
Conclusioni
Sono state fatte delle prove sul servizio in questo modo: un cliente genera un numero finito di thread in parallelo, ognuno dei quali fa una richiesta di un servizio al sistema replicato tramite uno stesso UA (il cliente è locale all'UA). Lo stesso cliente crea prima e dopo l'esecuzione dei thread un oggetto Date (java.util), e calcola il tempo "di esecuzione" facendo la differenza (in millisecondi).
Occorre ricordare che queste prove non costituiscono un risultato generale per vedere le prestazioni, perché i risultati possono variare di molto in base a parametri come per esempio il numero di utenti sulla workstation , il traffico di rete sulla LAN, ecc.
Prove
Il cliente di prova è realizzato nel file Clienteparallelo.java. Per confrontare i risultati sono stati fatti eseguire tre servizi per ogni replica presente, su un anello composto da quattro, tre, due e una replica (i servizi richiesti sono solo quelli per cui non c'è bisogno del token). Inoltre il cliente, per fornire valori più "realistici" ripete questa sequenza di 12 servizi per trenta volte e alla fine stampa il valore medio. Poi, per vedere se ci fosse una sequenza particolare di creazione dei "thread di richiesta", il cliente è stato dotato della possibilità di eseguire lo start() dei thread ad intervalli di tempo specifici. Se non si inseriscono ritardi, le richieste hanno il "sopravvento" sulla messa in esecuzione per cui il meccanismo di load sharing non fa il suo dovere (le richieste vengono accolte tutte o quasi tutte da una sola replica). Il valore di ritardo da inserire per cui si è riscontrata una buona distribuzione dei servizi (è un riscontro molto "soggettivo", ma è dovuto al fatto che i tempi di esecuzione sono i minori) si aggira tra i 10 e i 30 millisecondi.
Il server, allo scopo di poter eseguire prove di questo tipo, è stato dotato delle possibilità di inserire un ritardo nel tempo di esecuzione dei servizi, e i ritardi inseriti variano da 0 a 500 millisecondi.
Il tempo medio di un servizio è stato calcolato eseguendo le richieste tutte localmente (Cliente, UA e Replica sono locali). La differenza che è pressoché costante fra ritardo inserito e tempo "rilevato" è imputabile al tempo impiegato dalla JVM per creare i thread "coinvolti" nell'esecuzione del singolo servizio (più o meno 50 millisecondi).
| 0 | 50 | 100 | 150 | 200 | 250 | 300 | 350 | 400 | 450 | 500 | |
| Tempo medio di un servizio | 56.66667 | 98.33333 | 148.3333 | 197.3333 | 248.6667 | 295.3333 | 337 | 393 | 438 | 491.3333 | 531.3333 |
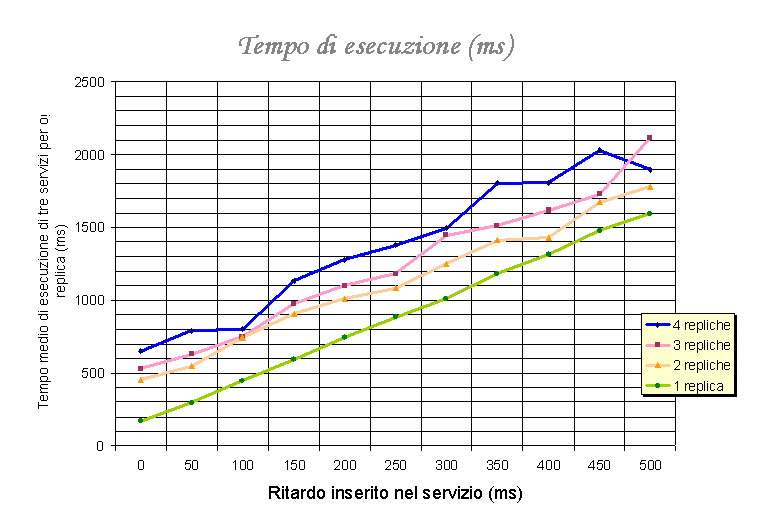
Il tempo di esecuzione è relativo all'esecuzione di tre servizi per ogni replica presente nell'anello (si è pensato ad una "densità di servizi per workstation" costante, visto che le workstation usate sono tutte uguali).
| 0 | 50 | 100 | 150 | 200 | 250 | 300 | 350 | 400 | 450 | 500 | |
| 4 repliche | 649 | 789 | 804 | 1135 | 1278 | 1377 | 1497 | 1805 | 1809 | 2028 | 1895 |
| 3 repliche | 530 | 627 | 750 | 975 | 1096 | 1181 | 1447 | 1509 | 1618 | 1729 | 2114 |
| 2 repliche | 455 | 544 | 744 | 907 | 1013 | 1083 | 1248 | 1413 | 1433 | 1676 | 1779 |
| 1 replica | 170 | 295 | 445 | 592 | 746 | 886 | 1011 | 1179 | 1314 | 1474 | 1594 |
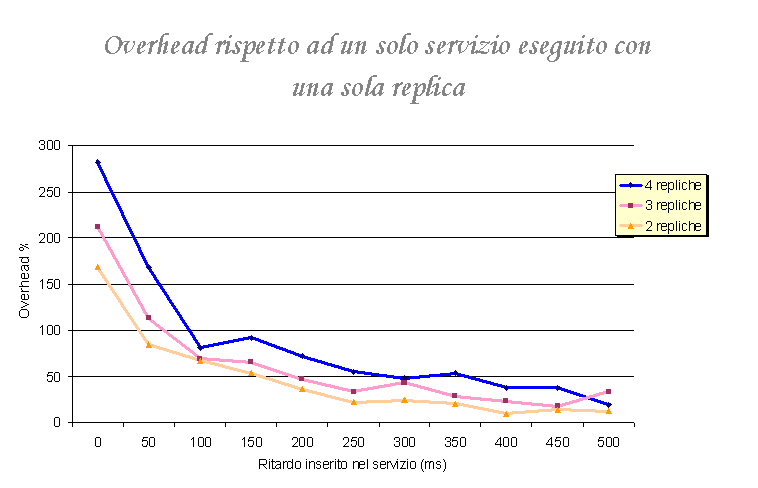
L'overhead è stato calcolato facendo riferimento al tempo medio di un servizio su un anello con una replica, quindi non è un overhead "canonico", per il quale si dovrebbe calcolare la durata del servizio realizzandolo come un unico thread nella JVM. La formula usata è:
Overhead%=((Tempo di esecuzione - Tempo di un servizio)*100)/(Tempo di un servizio)
NOTA: ho provato a realizzare un thread che esegue un servizio in questo modo, ed è risultato che il tempo impiegato è di 40 millisecondi in più del ritardo introdotto, invece dei 50 risultanti usando la replica.
| 0 | 50 | 100 | 150 | 200 | 250 | 300 | 350 | 400 | 450 | 500 | |
| 4 repliche | 281.7647 | 167.4576 | 80.67416 | 91.72297 | 71.31367 | 55.41761 | 48.07122 | 53.09584 | 37.67123 | 37.5848 | 18.88331 |
| 3 repliche | 211.7647 | 112.5424 | 68.53933 | 64.69595 | 46.91689 | 33.29571 | 43.12562 | 27.98982 | 23.13546 | 17.29986 | 32.62233 |
| 2 repliche | 167.6471 | 84.40678 | 67.19101 | 53.20946 | 35.79088 | 22.23476 | 23.44214 | 19.84733 | 9.056317 | 13.70421 | 11.60602 |
Problemi affrontati durante lo svolgimento del progetto
Il primo "ostacolo" incontrato è stato dover imparare il linguaggio Java da zero, poi riuscire a realizzare i meccanismi di sincronizzazione che servono: realizzare ricezioni con timeout (tutte realizzate tramite thread perché occorre gestire una eccezione), dover distinguere se un thread si sblocca in seguito al timeout o in seguito ad una notifica, realizzare meccanismi di sincronizzazione diversi dentro un unico oggetto da condividere.
Un altro ostacolo è stato riuscire a realizzare il protocollo di recovery e di gestione dell'anello (che interagiscono molto tra loro), e riuscire a trovare una politica di priorità tra i vari thread e sottothread generati dai vari gestori.
Posso affermare che è stato "vitale" per me avere un collegamento con il sito della Sun dedicato a Java (il Tutorial e il Forum) dove ho trovato spiegazioni, problemi risolti e non, che riguardano la gestione e la sincronizzazione dei thread, anche se non sono riuscito a trovare spiegazioni esaurienti o esempi sul funzionamento della wait con timeout (cfr. java.lang.Object.wait()). Ho dovuto fare tante prove per capire come funzione e come usarla.