali che una rete di questo tipo presenta:
Non prenderò in considerazione la soluzione del primo problema (la particolarità dell’Hardware e del Software), ma mi concentrerò su una ipotesi di soluzione il più possibile economica e praticabile per il secondo problema, ossia ipotizzare un sistema in cui sia superata la gestione centralizzata ed in cui si ottenga un minimo di affidabilità grazie alla replicazione dei dati su più server. In particolare, per superare la congestione ed il rischio dovuto ad un sistema centralizzato propongo un sistema di questo tipo:
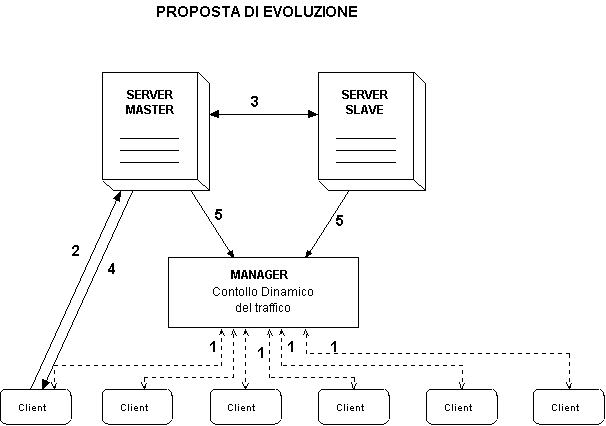
Il nuovo sistema prevede i seguenti componenti:
Nello schema i numeri corrispondono ordinatamente alle comunicazioni che avvengono per portare a termine una sessione di interazione tra un PC Cliente ed uno dei due server che fornisce un servizio.
FASE 1
Prima di tutto un Cliente tenta (1) di comunicare con il Manager. Se il Manager risponde il Cliente lavorerà in modalità che chiamerò DINAMICA nel senso che ottiene dinamicamente dal Manager un indirizzo destinazione del Server a cui si proverà a connettere. Ovviamente il Manager sarà a conoscenza della situazione dei Server: se sono attivi e il numero di connessioni che attualmente stanno servendo. Nel caso in cui il Manager non risponda (perché spento o guasto) o non risponda in tempo utile (perché congestionato, ad esempio) il Cliente ne prenderà atto e si accingerà a lavorare in modalità STATICA, ossia accede ad una tabella allocata su di lui staticamente dal System Manager che specifica ordinatamente gli indirizzi dei due Server.
FASE 2
Poi (2) una volta che un Cliente ha ottenuto, staticamente o dinamicamente che sia, un indirizzo, tenta la connessione con un Server richiedendo il servizio che desidera. Se questo non risponde in tempo utile (sempre perché guasto o congestionato) il Cliente intraprende una iniziativa a seconda della modalità in cui si trova. Se è in modalità Dinamica, riprova a connettersi richiedendo al Manager un altro indirizzo. Se è in modalità Statica invece, tenta con la seconda entry nella tabella. Per l’ipotesi, che faremo, di guasto singolo, almeno un server deve rispondere e il Cliente riuscirà a richiedere il servizio. Il carico sui server in modalità Dinamica può così essere ben bilanciato da un buon Manager, mentre Staticamente occorrerà che il System Manager distribuisca le entry della tabelle ai Client in modo opportuno, assegnando in maniera proporzionata e mirata indirizzi di Server preferenziali (prima entry della tabella) diversi ai vari Client. Staticamente quindi, per qualche Client il server primario (a cui per primo si prova a connettere in modalità statica) sarà il primo, per altri il secondo. Lavorare in modalità STATICA può essere inoltre utile in quei periodi dell’anno (inverno) in cui ci sono pochi Client attivi (5 –6) ed è inutile e costoso impegnarsi con un MANAGER. In questo caso basterà spegnere il Manager e far funzionare di default i Client in modalità STATICA, evitando tutto l’overhead di comunicazione con il Manager.
FASE 3
A fronte della richiesta di un Client ad uno dei Server di un sevizio che richieda una modifica al DB (es. una prenotazione), se entrambi i Server sono attivi, parte la fase (3) di coordinamento tra i due server. Prima di dare risposta al Client modificando permanentemente il DB, infatti, essendo il DB replicato e aggiornato su entrambi per dare continuità e affidabilità al servizio, un server deve necessariamente coordinarsi con l’altro comunicando la variazione apportata. Per semplicità ho utilizzato un modello Master/Slave per i Server. La differenza tra i due sta nel modo in cui vengono gestite le richieste dei Client. Il Master ha più diritti rispetto allo Slave: nel caso di una richiesta, prima modifica localmente il suo DB e poi invia la modifica allo Slave che acconsentirà o meno l’operazione. Se l’operazione viene rifiutata dallo Slave , il Master cancella la modifica che aveva apportato. Lo Slave invece prima di modificare localmente il suo DB ‘sente col Master’ e aspetta la sua risposta affermativa. In questo modo si garantisce che a fronte di due richieste contemporanee sui due server della modifica del DB queste vengano comunque sequenzializzate e non aggiornino in maniera incongruente le due tabelle.
In entrambi i casi, all’avvio un Server dovrà segnalarsi all’altro e verificare se questo sia già attivo. In caso affermativo si riceverà copia del DB corretto e aggiornato, in quanto l’attività dell’altro è indice di DB più aggiornato. In ogni momento se un server manda una richiesta all’altro e capisce che questo è caduto, prosegue da solo e non manda più richieste finchè non riceve dall’altro una segnalazione di ‘Start’, che indica che si è riattivato.
Nel caso di caduta di un server si dovrà procedere alla segnalazione dell’evento al Manager, se attivo, e stabilire un piccolo protocollo che permetta ai Client con esso collegati ed in attesa di risposta al servizio, di stabilire se la richiesta sia andata a buon fine.
FASE 4
Se tutto è andato a buon fine il Server risponde (4) con messaggio al Client di azione terminata correttamente o rifiutata. Il Client può a questo punto decidere di chiudere la sua sessione di lavoro con il Server (connessione) o continuare richiedendo altri servizi.
FASE 5
Nel momento in cui un Client si disconnette perché ha terminato le sue operazioni o cade, il server si accorge dell’evento e lo segnala (5) al Manager (se attivo) che provvederà ad aggiornare la situazione relativa al numero di contatti che il Server che ha fatto la segnalazione ha intrapreso.
Riprenderò dettagliatamente ogni fase nell’esempio applicativo, ma è chiaro fin da ora che una soluzione di questo tipo, nonostante presenti dei vincoli di scalabilità dovuti alla centralizzazione del Manager ed al fatto di avere definito solo un coppia di Server, consente quel giusto grado di replicazione che lo stabilimento richiede. Si garantisce infatti una maggior affidabilità ( si riesce a far fronte ad un guasto singolo) nel rispetto di una maggiore efficienza ottenuta grazie ad un buon bilanciamento del carico. E’ infatti requisito fondamentale l’efficienza del sistema, attualmente ottenuta grazie ad una gestione centralizzata del tutto, che sarebbe compromessa da un eccessivo overhead per il coordinamento tra più server che usino politica diversa da quella banale di Master/Slave. Viste le dimensioni attuali dello stabilimento, ho ritenuto che due fosse il numero adatto di Server da utilizzare. Una ipotesi di ulteriore sviluppo potrebbe essere quella di differenziare i servizi tra vari Server, sempre duplicati per l’affidabilità….
Le ipotesi che intendo assumere sono:
PRESENTAZIONE DELL’ESEMPIO APPLICATIVO
Nel rispetto delle ipotesi assunte, data la vastità del progetto, ho ritenuto che un buon esempio applicativo che tenesse conto delle problematiche espresse, fosse l’implementazione di una parte del servizio di prenotazione delle cure, presente nello stabilimento. Analogamente agli altri servizi, infatti, necessita la connessione ad un Server e può richiedere la lettura, la modifica o la cancellazione di record allocati nel DB, in particolare dei record relativi alle prenotazioni. Per semplicità, dato che interesse del corso non è la realizzazione completa del prodotto, ho introdotto queste ulteriori ipotesi per agevolare il mio compito:
Per la funzionalità dell’esempio, implementerò le operazioni di lettura e scrittura del DB che corrisponderanno alla ‘Visualizzazione della situazione del camerino’ e ‘Richiesta di una nuova prenotazione’. La prenotazione, vista come scrittura del DB, presenta la medesima difficoltà di una cancellazione o modifica, in quanto richiedono entrambi non solo una operazione locale ad un server, ma anche il coordinamento per tenere aggiornate e consistenti le due tabelle (matrici).
Si potrà notare che non viene omesso il trattamento di alcuna problematica e il passaggio ad una realizzazione completa diventa un puro esercizio compilativo se risolto in maniera analoga a quello che verrà proposto.
SCHEMA ILLUSTRATIVO DEL SISTEMA
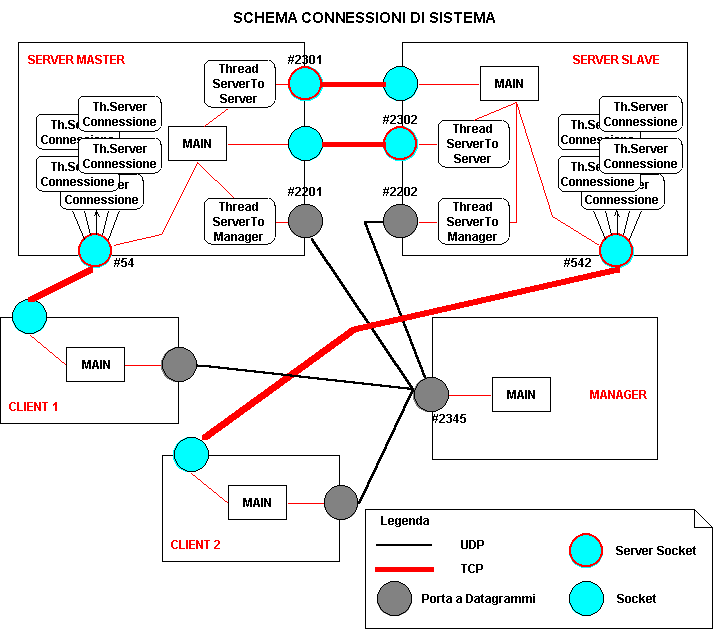
La sequenza temporale delle connessioni è già stata descritta, mentre le modalità verranno trattate nell’analisi dei singoli componenti. Da notare è che nei Server compare un insieme di Thread ServerConnessione: ne verrà generato uno per ogni Client ‘accettato’ dal processo principale del Server. Ognuno di questi Thread avrà la completa gestione della Socket dopo averla ereditata dal processo principale. Rilevanti anche le due Socket aperte sui Server per la comunicazione tra i medesimi: una viene gestita dal processo principale e viene utilizzata per fare richieste all’altro, l’altra viene presa in gestione dal Thread ServerToServer e serve per ascoltare le richieste che provengono dall’altro Server e rispondere opportunamente.
Per semplicità sono stati rappresentati solo due Client collegati, uno ad un Server ed uno all’altro, ma lo schema è aperto ad una molteplicità di Client.
I due Server sono stati implementati come servitori paralleli: creano un Thread differente per ogni Client che devono servire. Utilizza inoltre altri due Thread che avranno il compito rispettivamente di gestire le richieste provenienti dall’altro Server e di gestire le comunicazioni necessarie con il Manager. Nel processo principale viene gestita una Socket per la gestione delle richieste da inoltrare all’altro Server, la Socket ovviamente è attiva solo se l’altro Server è attivo e in questo caso (per le richieste) il Server è Client dell’altro Server (si veda la figura dello schema funzionale per chiarimento). Questo processo ‘main’ resta attivo per tutto il tempo di vita del Server. Lo schema funzionale è il seguente:
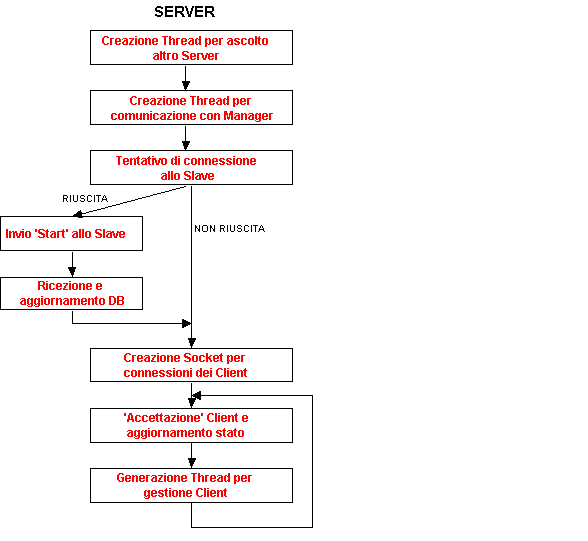
Le variabili locali del Server sono costituite da :
DB camerino // E’ il DataBase gestito dal Server
Boolean unicoServer // Stato: TRUE-Lavora da solo FALSE-Lavora con Slave
InetAddress ipServer // Indirizzo IP dell’altro Server
Int numClientAcc // Stato:Numero di Clienti che si stanno servendo
Vengono qui di seguito riportati i diagrammi funzionali degli altri Thread componenenti il Server.
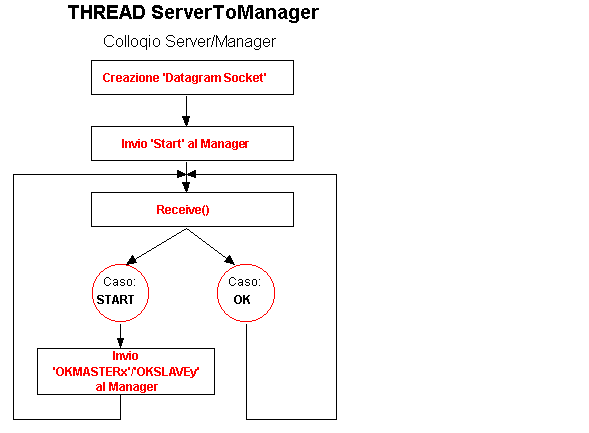
All’apertura il Server deve cercare di segnalare al Manager la sua presenza, dopodiché resta in attesa sulla porta solo per far fronte ad una eventuale caduta del Manager.
Lavora con una Socket a Datagrammi che crea all’avvio, infatti sarebbe troppo oneroso stabilire una connessione permanente data la quantità esigua dei pacchetti inviati e la loro ridotta dimensione. Avviatosi, manda immediatamente al Manager un messaggio di ‘Start’ per segnalarsi e si mette in attesa di una conferma di avvenuta ricezione da parte del Manager (con ‘OK’). Se questa non arriva in tempo utile scade un time-out che segnala al Server che lavorerà senza il coordinatore (non dovrà segnalare al Manager, perché non attivo, che un Client su di lui ha terminato la sua connessione ‘CLIENT DOWN’ o che l’altro Server è caduto ‘MASTER DOWN’ / ’SLAVE DOWN’). Altro messaggio di protocollo che il Server può ricevere è quello di ‘Start’: il Manager si è attivato, ha ripreso a funzionare, o vuole solamente aggiornare il proprio stato. Il Server risponde con ‘OKMASTERx’ o ‘OKSERVERy’ indicando in x o y il numero di Clienti che sta servendo al momento.
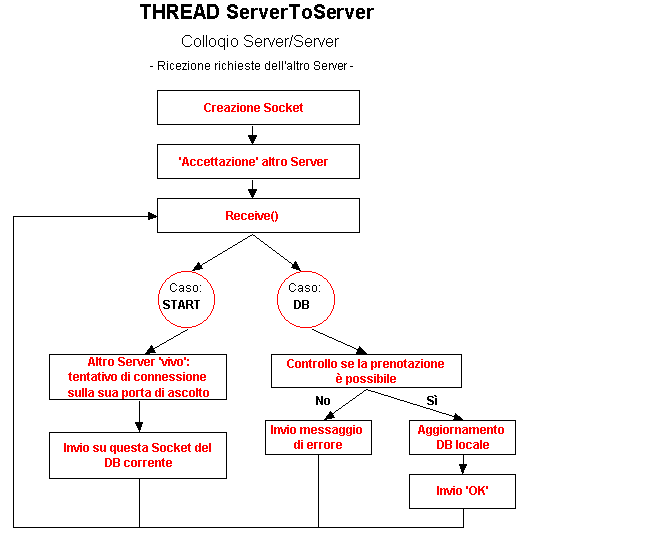
Il Thread ServerToServer all’avvio crea una Socket a Stream e si mette in attesa che l’altro Server si colleghi su questa porta. Stabilita la connessione, questa Socket sarà utilizzata per ‘ascoltare’ tutte le richieste che l’altro Server inoltrerà, a differenza della Socket creata nel processo ‘main’ del Server utilizzata per inviare i propri messaggi. Sono di protocollo due messaggi:
START: Messaggio con cui l’altro Server segnala che si è attivato, che diventa da questo momento disponibile. Alla ricezione, il Server prova dal processo ‘main’ (con l’altra Socket) a collegarsi alla Socket su cui l’altro ‘ascolta’ ed invia su questa Socket (da cui ha ricevuto) all’altro il suo DB corrente (sicuramente più aggiornato) per permettere all’altro di aggiornarsi Aggiorna inoltre la variabile unicoServer del processo principale.
DB: Messaggio con cui l’altro Server richiede di effettuare una prenotazione Per DB si intende una tabella che contiene i record della prenotazione. Alla ricezione, il Server controlla localmente la fattibilità della prenotazione. Se questa non è possibile (caso logicamente verificabile solo nel caso in cui a inviare sia lo Slave, perché il Master ha aggiornato la sua tabella e non ha avuto il tempo di darne comunicazione all’altro) il Server risponde con un messaggio di errore, altrimenti aggiorna il suo DB locale e risponde con un messaggio di ‘OK’.
Nel caso in cui l’altro Server connesso cada, il Server tornerà ad aspettarlo tornando alla fase di accettazione di una nuova connessione.
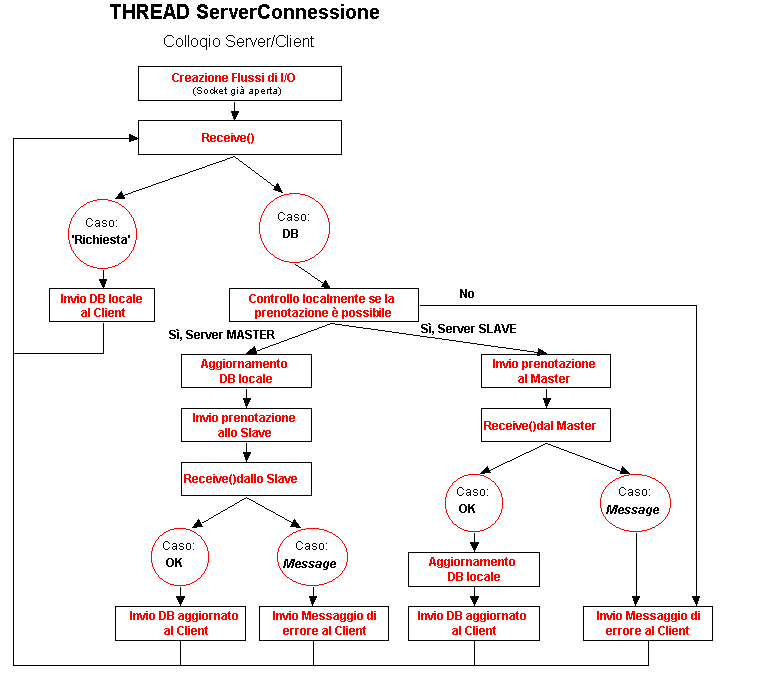
La connessione con un Client è già stata stabilita dal processo principale. Questo Thread non fa altro che trattarla per tutta la sua durata. Viene ovviamente creato un Thread per ogni Cliente (connessione) da servire. All’avvio, dopo una fase di inizializzazione che prevede la creazione dei flussi per la comunicazione, si cicla ripetutamente in attesa di messaggi:
RICHIESTA: Messaggio con cui un Client richiede il DB aggiornato. Alla ricezione, il Server rispone con il suo DB corrente.
DB: Messaggio con cui un Client richiede di effettuare una prenotazione. Per DB si intende una tabella che contiene i record della prenotazione. Alla ricezione, il Server controlla localmente la fattibilità della prenotazione. Se questa non è possibile (orario già occupato, per es.) viene subito inviato un messaggio di errore al Client. Altrimenti il trattamento è leggermente differente tra Server MASTER e SLAVE. Il MASTER aggiorna immediatamente la sua tabella locale e invia copia della prenotazione allo Slave. Appena riceve comunicazione dell’esito ( ‘OK’ o Messaggio di errore dallo Slave) lo trasmette al Client. Il caso di esito negativo non è logicamante possibile e il messaggio di errore consiglia di arrestare il sistema per verificare l’integrità dei dati. Lo SLAVE invece, prima di aggiornare la sua tabella locale aspetta la risposta del Master, poi si comporta in maniera analoga.
Questo è il protocollo nel caso in cui entrambi i Server siano attivi: se uno solo è funzionante il discorso è più semplice in quanto basta aggiornare localmente la tabella e dare risposta al Cliente. Nel caso in cui un Server si accorge che l’altro è caduto invia il messaggio di ‘SLAVEDOWN‘ o ‘MASTERDOWN’ al Manager ed aggiorna inoltre la variabile unicoServer del processo principale.
Vediamo cosa succede, se entrambi i Server sono attivi, nei vari casi in cui uno dei due server può cadere (facendo l’ipotesi di guasto singolo):
Alla ripartenza il server riprende con la procedura di inizializzazione. Ricordo che si suppone che durante l’inizializzazione non si possano verificare guasti.
Il CLIENTE rappresenta una stazione di lavoro effettiva e può richiedere la connessione ad uno dei due Server per ottenere un servizio non locale, che necessita per esempio la consultazione di un DB comune (come la prenotazione realizzata nel nostro caso). Si è pensato di stabilire una connessione di tipo Stream con i Server, data l’importanza dei dati e la mole consistente di informazioni da scambiarsi. Si suppone che l’intero programma venga realizzato in maniera ‘intelligente’, ossia che le operazioni che richiedono una connessione vengano possibilmente effettuate in sequenza e sulla stessa connessione. Ad esempio, è molto probabile che ad una prenotazione segua un pagamento che dovrà essere anch’esso comunicato al Server e quindi è auspicabile che venga utilizzata la stessa connessione aperta e non ne venga invece utilizzata una nuova dopo aver chiuso quella precedente. Ricordo che in questo esempio ho effettuato il caso di una un’unica tipologia di operazione ( la prenotazione), e in effetti da questo punto di vista il discorso è un po’ semplificato e non affronta l’ottimizzazione della gestione del numero di connessioni che il programma nella sua completezza dovrà necessariamente avere. Un CLIENTE lavora comunque sequenzialmente e apre al massimo una connessione. Vediamo il suo schema di funzionamento:
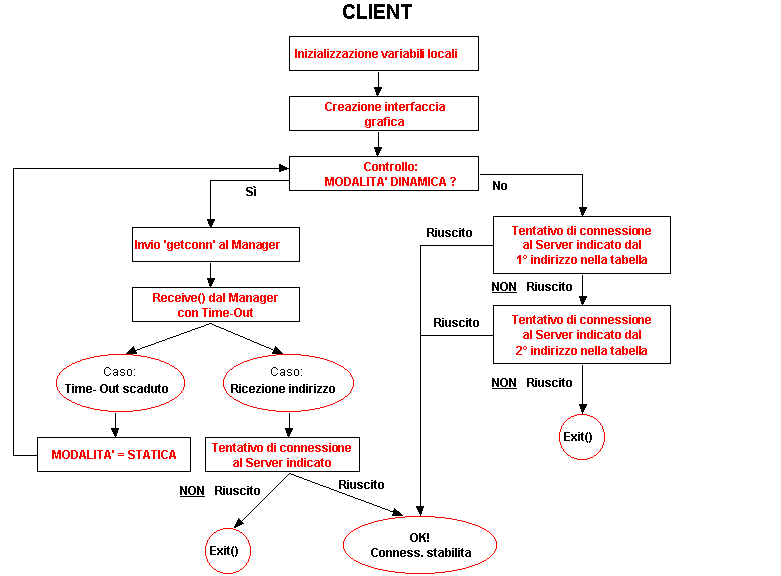
Le variabili locali su cui lavora sono:
Int modalità // Modalità di lavoro: 0-STATICA, 1-DINAMICA
InetAddress AddServer[2] // Indirizzi Server (Tabella Statica)
Nell’ inizializzazione delle variabili il System Manager si può concedere dei ‘gradi di libertà’: in modalità può indicare se inizialmente il Client vuole lavorare in modalità DINAMICA (Default) o STATICA. In questo caso il Client non perderà il tempo necessario a verificare se il Manager sia attivo, ma accede direttamente ai suoi indirizzi in AddServer. In questo caso è importante l’ordine con cui il System Manager ha memorizzato i due indirizzi: il primo è quello a cui il Client proverà a collegarsi come primo tentativo, il secondo verrà utilizzato se questo tentativo non è andato a buon fine. Per un buon bilanciamento dei carichi anche in mod. STATICA è necessario quindi bilanciare equamente questi indirizzi sui vari Client.
Dopo la fase di inizializzazione viene costruita una semplice interfaccia grafica che permetta all’operatore termale di effettuare le sue operazioni. Per quelle non eseguibili localmente (come la prenotazione) tenterà di stabilire una connessione con un Server: questa operazione varia a seconda della modalità di lavoro. Se il Client è in modalità dinamica chiede (attraverso la solita porta di comunicazione in UDP) al Manager l’indirizzo del Server più scarico. Se ottiene risposta in tempo utile tenta subito la connessione all’indirizzo ricevuto, altrimenti, scaduto il time-out, si accinge a lavorare in mod. Statica. Staticamente, accede all’indirizzo indicato per primo nella sua Tabella Statica degli indirizzi, dopodiché, se la connessione non ha avuto un esito positivo, accede al secondo indirizzo che dovrebbe dare esito positivo vista l’ipotesi di guasto singolo per i due Server fatta in principio.
Nello schema, l’indicazione di uscita (Exit()) non è una uscita dal programma globale, ma richiede solo di effettuare un altro tentativo di connessione, per poter eseguire le operazioni necessarie.
Se la connessione va a buon fine, attraverso i pulsanti dell’interfaccia grafica ed il solito modello a eventi di Windows, l’utente può richiedere due diverse operazioni: ‘l’Aggiornamento della sua tabella locale’ contenente lo stato delle prenotazioni e la ‘Richiesta di effettuare una nuova prenotazione’. Il funzionamento di entrambe le operazioni è intuibile osservando i seguenti messaggi, che sono parte del protocollo standard di comunicazione di un Client:
Con il Manager
GETCONN: Messaggio con cui un Client richiede al Manager l’indirizzo del Server più scarico. In ricezione, a seguito di questo messaggio, riceve dal Manager l’indirizzo opportuno, oppure scade un Time – Out.
Con il Server
RICHIESTA: Messaggio con cui un Client richiede il DB aggiornato ad un Server. In ricezione, a seguito di questo messaggio, riceve dal Server copia del suo DB attuale che il Client pubblicherà.
DB: Messaggio con cui un Client richiede di effettuare una prenotazione al Server. Per DB si intende una tabella che contiene i record della prenotazione. In ricezione, a seguito di questo messaggio, riceve dal Server copia del suo DB attuale (che sarà ovviamente aggiornato con la nuova prenotazione), in caso di esito positivo, oppure un Messaggio con l’indicazione dell’errore verificatosi che il Client pubblicherà, in caso di esito negativo.
Il MANAGER è stato implementato come servitore sequenziale, riceve richieste sotto forma di datagrammi su un’unica porta per tutti (Clienti e Servitori) e le serve una alla volta. E’ stato scelto di lavorare su UDP in quanto le sessioni di interazione sono sempre molto brevi e devono essere il più possibile veloci. Un diagramma di flusso rappresentativo della sua attività è il seguente:
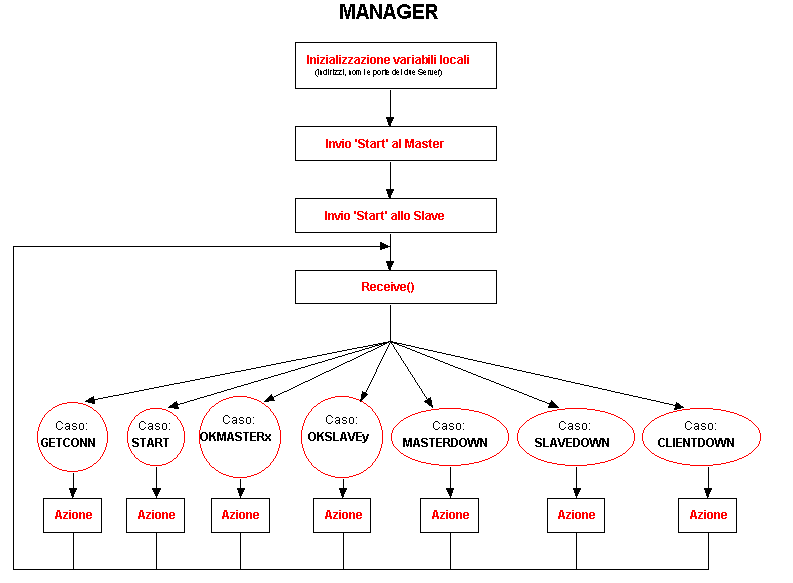
Le variabili locali del Manager sono costituite da :
InetAddress AddServer[2] // Indirizzi Server
String nomeServer[2] // Nomi logici Server
Int contServer[2] // Numero connessioni attualmente servite dai Server
Int numServerUP // Indicazione dei Server attualmente attivi e funzionanti 0-Nessuno 1-ServerMaster 2-ServerSlave 12-Entrambi
Dopo la fase di inizializzazione di dette variabili e la creazione di una Socket a Datagrammi di ascolto sulla porta locale 2345, il Manager invia sia al Master che allo Slave, sulle rispettive porte, un Datagramma con il messaggio di ‘Start’. Se i Server sono accesi, appena riceveranno il pacchetto, risponderanno al master con una indicazione della loro presenza e della loro attuale attività. Vediamo in rassegna tutti i messaggi che possono far parte di un corretto protocollo e le azioni conseguenti che il Manager intraprende:
GETCONN: Messaggio con cui un Client richiede l’indirizzo del Server a cui è più opportuno che si colleghi. Alla ricezione, il Manager controlla il numero dei Server attivi. Se uno solo è attivo risponde necessariamente con il corrispondente indirizzo, mentre se entrambi sono attivi con quello che ha un numero di connessioni aperte ed in servizio minore (controlla contServer).
START: Messaggio con cui un Server segnala che si è attivato, che diventa da questo momento disponibile. Alla ricezione, il Manager controlla l’indirizzo di provenienza per stabilire quale Server abbia fatto la segnalazione, e aggiorna opportunamente il suo stato in numServerUP. Risponde se ha esito positivo con un messaggio di ’OK’.
OKMASTERx: Messaggio con cui il Server Master segnala che è attivo, e sta servendo un numero di connessioni pari a x (è solitamente la risposta del Master al messaggio di ’Start’ del Manager). Alla ricezione, il Manager aggiorna opportunamente il suo stato in contServer[1]. Non invia conferma della corretta ricezione del messaggio.
OKSLAVEy: Messaggio con cui il Server Slave segnala che è attivo, e sta servendo un numero di connessioni pari a y (è solitamente la risposta dello Slave al messaggio di ’Start’ del Manager). Alla ricezione, il Manager aggiorna opportunamente il suo stato in contServer[2]. Non invia conferma della corretta ricezione del messaggio.
MASTERDOWN: Messaggio con cui lo Slave segnala che il Server Master è caduto. Si accorge della caduta del Master dal momento che ha con questo una connessione permanente. Alla ricezione, il Manager aggiorna opportunamente il suo stato in numServerUP e riazzera contServer[1]. Non invia conferma della corretta ricezione del messaggio.
SLAVEDOWN: Messaggio con cui il Master segnala che il Server Slave è caduto. Si accorge della caduta dello Slave dal momento che ha con questo una connessione permanente. Alla ricezione, il Manager aggiorna opportunamente il suo stato in numServerUP e riazzera contServer[2]. Non invia conferma della corretta ricezione del messaggio.
CLIENTDOWN: Messaggio con cui il Server corrispondente segnala che un suo cliente ha chiuso la sua connessione perché ha terminato od è caduto. Alla ricezione, il Manager controlla l’indirizzo di provenienza per stabilire quale Server abbia fatto al segnalazione e aggiorna opportunamente il suo stato in contServer. Non invia conferma della corretta ricezione del messaggio.
REALIZZAZIONE DELL’ESEMPIO APPLICATIVO
L’intero esempio è stato implementato utilizzando come linguaggio di programmazione Java1.2. L’interfaccia grafica è stata realizzata mediante le Java Swing.
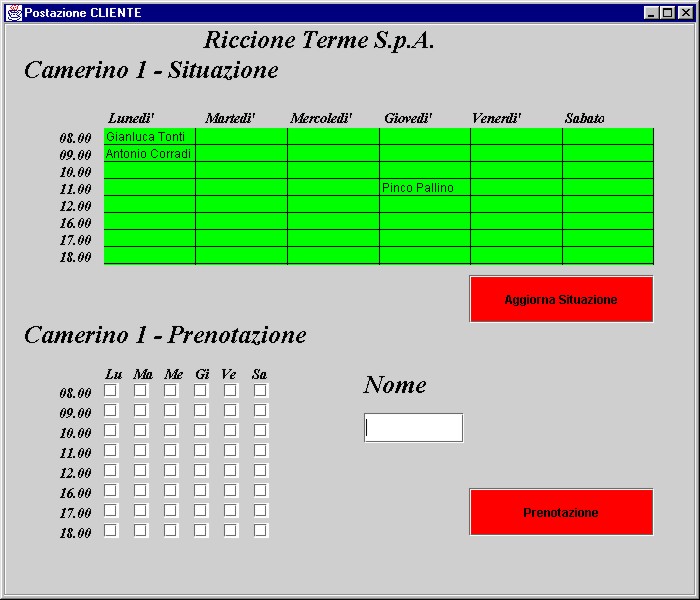
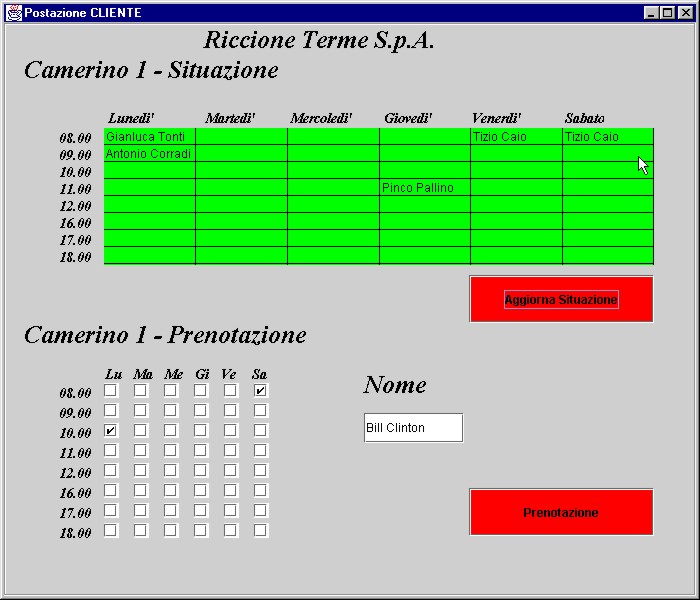
Questa è una ipotetica situazione che si presenta all’AVVIO. L’operatore ha visibilità del DB che il Client ha ricevuto per la sua connessione ad un Server. A questo punto, dopo aver inserito il nominativo del cliente nel campo di Testo , settato le CheckBox sugli orari e giorni che desidera e premuto il bottone ‘Prenotazione’, tenterà di prenotare il cliente.
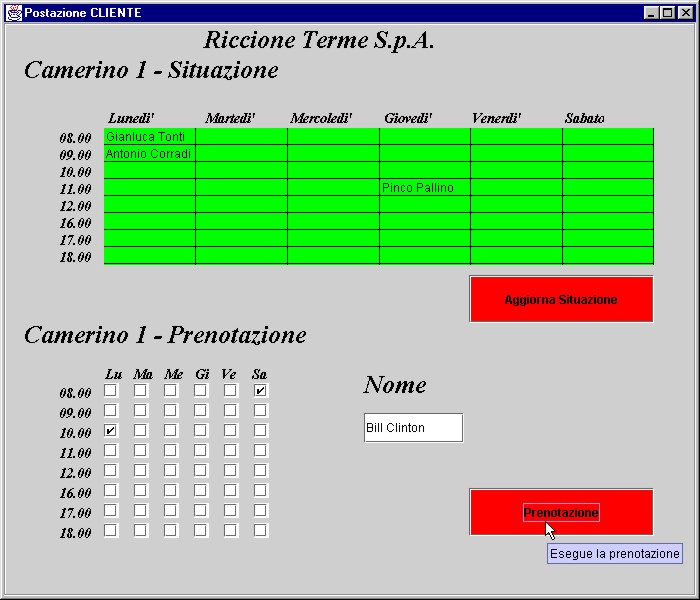
Nel caso in cui la prenotazione non sia effettuabile perché nel frattempo un altro Client ha già occupato una delle Fascie desiderate, compare un Messaggio di errore di questo tipo, altrimenti viene aggiornata la tabella a conferma dell’avvenuta prenotazione.
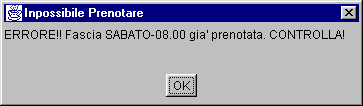
Per verifica dell’errore l’operatore richiede con ‘Aggiorna Situazione’ il DB attuale e verifica che effettivamente c’è una prenotazione effettuata per il giorno di Sabato alle 8:00 dal sig. Tizio Caio. Questa prenotazione, ovviamente, sarà stata effettuata da un altro Client tra la connessione del nostro esempio e la pressione del tasto ‘Prenotazione’.
Per quanto riguarda l’implementazione dei due Server e del Manager, invece, questi non possiedono una interfaccia grafica ma inviano su Standard Output una serie di Stringhe che riportano sequenzialmente le principali operazioni che vengono effettuate.
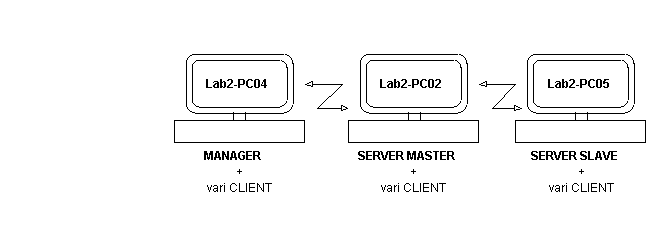
I Test in LAB2 sono stati effettuati utilizzando 3 workstation del laboratorio nel modo qui rappresentato:
Per quanto riguarda le prove utilizzando pochi Client connessi e l’interfaccia grafica standard non si sono registrati problemi. I tempi di risposta sono più che accettabili e i vari casi di simulazione di guasto di un componente tra i server e il master (da me provocato con l’’abort’ del processo) hanno comunque permesso una corretta continuità di servizio. Queste prove le ho effettuate con un massimo di 6 Client ed i tempi di risposta sono stati i seguenti:

I tempi sembrano lunghi, in realtà sono buoni perché misurano la connessione completa, compresa la creazione del processo Client, la visualizzazione dell’interfaccia grafica (che richiede 3-4 secondi circa) e la ricezione dal Server della tabella corrente da visualizzare. I tempi con tentativi Statici si allungano perché il Cliente aspetta circa 3 secondi il Manager prima che il Time-Out scada e possa proseguire. Una volta che si è stabilita la connessione le risposte arrivano pressoché immediatamente. Si nota un delta molto grande tra i valori a parità di lavoro eseguito (10 secondi tra i valori min e MAX), anche in prove eseguite a distanza di pochi secondi l’una dell’altra: a mio parere ciò è dovuto a situazioni di carico molto variabile della rete del LAB2.
Ho cercato di collassare il sistema inserendo un numero di Client consistente, maggiore del normale numero di terminali di cassa attualmente impiegati nello stabilimento termale. Per fare ciò ho creato un’applicazione Java (ClientePool) che mi genera un insieme di Client in numero che gli posso passare come argomento. Questi Client non sono altro che Thread indipendenti che tentano la connessione nella modalità solita, ma senza creare alcuna interfaccia grafica ed appena ricevono un DB in risposta da un Server terminano la loro esecuzione. Al termine su Standard Output viene visualizzata la situazione riepilogativa, con il numero di connessioni stabilite per Server e il numero di quelle, tra queste, effettuate in mod. STATICA. Provando con 50 Client contemporaneamente ho potuto riscontrare la difficoltà che il Manager incontra nel rispondere sequenzialmente a tutte le richieste contemporanee di un indirizzo di connessione da parte dei Client. Inizialmente avevo impostato il tempo di attesa di un Client prima di considerare ‘morto’ il Manager in 1 secondo (con la primitiva SetSoTimeOut()) ma ho dovuto innalzare a 4 secondi questa soglia affinché il Manager possa servire in tempo utile un numero per me ragionevole di richieste dei Client. Sottolineo comunque nuovamente, come può confermare lo specchio riassuntivo, che prove anche a distanza di pochi secondi hanno dato esiti notevolmente differenti a riprova che tutto dipende, oltre dal carico di lavoro dovuto all’applicazione, anche dal carico della rete!
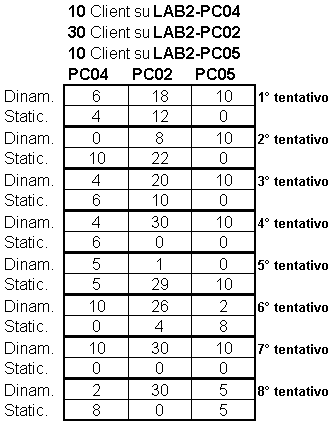
Il bilanciamento del carico risulta ottimale quando, ovviamente, tutte le connessioni dei Client vengono effettuate Dinamicamente, ossia 50% su un Server e 50% sull’altro. Nel caso in cui alcune connessioni avvengano in modalità Statica accade che:
Per fare fronte a ciò ho aggiunto una nuova comunicazione di protocollo:
Dopo un numero di contatti che il Manager ha da parte dei Client, superiore ad un intervallo definito dal System Manager, il Manager manda un segnale di ‘Start’ sia al Master che allo Slave e si aspetta quindi da questi la solita risposta di protocollo (‘OKMASTERx’/’OKSLAVEy’) con l’indicazione in x e y del numero corretto di connessioni aperte sui Server, che permetterà al Manager di aggiornare ‘una tantum’ opportunamente la propria situazione.