
Progetto per il Corso di Reti di Calcolatori - A.A. 1999-2000
File Server Distribuito
di
Silvia Ruvinetti
![]()
Specifiche:
Progetto:
![]() Struttura di un server generico
Struttura di un server generico
![]() Gestore del server per rete con topologia ad anello
Gestore del server per rete con topologia ad anello
![]() Gestione locale del name server
Gestione locale del name server
![]() Gestione globale del name server
Gestione globale del name server
![]() Inserimento di una nuova associazione
Inserimento di una nuova associazione
![]() Cancellazione di una associazione
Cancellazione di una associazione
![]() Comando di lista file nei server
Comando di lista file nei server
![]() Gestore per l'inserimento di nuovi nodi nella rete
Gestore per l'inserimento di nuovi nodi nella rete
![]()
Descrizione del sistema
Si vuole creare un file server distribuito di piccole dimensioni, ovvero un sistema costituito da processi residenti su nodi diversi che cooperano tra loro al fine di rendere disponibile ad un utente esterno l'insieme dei files locali ad ognuno.
I diversi server sono connessi alla rete Internet, non si fanno quindi ipotesi su quale sia la topologia di connessione a livello di rete, ma a livello di applicazione si definisce una struttura ad anello virtuale: ognuno ha un predecessore ed un successore. Questa scelta è giustificata dal piccolo numero di partecipanti. Si vuole che i diversi server comunichino tra loro in modo affidabile, si collegano quindi tramite connessioni permanenti che usinoTCP come trasporto.
Interazione degli utenti esterni con il sistema
Le operazioni possibili per gli utenti sono la richiesta di download di un file e la richiesta della lista completa dei file scaribili dal server.
Le richieste vengono inoltrate per mezzo di messaggi che sfruttano UDP come trasporto, quindi non vi è quindi certezza che giungano a destinazione.
Il client fissa un timeout, scaduto il quale, se non ha ricevuto alcuna risposta dal server (v. oltre: invio codice di errore, trasferimento file ), inoltra nuovamente la richiesta.
La semantica della azione corrispondente sul server è di tipo at least once: a seguito di ritrasmissioni della stessa richiesta, vengono ripetute le stesse azioni. La gestione delle possibili ritrasmissioni dello stesso file grava sul cliente.
La sintassi dei comandi è la seguente:
Download di un file: 200 <nome logico file da scaricare>
Lista dei files esportati dal server: 300
E' previsto che il server risponda con codice di errore nel caso in cui si verifichi una delle seguenti situazioni:
Evento
Codice
File non presente
1500
Comando inesistente
1200
Nome logico scorretto*
1300
Sintassi comando scorretta
1400
Anche il codice di errore viene inviato usando una comunicazione non affidabile, non vi è dunque certezza che il cliente lo riceva, ma di questo non ci si preoccupa.
Per il trasferimento delle informazioni da server a client si usano connessioni TCP che vengono create appositamente; per il trasferimento di ogni file la connessione viene creata e poi distrutta ( connessione by-need ); per semplicità si dispone che il client utilizzi lo stesso numero di porta sia per la socket usata per l'invio della richiesta (porta UDP) che per la socket di ricezione del file (porta TCP): così facendo il server quando riceve la richiesta conosce la porta cui è agganciato il processo che aspetta il download.
*: è possibile definire la grammatica da cui devono essere generati i nomi dei file inseriti: nella versione implementata l'unica caratteristica che si è imposta è che i nomi non superino i 50 caratteri.
Inserimento di nuovi server
Si suppone che sia possibile aggiungere nuovi nodial sistema mentre questo è funzionante:i nuovi server che vogliono accedervi fanno una richiesta ad uno dei server che già vi appartengono. Il punto di inserimento del nuovo server viene negoziato tra quelli già presenti: viene prescelto come predecessore il nodo che dista da questo il minor numero di passi.
Per l'invio della richiesta il nuovo server usa un trasporto non affidabile (UDP): fissa quindi un timeout, scaduto il quale, la richiesta viene nuovamente inviata; la conseguente azione, nei server dell'anello, segue una semantica di tipo at least once: il nuovo server dovrà quindi gestire correttamente la possibilità di essere contattato più volte per dare il via alla procedura di inserimento.
Ipotesi di guasto
Come ipotesi di guasto sulla caduta dei nodi si assume che non possano cadere contemporaneamente due nodi consecutivi nell'anello virtuale.
A seguito della caduta di un nodo si ha la perdita di tutti i messaggi che questo ha ricevuto, ma che non è riuscito a ritrasmettere: questa possibilità dovrà essere tenuta in considerazione nella progettazione dei protocolli che regolano le diverse attività del sistema.
![]()
Struttura del sistema
Volendo andare verso al riusabilità del software e l'estendibilità, si è cercata una soluzione che non fosse cablata sulle specifiche del problema, ma che fosse possibile, previa specializzazione, utilizzare in tutta una classe di problemi (in questo caso problemi che coinvolgano la collaborazione di diversi server).
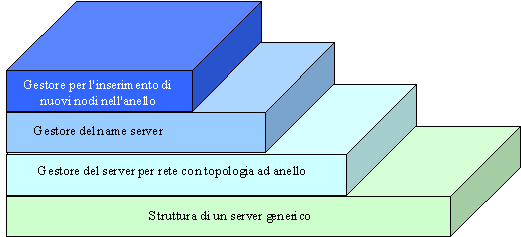
La figura riportata sopra indica come si è pensato di realizzare il sistema strutturandolo su più livelli: ogni livello sfrutta le funzionalità fornite dal precedente e ve ne aggiunge delle nuove che rende disponibili a quelli successivi.
Struttura di un server generico
Si è realizzata per i server una struttura indipendente sia dalla topologia della rete ( intesa a livello applicativo ) su cui andranno ad operare che dalle politiche con cui questa verrà gestita: in tale struttura i singoli server hanno solo il compito di ricevere, mettere in esecuzione e spedire dei comandi.
Tali comandi, sono oggetti, che vengono passati attraverso la rete e che contengono al loro interno le operazioni che devono svolgere. Quindi anche la propagazione dei comandi tra i diversi server avviene per "iniziativa" dei comandi stessi che, nel caso in cui ve ne sia la necessità, forniscono al server una copia di loro stessi che questi si incarica di spedire su tutti i canali di uscita.
Questa struttura è quindi indipendente dall'insieme di operazioni che su di essa opereranno.
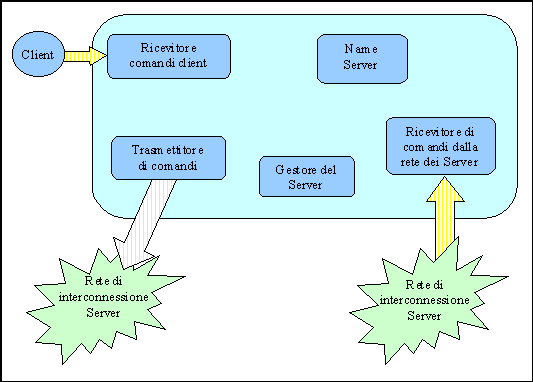
Breve descrizione dei componenti:
Name Server:è previsto che ogni server abbia un name server; è stato implementato come una tabella di coppie ( nome fisico, nome logico ) e su cui sono definite tutte le operazioni per operarvi.
Gestore del server: è il componente che coordina tutti i rimanenti ed in cui, nelle versioni specializzate, andranno inserite le politiche di gestione del server.
Trasmettitore di comandi: si occupa della trasmissione di un comando su tutte le socket di uscita. Nel caso in cui una delle socket su cui deve scrivere cada, notifica l'evento al gestore del server inviandogli anche il comando che non è riuscito a trasmettere: sarà questo che, in funzione della politica che implementa, deciderà come comportarsi.
Ricevitore di comandi dalla rete dei Server: ogni socket di ingresso ha un thread di ascolto che si occupa della ricezione dei comandi e dell'avvio dell'esecuzione di questi.
Nel caso di caduta di una delle socket, notifica l'evento al gestore del server.
Ricevitore di comandi dal client: ha una struttura diversa dal precedente in quanto dal client si ricevono linee di comando in formato testo, non oggetti di tipo comando; è composto quindi da un piccolo interprete che, una volta riconosciuto un comando lecito, genera il corrispondente comando in forma interna (ovvero crea una nuova istanza della classe comando associata alla richiesta ricevuta), e lo mette in esecuzione.
Oss: anche la struttura di questo piccolo interprete è stata progettata in modo tale da non essere cablata sull'insieme di comandi fino ad ora gestiti. L'unica ipotesi di progetto è che i comandi siano identificati da un codice numerico. Si è creata una tabella in cui ad ogni codice numerico è stato associato il riferimento alla procedura che deve stabilire la correttezza del comando ed eventualmente metterlo in esecuzione. L'interprete quindi, una volta ricevuto il comando ne estrae il codice numerico, ricerca nella tabella la procedura corrispondente e la mette in esecuzione passando ad essa come parametro la stringa contenente il resto del comando. E' quindi sufficiente modificare la tabella ed aggiungere o togliere procedure di gestione per modificare l'insieme dei comandi gestibili.
Gestore del server per rete con topologia ad anello:
Volendo realizzare un anello virtuale, si definise che ogni server abbia un solo successore ed un solo predecessore.
E' necessario che a seguito della caduta di un nodo, la rete si modifichi andando a ripristinare l'anello.

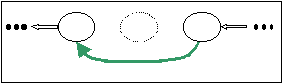
Al fine di ottenere questo, quando un nodo si accorge che il successore è caduto, instaura una connessione con il suo successore di secondo livello.
Si dispone poi che al momento del riavvio del nodo caduto, questo si vada a reinserire nell'anello, ripristinando le connessioni, esattamente dietro il nodo che conosce come proprio successore. Il reinserimento avviene seguendo il seguente protocollo:
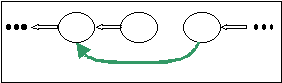
Quando un nodo caduto si riavvia, instaura una connessione con il nodo che era suo successore prima del crash.
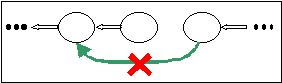
Il successore riconosce che il nuovo nodo è il predecessore caduto, rompe quindi la connessione che era stata instaurata con il predecessore di secondo livello.

Il predecessore del nodo riavviato sentendo che il proprio successore di secondo livello ha chiuso la connessione capisce che il proprio successore è tornato e crea quindi una nuova connessione con questo
La rete ha quindi nuovamente assunto la struttura originale.
Quando il nodo successore cade, prima del ripristino dell' anello, il trasmettitore di comandi si trova impossibilitato ad effettuare gli invii e notifica questo al gestore del server.
Per evitare di perdere messaggi, con questa topologia di rete, si è ritenuto necessario creare una coda in cui inserire tutti i comandi che non si sono riusciti a trasmettere; al momento del ripristino dell'anello, tutti i comandi qui contenuti vengono inviati al nodo che in quel momento è il successore.
Gestore del name server
Ogni nodo possiede una name server che è costituito da una tabella in cui sono presenti le associazioni tra nome fisico e nome logico di ognuno dei file scaricabili dal File Server.
Considerando che il numero di files gestiti non è troppo elevato, si è ritenuto conveniente replicare su ogni nodo l'intera lista dei nomi logici resi disponibili, per poter quindi ottimizzare le risposte a clienti che richiedono files non presenti, non andando così ad occupare inutilmente la rete, e di quelli che richiedono l'intera lista dei files.
In ogni tabella, quindi, sono presenti le associazioni dei files locali al nodo, a cui ad ogni nome logico corrisponde quello fisico, e quelle relative ai files presenti sugli altri nodi, a cui, per poterli distinguere da quelli locali, al nome fisico è associato una costante che indica che il file è esterno.
In sostanza per i files non locali al nodo non si ha alcuna indicazione nè del nodo in cui sono presenti, nè del nome fisico che hanno su questo.
Gestione locale del name server.
E' necessario garantire che gli inserimenti e le cancellazioni eseguiti su un name server siano persistenti, ovvero non sia possibile che a causa di un crash del sistema vengano persi.
E' quindi necessario che ogni operazione effettuata sulla copia del name server attiva in memoria, venga salvata anche su disco.
Non volendo, ad ogni operazione, andare ad agire sulla copia dell'intero name server sul disco, tutte queste registrazioni vengono effettuate su di un file log.
Al momento dell'avvio di un nodo a seguito di un crash, dopo aver ricaricato la copia fredda del name server presente su disco, si andranno ad eseguire nuovamente, e nello stesso ordine, tutte le operazioni indicate sul file log: si otterrà così nuovamente una copia aggiornata.
Al momento del salvataggio su disco della copia in uso del name server, il file log viene cancellato.
Le registrazioni nel log sono terne in cui viene indicato:
Nome logico da inserire
Gestione globale del name server
Le diverse operazioni di inserimento e cancellazione che si vogliono fare in un nodo, devono essere comunicate anche a tutti gli altri prima di poter divenire effettive (ovvero riconosciute valide in tutti i nodi). Questa comunicazione avviene tramite la trasmissione ai diversi nodi di richieste che hanno lo stesso formato delle registrazioni che si fanno sul log file.
Su ogni nodo c'è una tabella, nel seguito indicata come tabella delle proposte, contenente le diverse richieste inoltrate da quel nodo e non ancora effettive.
Oss: Anche per i dati di questa tabella si vuole garantire la permanenza a seguito di crash di sistema: si utilizza un metodo del tutto analogo al precedente.
Inserimento di una nuova associazione
E' necessario garantire la coerenza dei diversi name server a seguito di inserimenti.
Per rendere effettivo l'inserimento, una proposta deve fare un giro intero della rete: a quel punto il nodo sa di aver dato la notifica a tutti gli altri partecipanti, quindi scrive nel proprio name server la nuova associazione e toglie dalla tabella delle proposte l'entry relativa a questa richiesta.
Gli altri nodi invece hanno un comportamento diverso: alla ricezione del messaggio di inserimento aggiornano subito il loro name server locale e propagano la richiesta; il nodo che vuole inserire il file è quindi l'ultimo a fare l'aggiornamento.
Fino a quando la richiesta non ha fatto tutto il giro dell'anello ci sono quindi inconsistenze tra i diversi name server della rete.
Questo comporta che la richiesta di un client per il nuovo file inserito, inoltrata ad uno server in cui questo è già presente, possa essere passata tra i diversi server fino ad incontrarne uno in cui l'entry non è presente: in questo caso si ha quindi un peggioramento delle prestazioni. Questa comunque è una situazione transitoria.
Vista la possibilità di perdita di messaggi, nel nodo che inserisce la richiesta viene fissato un time-out: se alla scadenza di questo la richiesta non ha ancora fatto un giro, viene nuovamente inoltrata. Considerando le caratteristiche della rete creata, non si pone limite al numero di ritrasmissioni, questo in base alle seguenti considerazioni.
Le cause dello scadere del time-out possono essere due:
Un messaggio viene perso solo se cade il nodo che in quel momento lo ha ricevuto: è poco probabile che nelle diverse ritrasmissioni cadano sempre i nodi che hanno quel messaggio, quindi, ragionevolmente, questo protocollo si concluderà in un tempo finito.
Un discorso diverso è invece quello di ritardi nella risposta a causa della congestione della rete: tutta la struttura creata si appoggia sulla rete Internet ed è quindi possibile che il trasferimento di messaggi tra due nodi sia molto rallentato a causa, ad esempio, della congestione di un router, che è qualcosa quindi di indipendente da questa applicazione. Per contemplare questo secondo caso, il time-out viene ridimensionato ad ogni ritrasmissione successiva.
Bisogna considerare anche l'eventualità che il nodo proponente cada: per evitare che la sua richiesta continui a girare per l'anello (nessun altro nodo la riconosce come propria e quindi continua a propagarla), si impone che ogni nodo faccia un controllo aggiuntivo: chi riceve una richiesta inoltrata dal proprio precessore in quel momento caduto, la scarta.
Problemi
E' possibile che due nodi cerchino di inserire "contemporaneamente" lo stesso nome logico (entrambi mettono sulla rete la richiesta prima che arrivi la notifica dell'altro): bisogna quindi fare in modo che solo la richiesta di uno dei due abbia successo.
Per i restanti nodi questo non costituisce un problema: non hanno memoria del nodo mittente per le entry relative a file non locali, quindi anche vedendo passare più volte la stessa richiesta la interpretano come ritrasmissioni da parte dello stesso nodo. Bisogna quindi occuparsi solo di quanto accade nei due nodi interessati.
Si possono presentare diversi casi (si indicano con X e Y i due nodi):
Come soluzione a questo problema, si è deciso di creare una funzione dell'indirizzo IP e del nome logico che si vuole inserire, che non possa dare lo stesso valore per IP diversi, e calcolarla sia per X che per Y: se f(x) < f(y) allora viene scartata la richiesta di X, altrimenti quella di Y.
Se X scarta la propria richiesta, deve toglierla dalla propria tabella delle proposte ed aggiornare il proprio name server inserendo la nuova entry: come nome fisico inserirà la costante che identifica il nuovo file come non locale.
Chiaramente, come è necessario che accada, le caratteristiche della funzione f fanno in modo che quando la stessa situazione si presenta nel nodo Y si scarti la stessa richiesta (viene ricalcolata sugli stessi valori).
Oss: Implementando f si è cercato di renderla giusta non introducendo priorità fisse associate ai nodi: dati due nodi A e B non sempre il nodo A è favorito al nodo B ma ciò dipende dal terzo dei tre parametri in gioco: il nome logico del file.
Cancellazione di una associazione
Anche in questo caso si utilizza una soluzione analoga alla precedente, ma questa volta la cancellazione dal name server del nodo proponente, viene eseguita subito, prima della propagazione della richiesta (il nodo non vuole più rendere disponibile un file da subito).
I nodi della rete che vedono la richiesta, aggiornano il proprio name server ed a loro volta la propagano.
Esattamente come prima si fissa un time-out sul nodo che fa la cancellazione allo scadere del quale avviene la ritrasmissione.
Problemi
In questo caso non si hanno i problemi visti prima per 2 nodi che facciano 2 cancellazioni contemporanee, siccome solo chi possiede un file localmente può proporre la cancellazione del nome logico, ma si può avere un problema diverso dovuto alla possibile perdita del messaggio di cancellazione.
Il nodo X che tra i suoi file locali ne ha uno associato ad un certo nome logico lo vuole cancellare, mette quindi la richiesta sulla rete. Quando il nodo Y la riceve, aggiorna il proprio name server e la propaga: da questo momento in poi il nodo Y può inserire una nuova richiesta per l'inserimento di un file con il nome logico appena cancellato. Se il messaggio di cancellazione viene perso, la richiesta di inserimento del nodo Y arriva al nodo X prima che la cancellazione sia effettiva: il nodo X deve cancellare dalla sua tabella la richiesta di cancellazione (evitando così nuova ritrasmissioni) ed aggiornare il proprio name server.
Se, a causa di una ritrasmissione avvenuta prima che X la eliminasse, la richiesta di cancellazione giungesse nuovamente ai nodi Y ed X, questi dovranno scartarla. Se l'inserimento non è ancora effettivo, il nodo Y vedrà che nella propria tabella delle proposte è presente la richiesta di inserimento, mentre se lo è già, dal name server vedrà che il file fisico associato al nome logico è locale.
Aggiornamento del name server di un nodo dopo la caduta
E' necessario che un nodo caduto, al momento del riavvio aggiorni il proprio name server rendendolo coerente con quello degli altri prima di ritornare ad essere operativo. Per fare questo, quando un nodo si accorge della caduta del suo successore, deve creare una tabella in cui inserire tutte le richieste di inserimento e cancellazione che riceve, ovvero tutte le richieste relative ad operazioni che cambino lo stato del name server. Al momento del ritorno del successore, questa tabella viene ad esso inviata ed esso elabora ordinatamente le richieste come avrebbe fatto normalmente, evitando però la propagazione( sono tutte richieste che sono state già propagate grazie al meccanismo di ripristino dell'anello a seguito della caduta di un nodo).
Alla fine di questa fase, se la tabella delle proposte del nodo contiene ancora delle richieste, queste dovranno essere inoltrate.
Comando di download
Quando un server riceve una richiesta di dowload, controlla che il nome logico richiesto appartenga al name server; nel caso in cui questo non accada, lo notifica immediatamente al cliente specificando il codice di ritorno. Altrimenti, controlla che il nome fisico associato sia ad esso locale: se ciò accade crea una connessione con il client ed invia un messaggio di 50 byte contenente il nome logico richiesto e di seguito il file, in caso contrario passa la richiesta al proprio successore..
Se la richiesta compie un giro dell'anello, quando ritorna al server di affaccio, questo invia la risposta negativa al cliente e la scarta.
Oss: una richiesta compie un intero giro dell'anello se il nodo che possiede il file richiesto è caduto.
Comando di lista file nel server
Per come è stato strutturato il name server, il comando di lista viene risolto in modo molto semplice: il server a cui viene inoltrato apre una connessione con il client e gli invia la lista dei nomi logici contenuti nel proprio name server.
Oss: per quanto detto sopra (problemi nell' inserimento e nella cancellazione), il name server inviato potrebbe essere inconsistente.
Gestore per l'inserimento di nuovi nodi nella rete
E' necessario inserire un componente per l'ascolto delle richieste dei nuovi server. Si è usato un interprete con la stessa struttura dell'interprete per comandi client.
Un server che si vuole inserire nell'anello deve segnalarlo ad uno qualsiasi dei server già presenti; questo si occupa di inviare sulla rete una richiesta con cui determinare il miglior punto di inserimento per il nuovo server.
Ogni server che riceve questa richiesta calcola il numero di passi che lo separano dal nuovo server (tramite il comando 'tracert -d <IP new server' (versione per Windows)), e se questo numero è minore della migliore offerta fino ad ora fatta, inserisce il proprio indirizzo sulla richiesta e la propaga, altrimenti si limita a propagarla.
Oss: vista la possibilità di ritrasmisioni delle stesse richieste per non calcolare più volte le stesse distanze, ogni server mantiene una tabella, gestita come una coda FIFO, contenente gli indirizzi già risolti ed i relativi numeri di passi. Le entry della tabella non hanno una scadenza, vengono eliminate quando si hanno nuovi inserimenti con coda piena.
La richiesta contiene quindi l'indirizzo del server più vicino a quello nuovo ed il numero di passi che da questo lo separano.
Quando la richiesta ha fatto un giro dell'anello, contiene l'indirizzo del server migliore: si decide che il questo sarà il predecessore del nuovo server.
Solo i server che saranno in visibilità con il nuovo dovranno variare la loro conoscenza della rete, si è quindi ritenuto più efficiente, invece di sfruttare l'anello per la comunicazione dei messaggi del protocollo di inserimento, costruire una struttura a lato.
Essendo la modifica della struttura della rete una operazione critica, si è utilizzato un trasporto affidabile per la comunicazione dei dati. Su ogni server si è inserita una socket di ascolto tramite cui si costituiscono i canali di comunicazione necessari al protocollo di inserimento.
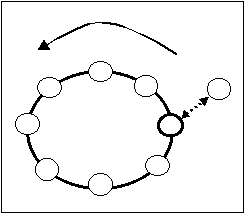
Dopo aver segnalato la volontà di entrare nell'anello, il nuovo server si mette in attesa di venire "contattato" dal server che si è determinato essere il migliore predecessore: questo si occuperà di renderlo operativo inviandogli tutte le informazioni di cui necessita, ovvero, una copia aggiornata del name server, le tabelle che gli permetteranno di aggiornare il proprio successore, se caduto, e tutte le informazioni che permettano ad esso di avere una corretta visione della parte di rete che deve conoscere.
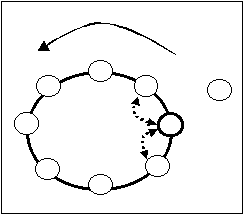
E' sempre su iniziativa di questo nodo che il resto della rete viene aggiornato in modo corretto, si incarica cioè di comunicare ai nodi interessati (quelli per i quali il nuovo server deve essere in 'visibità') i cambiamenti da effettuare.
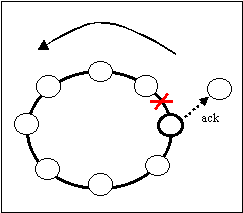
Quindi, avendo aggiornato lo stato della rete, rompe il collegamento con il vecchio successore e comunica al nuovo server che il resto della rete è pronta per il suo inserimento: grazie al meccanismo di ripristino dell'anello si costituisce la nuova struttura.
Il protocollo definito si vuole tenga presente la possibilità di caduta di nodi; si sono considerati i seguenti casi:
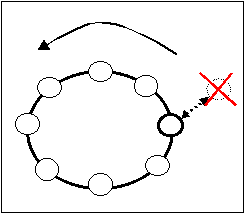
Caduta del nuovo server prima dell'inizio della procedura di inserimento:
Il nodo predecessore se ne accorge e l'operazione viene abortita. Una volta riavviato il nuovo server dovrà cominciare nuovamente la procedura di ingresso(segnalando la volontà di entrare nell'anello).
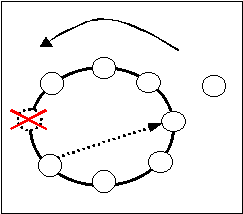
Caduta del nodo di affaccio della richiesta
Ci si accorge che la richiesta ha compiuto un intero giro dell'anello quando raggiunge il successore del nodo di affaccio: questo riconosce che il mittente della richiesta è il suo predecessore e che questo è caduto; si incarica quindi di contattare il miglior predecessore.
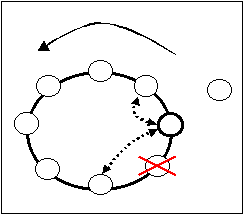
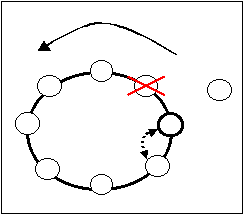
Caduta di uno dei nodi che saranno in visibilità con il nuovo server
Il problema in questo caso è fare in modo che al momento del ripristino del nodo caduto avvenga un aggiornamento della sua visione della rete che comprenda il nuovo server. Si sfrutta la coda dei comandi inserita per evitare di perdere messaggi durante il ripristino dell'anello: si mette il comando di aggiornamento della rete in cima a questa così al momento del reinserimento del nodo verrà trasmesso.
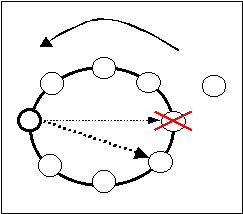
Caduta del nodo prescelto come predecessore
Ci si comporta come se il miglior predecessore fosse il predecessore del nodo in realtà prescelto (questo deve essere presente per le ipotesi di guasto fatte).
Test
Per monitare l'esecuzione dei diversi componenti, si è utilizzato il metodo dell'instrumentation code, ovvero si sono inserite nel codice delle istruzioni di stampa.
Si voleva però attivare o disattivare questi messaggi secondo necessità, ed in modo rapido.
Si è sfruttato il fatto che in Java gli "if" valutati su variabili final static sono valutati solo a tempo di compilazione e la traduzione in bytecode non avviene per le parti di codice relative alla condizione non verificata.
In funzione al grado di granularità che si voleva ottenere per i diversi componenti ( a.e. una variabile sola usata in tutto il componente, o più variabili per i diversi metodi ), si è quindi creato un insieme di variabili che si sono utilizzate per l'esecuzione di stampe "condizionate".
Per attivare o disattivare un insieme di messaggi (ad esempio quelli all'interno di uno specifico metodo) è quindi sufficiente settare a true il valore di una variabile e ricompilare il codice interessato (nell'esempio di prima quindi solo la classe contenente il metodo in esame).
Analisi delle prestazioni
Si sono fatte delle rilevazioni per vedere l'andamento del ritardo della risposta dei server al crescere del numero di clienti contemporaneamente presenti ( si sono considerati 5, 10, 15, 20 e 25 clienti; ogni cliente ha compiuto 10 richieste ), con anelli costituiti da 3, 4 e 5 server.
Come tempo di risposta si intende l'ampiezza, misurata in msec, della finestra temporale che intercorre tra l'invio della richiesta da parte del cliente e l'istante in cui il server instaura il collegamento per il trasferimento del file.
Si sono distribuite in modo il più possibile uniforme le richieste dei diversi clienti ai server: ogni client ha fatto richieste di download di file presenti alternativamente nel 1°, nel 2°, nel 3° server, etc. Si sono distribuiti in modo uniforme anche i nodi di affaccio per i diversi clienti.
Si sono fatte richieste solo per file che si sapevano essere presenti nel name server.
Il risultato di queste elaborazioni è contenuto nel grafico sottostante in cui vengono indicati i valori medi delle misurazioni fatte.
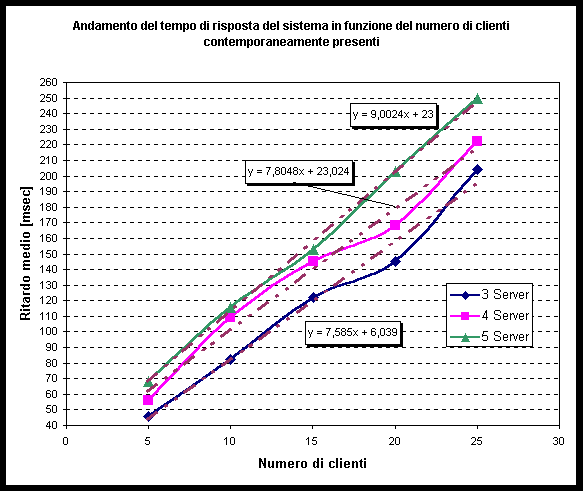
Dall'analisi dei risultati si può notare che nel range considerato la crescita del tempo di risposta è lineare rispetto alla crescita del numero di clienti.
Oss: per le rilevazioni si sono utilizzati dei PC del Lab3, collegati su lan, quindi con condizioni di rete quasi ideali; i dati raccolti non hanno quindi una valenza per quanto riguarda le prestazioni reali del sistema ma vogliono solo fornire una indicazione.