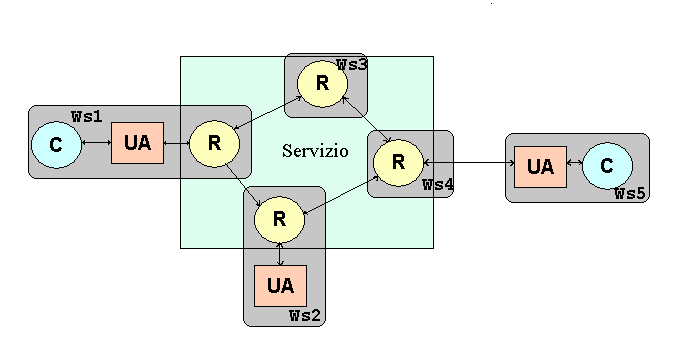
Il modello di architettura scelto per l'insieme delle repliche consiste in un anello virtuale, in cui tutte le repliche sono attive. La struttura ad anello viene utilizzata sia per la realizzazione del protocollo di identificazione e recovery del guasto, e per il protocollo di bilanciamento del carico.
La trasparenza alla replicazione viene realizzata tramite un modello di comunicazione cliente-servitore "evoluto": si inserisce tra cliente e servitore un'entità intermedia chiamata User-Agent (nei libri si può trovare anche con il nome di Front-End). Tutte le richieste dei clienti sono gestite da questo componente, il cui ruolo è comunicare con le repliche (tramite messaggi) al posto del cliente.
L'ipotesi fatta sull'UA è che sia locale al cliente (dove c'è un cliente deve essere già attivo l'UA). Si può sottolineare che se l'UA non fallisce, la semantica dalla risposta al cliente diventa at-most-once.
Organizzazione dei servizi offerti
In questo progetto viene preso in considerazione come obiettivo primario lo sviluppo di un modello di sistema replicato, ed è quindi stato volutamente trascurato l'aspetto che riguarda la possibilità di registrare e togliere i servizi offerti al cliente. Come esempio vengono forniti solo tre servizi, che sono:
Quest'ultimo fornisce un numero unico per tutti gli utenti del server replicato, ed è stato pensato come un possibile supporto alla generazione dei timestamps (sincronizzazione tra clienti).
Supporto per lo sviluppo del progetto
Il progetto è stato realizzato nel LAB2 sulle lia nuove, utilizzando Java. La scelta di Java (piuttosto che C) è stata fatta principalmente perché mette a disposizione il supporto al multithreading.
Comunicazione tra i componenti
La comunicazione tra le varie entità che partecipano alla realizzazione del servizio replicato avviene tramite un meccanismo a scambio di messaggi.
Il protocollo di comunicazione scelto per il livello di trasporto è UDP. Questa scelta è stata fatta considerato il fatto che i server sono in esecuzione su workstation appartenenti ad una stessa rete locale (lia nuove), con lo scopo di diminuire il più possibile l'overhead introdotto dalla comunicazione.
La scelta di questo protocollo che è unreliable ha condotto, nei casi in cui la comunicazione tra entità deve avvenire con un certo grado di affidabilità (es. scambio del token), alla realizzazione a livello applicativo di un protocollo "per l'affidabilità" sopra UDP tramite scambi di messaggi tra le entità coinvolte.