 |
L'obiettivo del lavoro era quello di progettare e implementare un sistema distribuito per la gestione di una tabella "globale", rappresentata da una "Rubrica" di corrispondenze stringhe-numeri.
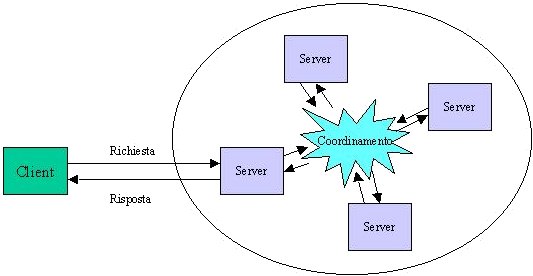
In particolare si voleva creare un servizio fornito da una serie di agenti (server), coordinati per offrire un servizio globale unico consistente nella possibilità di leggere/aggiungere/modificare entry da una tabella globale.
Quello che si voleva ottenere dal punto di vista del client è l'astrazione di risorsa unica (la tabella).
La tabella è, ovviamente, una risorsa distribuita, e quindi è necessario del coordinamento tra i server per mantenerne la consistenza.
|
Il sistema è fortemente dinamico, nel senso che la frequenza con cui i server si attivano e disattivano può anche essere alta. Questo implica, in un sistema che si coordina per offrire un servizio unico, una forte conoscenza reciproca delle condizioni di attivazione dei server.
I server possono essere disattivati in qualunque momento, sia in maniera volontaria che in maniera "sporca". Saranno gli altri agenti ad accorgersi del fatto e a coordinarsi di conseguenza.
Partizionamento/Replicazione dei dati
Abbiamo ipotizzato che le operazioni di lettura siano preponderanti rispetto alle operazioni di inserimento/modifica.
Ogni server possiede localmente una tabella, che contiene un sottoinsieme delle entry complessive gestite dal sistema.
L'insieme delle entry è partizionato e replicato.
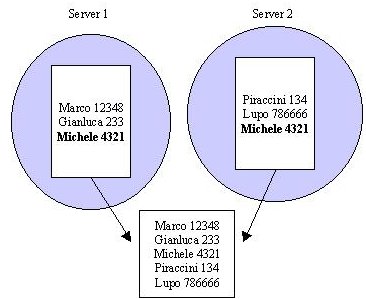 |
La replicazione avviene in maniera dinamica con un meccanismo di caching,
cioè: se un client effettua la richiesta di lettura per un dato ad un server
che non lo possiede, questi (il server) lo cerca dagli altri agenti, e se lo
trova lo memorizza nella propria tabella (oltre, ovviamente, a restituirlo al
client che ne ha fatto richiesta).
In un regime in cui le operazioni di lettura sono preponderanti rispetto alle operazioni di update, questo porta a replicare tutte le entry su ogni server se i client effettuano ogni volta le letture su un server diverso, oppure se effettuano letture di ogni entry del sistema sempre sullo stesso server. Nel caso che le cose vadano così il comportamento tutto sommato è corretto (anche se un'eccessiva replicazione rende l'update più pesante - vedi il protocollo). Più realisticamente, i client tenderanno ad effettuare le richieste sempre sullo stesso server, creando quindi una "località" dei dati cachati.
Per ogni dato replicato esiste un proprietario, il quale conosce i server che hanno copiato quel dato (e quindi lo hanno in cache).
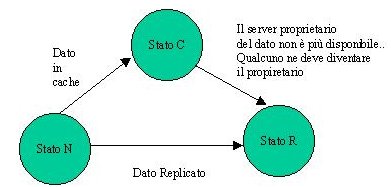
Ogni Entry ha quindi, localmente al server, uno stato:
|
R
|
Il dato è stato replicato e questo server ne è proprietario |
|
C
|
Il dato è stato copiato, ma questo server non ne è il proprietario |
|
N
|
Il dato non è mai stato replicato |
 |
Problemi dei Server:
Un server può disattivarsi, ma ipotizziamo che non possa riprendere l'attività in seguito, se non re-inizializzandosi completamente. La disattività temporanea di un server può portare ad inconsistenza dei dati.
Problemi di comunicazione:
- Sul lato client nessun problema (se il server non risponde, può rivolgersi ad un altro server, e se la comunicazione fra server funziona correttamente non ci sono problemi). In altre parole, il guasto è riconosciuto a livello utente, che però può utilizzare ancora il sistema (o semplicemente riprovare).
- Sul lato server, se il problema avviene durante la comunicazione in seguito ad una richiesta di lettura da parte di un client, al client può essere restituita la risposta "entry non trovata" (anche se l'entry è presente nella tabella globale).
Se invece il problema avviene durante il coordinamento in seguito ad una richiesta di update di un dato, questo può portare a inconsistenza dei dati.
Riassumendo le ipotesi sono:
1) In caso di disattivazione di un server, questa è definitiva.
2) Non avvengono problemi di comunicazione nelle fasi di coordinamento fra i server in caso di aggiornamento dei dati.
3) Non ci sono problemi di partizionamento di rete.