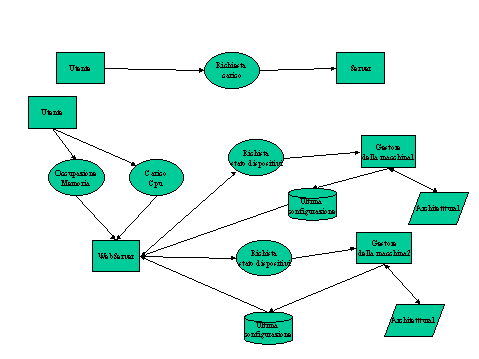
 In questa sezione vengono mostrati i diagrammi di flussi dei dati per alcune operazioni principali. Si è scelto di utilizzare più grafici per non appesantire di troppe informazioni un grafico.
In questa sezione vengono mostrati i diagrammi di flussi dei dati per alcune operazioni principali. Si è scelto di utilizzare più grafici per non appesantire di troppe informazioni un grafico.
DOCUMENTO DI SPECIFICA
DEI REQUISITI
Monitor del carico macchina
Tesina Reti di calcolatori
a cura di
Gabriele Tinti
versione 2.0
18 dicembre 1999
INDICE
INTRODUZIONE
In questo documento si formalizzeranno i prossimi passi di sviluppo del progetto, in modo particolare si darà una visione più dettagliata dei requisiti così come sono emersi dal colloquio tra il sottoscritto e il Prof. Corradi.
Dopo una breve descrizione del problema, nel capitolo secondo si daranno alcuni modelli del sistema, mentre nel terzo si definiranno i requisiti. Il quarto capitolo darà una breve panoramica di un possibile sviluppo futuro del sistema.
Si sarebbe voluto inserire un breve glossario con le parole significative, ma si è pensato di allegarlo ad un prossimo documento quando in fase di progettazione si delineeranno meglio gli strumenti di sviluppo.
Descrizione del problema
Scenario:
L'applicazione che si va a specificare si occupa del reperimento dello stato di un calcolatore, in termini di occupazione della CPU e della stato della memoria.
Lo scenario in cui lavora questo genere di applicazione è il seguente: un cliente vuole inviare un certo task ad un calcolatore richiede ad un particolare gestore di sapere lo stato del calcolatore. L'ambiente è un ambiente Internet.
Pertanto sarà necessario lo sviluppo di un server che riceva la richiesta da un web-client e esamini la macchina sottostante.
Applicazione Server
Il Server sarà diviso in due parti: Il WebServer che si occupa della comunicazione con il client attraverso il web, e il Gestore dello stato della macchina.
Il WebServer per gestire più chiamate sarà multithread e dovrà avere anche una politica di comportamento affidabile in caso di perdita di messaggi e problemi della rete. Quest'ultimo requisito non è fondamentale in questo contesto pertanto si dovrà risolvere in modo molto semplice, ad esempio demandando la gestione al client.
Il WebsServer sarà scritto in Java per avere maggiore flessibilità verso il Web.
Da notare che va previsto che il server a cui si è connessi sia integrato in una rete costituita da più macchine (vedi LAN) e quindi il server dovrà interrogare tutte le macchine per trovare la più libera.
Il Gestore, che si occuperà del reperimento dello stato della macchina, dovrà essere scritto ad hoc per l'architettura di cui si fa riferimento, questo è un limite alle portabilità di Java. Il gestore sarà unico per ogni architetturà e sarà compito del WebServer di coordinare tutti i gestori collegati ad esso.
Applicazione Client
Il client per comunicare con il server utilizzerà TCP/IP e sarà un applet, in modo da poter essere utilizzato su un qualsiasi browser.
La politica per la perdita dei messaggi sarà affidata al cliente.
Comunicazione
La comunicazione tra server e client utilizzerà un protocollo con connessione, che è quello standard in ambiente Internet.
MODELLI DEL SISTEMA
Il sistema è sviluppato in modo client/server ed orientato ai dati e alle prestazioni di un sistema. La gestione della concorrenza è risolta nel demandare al server tutte le operazioni di reperimento delle informazioni.
Si è allegato un unico modello di tipo DataFlow, in quanto non ci sono dei sistemi informativi in questo tipo di applicazione da giustificare la modellazione Entity-Relationship.
L'architettura presentata è a tre livelli: un client che richiede ad un server un servizio di prelevamento dello stato (un server Web), e un gestore che si occupa di prelevare il suo stato.
Osserviamo, che non è stata presa in considerazione la notazione basata sul modello Z perché si è notato che il costo in termini di tempo che avrebbe portato l’utilizzo di tale notazione non era giustificato dal tipo di applicazione considerata. In prima analisi non è sembrato opportuno nemmeno utilizzare un modello Rete di Petri, in quanto l'applicativo non sembra richiederne la necessità.
Modello Data Flow.
In questa sezione vengono mostrati i diagrammi di flussi dei dati per alcune operazioni principali. Si è scelto di utilizzare più grafici per non appesantire di troppe informazioni un grafico.
Si nota che di fatto il cliente farà solo due richieste al Server che è un WebServer, dopodiché quest'ultimo interrogherà un gestore che si occupa di tenere sotto controllo l'architettura su cui lavora. L'identità del deposito "Ultima configurazione" in questa fase di studio non è ancora chiara e definita, in quanto non si sa come verrà implementato, è chiaro che il gestore dovrà passare in un qualche modo l'informazione che ha trovato.
DEFINIZIONE E SPECIFICA DEI REQUISITI FUNZIONALI
Requisiti funzionali rispetto al Cliente:
|
Richiedi stato CPU |
Manda una richiesta al server per sapere lo stato della CPU. |
|
Richiedi stato della memoria |
Manda una richiesta al server per sapere lo stato della memoria. Restituirà lo stato della memeria inserito in un oggetto Risultato |
Requisiti funzionali rispetto al WebServer:
|
Richiedi stato macchina a un gestore |
Il server notificherà al Gestore la richiesta di avere informazione sull'architettura. |
|
Invia informazioni richieste |
Invia tutte le informazioni ottenute al client che ne ha fatto richiesta, le informazione sono contenute in un oggetto Risultato. |
Requisiti funzionali rispetto al Gestore:
|
Costruisci lo stato della cpu |
Costruisci lo stato della CPU, in termini di percentuale di utilizzo del processore. |
|
Costruisci lo stato della memoria |
Interroga l'architettura sottostante per trovare lo stato di occupazione della memoria. |
|
Invia lo stato dell'architettura |
Costruisce un oggetto di tipo Risultato con le informazioni di basso livello ricevute, e lo invia al WebServer che ne ha fatto richiesta. |
|
Registrazione della disponibilità al servizio |
Registra al WebServer la propria di sponibilità a fornire un servizio di stato della propria architettura.. |
EVOLUZIONE DEL SISTEMA
Il lavoro che si va a progettare è rivolto alla integrazione in un sistema esistente di funzionalità di prelevamento dello stato della macchina rendendole disponibile in ambiente web. L'obiettivo di questo lavoro è di sviluppare un significativo sottoinsieme di requisiti in modo da poter in modo efficiente interrogare una macchiana per il suo stato.
Un possibile sviluppo potrà essere rivolto nella assegnazione di un task alla macchina più "scarica". Una volta trovata la macchina più scarica il cliente attraverso il server gli assegnerà un sezione di lavoro.
CONCLUSIONE
In questo documento si sono illustrati i requisiti che il sistema possiede e si sono mostrate le principali funzionalità che verranno implementate.
Nel prossimo documento "Documento di specifica di progetto" si metteranno in luce gli aspetti progettuali del lavoro. Si presenterà l'ambiente di sviluppo scelto, la metodologia di sviluppo adottata, una sezione riguardante la specifica di sviluppo e una sezione riguardante la documentazione delle classi, per la quale ci si appoggerà all'ambiente di rappresentazione UML.